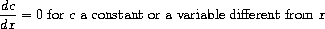
到目前为止,我们使用的所有复合数据对象最终都是由数构造的。在本节中,我们通过引入处理任意符号作为数据的能力,来扩展我们语言的表示能力。
(a b c d)
(23 45 17)
((Norah 12) (Molly 9) (Anna 7) (Lauren 6) (Charlotte 4))
包含符号的列表看起来就像我们语言中的表达式一样:
(* (+ 23 45) (+ x 9))
(define (fact n) (if (= n 1) 1 (* n (fact (- n 1)))))
为了处理符号,我们需要在语言中引入一个新的元素:引用数据对象的能力。假设我们要构造列表(a b)。我们不能用(list a b)来完成,因为这个表达式构造的是a和b的值的列表,而不是符号本身。这个问题在自然语言的语境中广为人知,其中单词和句子既可以被视为语义实体,也可以被视为字符串(语法实体)。自然语言中的常见做法是使用引号来指示一个单词或句子要按字面意思作为字符串处理。例如,"John"的第一个字母显然是"J"。如果我们告诉某人"大声说出你的名字",我们期望听到那个人的名字。然而,如果我们告诉某人"大声说出'你的名字'",我们期望听到"你的名字"这几个字。注意,我们不得不嵌套引号来描述别人可能说的话。32
我们可以遵循同样的做法来标识那些要作为数据对象而不是作为要求值的表达式的列表和符号。然而,我们的引用格式与自然语言不同,我们只在要引用的对象开头放置一个引号(传统上是单引号符号 ')。在Scheme语法中,我们可以这样做,因为我们依靠空格和括号来分隔对象。因此,单引号字符的含义是引用下一个对象。33
(define a 1)
(define b 2)
(list a b)
(1 2)
(list 'a 'b)
(a b)
(list 'a b)
(a 2)
引用也允许我们使用列表的传统打印表示来输入复合对象:34
(car '(a b c))
a
(cdr '(a b c))
(b c)
与此一致,我们可以通过求值'()来得到空列表,从而省去变量nil。
处理符号时使用的一个额外原语是eq?,它接受两个符号作为参数,测试它们是否相同。35使用eq?,我们可以实现一个有用的过程,称为memq。它接受两个参数,一个符号和一个列表。如果该符号不在列表中(即不与列表中的任何项eq?),则memq返回假。否则,它返回从该符号第一次出现开始的列表子列表:
(define (memq item x)
(cond ((null? x) false)
((eq? item (car x)) x)
(else (memq item (cdr x)))))
例如,
(memq 'apple '(pear banana prune))
的值为假,而
(memq 'apple '(x (apple sauce) y apple pear))
的值为(apple pear)。
(list 'a 'b 'c)
(list (list 'george))
(cdr '((x1 x2) (y1 y2)))
(cadr '((x1 x2) (y1 y2)))
(pair? (car '(a short list)))
(memq 'red '((red shoes) (blue socks)))
(memq 'red '(red shoes blue socks))
练习 2.54. 如果两个列表包含按相同顺序排列的相等元素,则称两个列表equal?。例如,
(equal? '(this is a list) '(this is a list))
为真,但
(equal? '(this is a list) '(this (is a) list))
为假。更精确地说,我们可以基于符号的基本eq?相等性递归地定义equal?:如果a和b都是符号且符号eq?,或者它们都是列表且(car a)与(car b)equal?且(cdr a)与(cdr b)equal?,则a和bequal?。利用这个思路,将equal?实现为一个过程。36
练习 2.55. Eva Lu Ator 向解释器输入表达式
(car ''abracadabra)
令她惊讶的是,解释器打印回quote。请解释原因。
作为符号处理的一个示例,以及数据抽象的进一步说明,考虑设计一个执行代数表达式符号求导的过程。我们希望该过程接受一个代数表达式和一个变量作为参数,并返回该表达式关于该变量的导数。例如,如果该过程的参数是ax2 + bx + c和x,则该过程应返回2ax + b。符号求导在Lisp中具有特殊的历史意义。它是推动开发用于符号处理的计算机语言的动机示例之一。此外,它标志着一系列研究的开始,这些研究导致了用于符号数学工作的强大系统的发展,目前这些系统正在被越来越多的应用数学家和物理学家使用。
在开发符号求导程序时,我们将遵循与开发2.1.1节的有理数系统相同的数据抽象策略。也就是说,我们将首先定义一个求导算法,该算法操作于诸如"和"、"积"和"变量"这样的抽象对象,而不必担心这些对象如何表示。只有在此之后,我们才会处理表示问题。
为简单起见,我们将考虑一个非常简单的符号求导程序,它处理仅使用加法和乘法两种运算构建的表达式。任何此类表达式的求导都可以通过应用以下归约规则来实现:
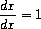
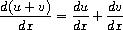
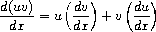
观察到后两条规则本质上是递归的。也就是说,要得到一个和的导数,我们首先找到各项的导数然后将它们相加。每一项本身又可能是需要分解的表达式。分解成越来越小的部分最终会产生常数或变量,它们的导数将是0或1。
为了将这些规则体现在一个过程中,我们进行了一些一厢情愿的思考,就像我们在设计有理数实现时所做的那样。如果我们有表示代数表达式的手段,我们应该能够判断一个表达式是和、积、常数还是变量。我们应该能够提取表达式的部分。例如,对于和,我们希望能够提取被加数(第一项)和加数(第二项)。我们还应该能够从部分构造表达式。让我们假设我们已经有了实现以下选择器、构造器和谓词的过程:
| (variable? e) | e 是变量吗? |
| (same-variable? v1 v2) | v1 和 v2 是同一个变量吗? |
(sum? e) | e 是和吗? |
| (addend e) | 和 e 的被加数。 |
| (augend e) | 和 e 的加数。 |
| (make-sum a1 a2) | 构造 a1 和 a2 的和。 |
(product? e) | e 是积吗? |
| (multiplier e) | 积 e 的乘数。 |
| (multiplicand e) | 积 e 的被乘数。 |
| (make-product m1 m2) | 构造 m1 和 m2 的积。 |
(define (deriv exp var)
(cond ((number? exp) 0)
((variable? exp)
(if (same-variable? exp var) 1 0))
((sum? exp)
(make-sum (deriv (addend exp) var)
(deriv (augend exp) var)))
((product? exp)
(make-sum
(make-product (multiplier exp)
(deriv (multiplicand exp) var))
(make-product (deriv (multiplier exp) var)
(multiplicand exp))))
(else
(error "unknown expression type -- DERIV" exp))))
这个deriv过程包含了完整的求导算法。由于它是用抽象数据表达的,只要我们设计了一组合适的选择器和构造器,无论我们选择如何表示代数表达式,它都能工作。这是我们接下来必须解决的问题。
我们可以想象许多使用列表结构来表示代数表达式的方法。例如,我们可以使用镜像通常代数记法的符号列表,将ax + b表示为列表(a * x + b)。然而,一个特别直接的选择是使用Lisp用于组合式的带括号的前缀记法;也就是说,将ax + b表示为(+ (* a x) b)。于是,求导问题的数据表示如下:
(define (variable? x) (symbol? x))
(define (same-variable? v1 v2)
(and (variable? v1) (variable? v2) (eq? v1 v2)))
(define (make-sum a1 a2) (list '+ a1 a2))
(define (make-product m1 m2) (list '* m1 m2))
(define (sum? x)
(and (pair? x) (eq? (car x) '+)))
(define (product? x)
(and (pair? x) (eq? (car x) '*)))
(define (multiplier p) (cadr p))
(define (multiplicand p) (caddr p))
因此,我们只需要将这些与deriv所体现的算法结合起来,就能得到一个可工作的符号求导程序。让我们来看一些其行为的例子:
(deriv '(+ x 3) 'x)
(+ 1 0)
(deriv '(* x y) 'x)
(+ (* x 0) (* 1 y))
(deriv '(* (* x y) (+ x 3)) 'x)
(+ (* (* x y) (+ 1 0))
(* (+ (* x 0) (* 1 y))
(+ x 3)))
该程序产生的答案是正确的;然而,它们没有被简化。
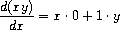
但我们希望程序知道x · 0 = 0,1 · y = y,以及0 + y = y。第二个例子的答案应该是简单的 y。正如第三个例子所示,当表达式复杂时,这成了一个严重的问题。
我们的困难与我们在有理数实现中遇到的非常相似:我们没有将答案化简到最简单的形式。为了实现有理数的化简,我们只需要更改实现的构造器和选择器。我们可以在这里采用类似的策略。我们根本不会更改deriv。相反,我们将更改make-sum,使得如果两个加数都是数,make-sum会将它们相加并返回它们的和。此外,如果其中一个加数为0,则make-sum将返回另一个加数。
(define (make-sum a1 a2)
(cond ((=number? a1 0) a2)
((=number? a2 0) a1)
((and (number? a1) (number? a2)) (+ a1 a2))
(else (list '+ a1 a2))))
这里使用了过程=number?,它检查一个表达式是否等于给定的数:
(define (=number? exp num)
(and (number? exp) (= exp num)))
类似地,我们将更改make-product,内置0乘以任何东西都是0,1乘以任何东西就是该东西本身的规则:
(define (make-product m1 m2)
(cond ((or (=number? m1 0) (=number? m2 0)) 0)
((=number? m1 1) m2)
((=number? m2 1) m1)
((and (number? m1) (number? m2)) (* m1 m2))
(else (list '* m1 m2))))
以下是这个版本在三个例子上的工作情况:
(deriv '(+ x 3) 'x)
1
(deriv '(* x y) 'x)
y
(deriv '(* (* x y) (+ x 3)) 'x)
(+ (* x y) (* y (+ x 3)))
虽然这是一个相当大的改进,但第三个例子表明,要得到一个我们可能认为"最简"形式的表达式,还有很长的路要走。代数化简问题很复杂,因为除其他原因外,对于一个目的可能最简单的形式对于另一个目的可能不是。
练习 2.56. 展示如何扩展基本求导器以处理更多种类的表达式。例如,通过向deriv程序添加一个新子句并定义适当的过程exponentiation?、base、exponent和make-exponentiation,实现求导规则
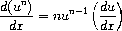
(你可以使用符号**来表示乘幂。)内置规则:任何数的0次幂为1,任何数的1次幂为其本身。
练习 2.57. 扩展求导程序以处理任意数量(两个或更多)项的和与积。这样,上面的最后一个例子可以表示为
(deriv '(* x y (+ x 3)) 'x)
尝试仅通过更改和与积的表示来实现这一点,完全不更改deriv过程。例如,和的addend将是第一项,而augend将是其余项的和。
练习 2.58. 假设我们要修改求导程序,使其能处理普通的数学记法,其中+和*是中缀而非前缀运算符。由于求导程序是用抽象数据定义的,我们可以仅通过更改定义求导器要操作的代数表达式表示的谓词、选择器和构造器,来修改它以处理不同的表示形式。
a. 展示如何做到这一点,以便对以中缀形式呈现的代数表达式求导,例如(x + (3 * (x + (y + 2))))。为简化任务,假设+和*总是接受两个参数,且表达式完全用括号括起来。
b. 如果我们允许标准的代数记法,例如(x + 3 * (x + y + 2)),它省略了不必要的括号并假定乘法优先于加法,问题就变得困难得多。你能为这种记法设计适当的谓词、选择器和构造器,使得我们的求导程序仍然能工作吗?
在前面的例子中,我们为两种复合数据对象构建了表示:有理数和代数表达式。在其中一个例子中,我们选择了在构造时或选择时简化表达式,但除此之外,用列表表示这些结构的选择是直接的。当我们转向集合的表示时,表示的选择就不那么明显了。实际上,有许多可能的表示,它们在几个方面彼此显著不同。
非正式地说,集合就是不同对象的汇集。为了给出更精确的定义,我们可以采用数据抽象的方法。也就是说,我们通过指定要在集合上使用的操作来定义"集合"。这些操作是union-set、intersection-set、element-of-set?和adjoin-set。Element-of-set?是一个谓词,确定给定元素是否是集合的成员。Adjoin-set接受一个对象和一个集合作为参数,返回一个包含原始集合元素以及要加入的元素的集合。Union-set计算两个集合的并集,即包含出现在任一参数中的每个元素的集合。Intersection-set计算两个集合的交集,即仅包含出现在两个参数中的元素的集合。从数据抽象的角度来看,我们可以自由地设计任何表示,只要它以与上述解释一致的方式实现这些操作。37
表示集合的一种方法是将其表示为一个元素列表,其中每个元素最多出现一次。空集由空列表表示。在这种表示中,element-of-set?类似于2.3.1节的过程memq。它使用equal?而不是eq?,这样集合元素不必是符号:
(define (element-of-set? x set)
(cond ((null? set) false)
((equal? x (car set)) true)
(else (element-of-set? x (cdr set)))))
使用这个,我们可以编写adjoin-set。如果要加入的对象已经在集合中,我们只需返回该集合。否则,我们使用cons将对象添加到表示集合的列表中:
(define (adjoin-set x set)
(if (element-of-set? x set)
set
(cons x set)))
对于intersection-set,我们可以使用递归策略。如果我们知道如何形成set2和set1的cdr的交集,我们只需要决定是否将set1的car包含在该交集中。但这取决于(car set1)是否也在set2中。以下是得到的过程:
(define (intersection-set set1 set2)
(cond ((or (null? set1) (null? set2)) '())
((element-of-set? (car set1) set2)
(cons (car set1)
(intersection-set (cdr set1) set2)))
(else (intersection-set (cdr set1) set2))))
在设计表示时,我们应该关注的问题之一是效率。考虑我们集合操作所需的步数。由于它们都使用element-of-set?,这个操作的速度对整个集合实现的效率有重大影响。现在,为了检查一个对象是否是集合的成员,element-of-set?可能需要扫描整个集合(在最坏的情况下,该对象不在集合中)。因此,如果集合有n个元素,element-of-set?可能需要多达n步。因此,所需的步数按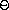 (n)增长。使用此操作的adjoin-set所需的步数也按(n)增长。对于intersection-set,它对set1的每个元素执行一次element-of-set?检查,所需的步数按所涉及集合大小的乘积增长,即对于两个大小为n的集合为(n2)。union-set也是如此。
(n)增长。使用此操作的adjoin-set所需的步数也按(n)增长。对于intersection-set,它对set1的每个元素执行一次element-of-set?检查,所需的步数按所涉及集合大小的乘积增长,即对于两个大小为n的集合为(n2)。union-set也是如此。
练习 2.59. 为集合的无序列表表示实现union-set操作。
练习 2.60. 我们指定集合将被表示为没有重复的列表。现在假设我们允许重复。例如,集合{1,2,3}可以被表示为列表(2 3 2 1 3 2 2)。设计在此表示上操作的过程element-of-set?、adjoin-set、union-set和intersection-set。每个过程的效率与无重复表示的相应过程相比如何?是否存在你会优先使用这种表示而非无重复表示的应用?
加速我们集合操作的一种方法是改变表示,使集合元素按递增顺序排列。为此,我们需要某种方式来比较两个对象,以便我们可以说哪个更大。例如,我们可以按字典序比较符号,或者我们可以约定某种方法为对象分配唯一编号,然后通过比较相应的编号来比较元素。为保持讨论简单,我们只考虑集合元素为数的情况,这样我们可以使用>和<来比较元素。我们将通过将其元素按递增顺序列出来表示一个数的集合。而我们上面的第一个表示允许我们以任意顺序列出元素来表示集合{1,3,6,10},我们的新表示只允许列表(1 3 6 10)。
排序的一个优势体现在element-of-set?中:在检查某个项是否存在时,我们不再需要扫描整个集合。如果我们遇到一个大于正在查找的项的集合元素,那么我们就会知道该项不在集合中:
(define (element-of-set? x set)
(cond ((null? set) false)
((= x (car set)) true)
((< x (car set)) false)
(else (element-of-set? x (cdr set)))))
这节省了多少步数?在最坏的情况下,我们要找的项可能是集合中最大的,所以步数与无序表示相同。另一方面,如果我们搜索许多不同大小的项,我们可以预期有时能够在列表开头附近停止搜索,而其他时候仍然需要检查大部分列表。平均而言,我们期望需要检查大约一半的集合项。因此,平均所需的步数大约为n/2。这仍然是(n)增长,但与之前的实现相比,平均确实节省了2倍的步数。
我们通过intersection-set获得了更令人印象深刻的加速。在无序表示中,此操作需要(n2)步,因为我们对set1的每个元素执行了一次完整的set2扫描。但使用有序表示,我们可以采用更巧妙的方法。首先比较两个集合的初始元素x1和x2。如果x1等于x2,则得到交集的一个元素,交集的其余部分是这两个集合的cdr的交集。然而,假设x1小于x2。由于x2是set2中的最小元素,我们可以立即得出结论,x1不可能出现在set2中的任何位置,因此不在交集中。因此,交集等于set2与set1的cdr的交集。类似地,如果x2小于x1,则交集由set1与set2的cdr的交集给出。以下是该过程:
(define (intersection-set set1 set2)
(if (or (null? set1) (null? set2))
'()
(let ((x1 (car set1)) (x2 (car set2)))
(cond ((= x1 x2)
(cons x1
(intersection-set (cdr set1)
(cdr set2))))
((< x1 x2)
(intersection-set (cdr set1) set2))
((< x2 x1)
(intersection-set set1 (cdr set2)))))))
要估计此过程所需的步数,注意到每一步我们都会将交集问题简化为计算更小集合的交集——从set1或set2或两者中移除第一个元素。因此,所需的步数最多为set1和set2大小之和,而不是像无序表示那样为大小的乘积。这是(n)增长而不是(n2)——即使是中等大小的集合,也是一个相当大的加速。
练习 2.61. 使用有序表示给出adjoin-set的实现。通过与element-of-set?类比,展示如何利用排序来产生一个平均所需步数约为无序表示一半的过程。
练习 2.62. 对于表示为有序列表的集合,给出一个(n)实现的union-set。
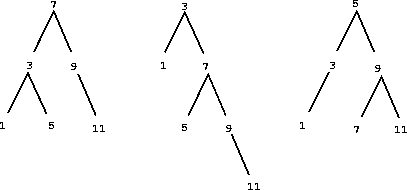
我们可以做得比有序列表表示更好,通过将集合元素排列成树的形式。树的每个节点保存集合的一个元素,称为该节点的"项",以及指向其他两个(可能为空)节点的链接。"左"链接指向小于该节点元素的元素,"右"链接指向大于该节点元素的元素。图2.16显示了一些表示集合{1,3,5,7,9,11}的树。同一个集合可以用多种不同方式的树来表示。我们对有效表示的唯一要求是,左子树中的所有元素都小于节点项,右子树中的所有元素都大于节点项。
|
树表示的优势在于:假设我们要检查一个数x是否包含在集合中。我们首先将x与顶层节点的项进行比较。如果x小于它,我们知道只需搜索左子树;如果x大于它,只需搜索右子树。现在,如果树是"平衡的",那么这些子树中的每一个都约为原树大小的一半。因此,一步之内,我们就把搜索大小为n的树的问题简化为搜索大小为n/2的树。由于树的大小每一步减半,我们可以预期搜索大小为n的树所需的步数按(log n)增长。38对于大集合,这将是比之前表示显著加速。
我们可以使用列表来表示树。每个节点将是三个项的列表:该节点的项、左子树和右子树。左或右子树的空列表表示该处没有连接子树。我们可以通过以下过程来描述这种表示:39
(define (entry tree) (car tree))
(define (left-branch tree) (cadr tree))
(define (right-branch tree) (caddr tree))
(define (make-tree entry left right)
(list entry left right))
现在我们可以使用上述策略编写element-of-set?过程:
(define (element-of-set? x set)
(cond ((null? set) false)
((= x (entry set)) true)
((< x (entry set))
(element-of-set? x (left-branch set)))
((> x (entry set))
(element-of-set? x (right-branch set)))))
向集合加入一个项的实现类似,也只需要(log n)步。要加入一个项x,我们将x与节点项比较,以确定x应该添加到右分支还是左分支,然后将x加入适当的分支后,将新构造的分支与原始项和另一分支拼接在一起。如果x等于该节点项,我们只需返回该节点。如果要求我们将x加入一棵空树,我们生成一棵以x为项、左右分支均为空的树。以下是该过程:
(define (adjoin-set x set)
(cond ((null? set) (make-tree x '() '()))
((= x (entry set)) set)
((< x (entry set))
(make-tree (entry set)
(adjoin-set x (left-branch set))
(right-branch set)))
((> x (entry set))
(make-tree (entry set)
(left-branch set)
(adjoin-set x (right-branch set))))))
上述关于搜索树可以在对数步数内完成的说法依赖于树是"平衡的"假设,即每棵树的左子树和右子树具有大致相同数量的元素,因此每个子树包含其父节点大约一半的元素。但我们如何能确定我们构造的树会是平衡的呢?即使我们以平衡树开始,使用adjoin-set添加元素可能会导致不平衡的结果。由于新加入元素的位置取决于该元素与集合中已有项的比较方式,我们可以预期如果"随机地"添加元素,树平均会趋于平衡。但这并非保证。例如,如果我们从一个空集开始,按顺序加入数字1到7,我们最终会得到如图2.17所示的极度不平衡的树。在这棵树中,所有的左子树都是空的,所以它比简单的有序列表没有任何优势。解决这个问题的一种方法是定义一个操作,将任意树转换为具有相同元素的平衡树。然后我们可以在每几次adjoin-set操作后执行这个转换,以保持集合的平衡。还有其他解决这个问题的方法,其中大多数涉及设计新的数据结构,使搜索和插入都能在(log n)步内完成。40
|
(define (tree->list-1 tree)
(if (null? tree)
'()
(append (tree->list-1 (left-branch tree))
(cons (entry tree)
(tree->list-1 (right-branch tree))))))
(define (tree->list-2 tree)
(define (copy-to-list tree result-list)
(if (null? tree)
result-list
(copy-to-list (left-branch tree)
(cons (entry tree)
(copy-to-list (right-branch tree)
result-list)))))
(copy-to-list tree '()))
a. 这两个过程对每棵树产生的结果相同吗?如果不相同,结果有什么不同?这两个过程对图2.16中的树产生什么列表?
b. 在将包含n个元素的平衡树转换为列表所需的步数上,这两个过程有相同的增长阶吗?如果不是,哪个增长得更慢?
练习 2.64. 以下过程list->tree将一个有序列表转换为平衡二叉树。辅助过程partial-tree接受一个整数n和一个至少包含n个元素的列表作为参数,构造一个包含列表前n个元素的平衡树。partial-tree返回的结果是一个序对(用cons构成),其car是构造的树,cdr是未包含在树中的元素列表。
(define (list->tree elements)
(car (partial-tree elements (length elements))))
(define (partial-tree elts n)
(if (= n 0)
(cons '() elts)
(let ((left-size (quotient (- n 1) 2)))
(let ((left-result (partial-tree elts left-size)))
(let ((left-tree (car left-result))
(non-left-elts (cdr left-result))
(right-size (- n (+ left-size 1))))
(let ((this-entry (car non-left-elts))
(right-result (partial-tree (cdr non-left-elts)
right-size)))
(let ((right-tree (car right-result))
(remaining-elts (cdr right-result)))
(cons (make-tree this-entry left-tree right-tree)
remaining-elts))))))))
a. 写一小段文字,尽可能清晰地解释partial-tree是如何工作的。画出list->tree对列表(1 3 5 7 9 11)产生的树。
b. list->tree将包含n个元素的列表转换所需的步数的增长阶是什么?
练习 2.65. 利用练习2.63和2.64的结果,为实现为(平衡)二叉树的集合给出(n)实现的union-set和intersection-set。41
我们已经考察了使用列表表示集合的各种选择,并看到了数据对象的表示选择如何对使用该数据的程序性能产生重大影响。专注于集合的另一个原因是,这里讨论的技术在涉及信息检索的应用中反复出现。
考虑一个包含大量单独记录的数据集,例如公司的人事档案或会计系统中的事务。典型的数据管理系统花费大量时间访问或修改记录中的数据,因此需要一种高效的记录访问方法。这是通过标识每条记录的一部分作为标识键来实现的。键可以是任何唯一标识该记录的东西。对于人事档案,它可能是员工的ID号。对于会计系统,它可能是事务编号。无论键是什么,当我们把记录定义为数据结构时,应该包含一个检索给定记录关联键的key选择器过程。
现在我们将数据集表示为记录的集合。要定位具有给定键的记录,我们使用一个过程lookup,它接受一个键和一个数据集作为参数,返回具有该键的记录,如果没有这样的记录则返回假。Lookup的实现方式几乎与element-of-set?相同。例如,如果记录集合实现为无序列表,我们可以使用
(define (lookup given-key set-of-records)
(cond ((null? set-of-records) false)
((equal? given-key (key (car set-of-records)))
(car set-of-records))
(else (lookup given-key (cdr set-of-records)))))
当然,有比无序列表更好的表示大集合的方法。记录需要"随机访问"的信息检索系统通常通过基于树的方法来实现,例如前面讨论的二叉树表示。在设计这样的系统时,数据抽象方法论可以有很大的帮助。设计者可以使用简单直接的表示(如无序列表)创建初始实现。这对于最终系统来说是不合适的,但可用于提供一个"快速而粗糙"的数据集来测试系统的其余部分。稍后,数据表示可以被修改为更复杂的实现。如果数据集是通过抽象的选择器和构造器访问的,这种表示的更改将不需要对系统的其余部分做任何修改。
练习 2.66. 为记录集合结构化为二叉树(按键的数值排序)的情况实现lookup过程。
本节提供使用列表结构和数据抽象来操作集合和树的实践。该应用涉及将数据表示为0和1序列(位)的方法。例如,计算机中用于表示文本的ASCII标准代码将每个字符编码为七位序列。使用七位可以区分27即128种可能的字符。一般来说,如果我们要区分n个不同的符号,每个符号需要使用log2 n位。如果我们所有的消息都由八个符号A、B、C、D、E、F、G和H组成,我们可以选择每个字符三位的编码,例如
| A 000 | C 010 | E 100 | G 110 |
| B 001 | D 011 | F 101 | H 111 |
BACADAEAFABBAAAGAH
被编码为54位的字符串
001000010000011000100000101000001001000000000110000111
像ASCII和上面的A到H编码这样的编码被称为定长编码,因为它们用相同数量的位表示消息中的每个符号。使用变长编码有时是有利的,其中不同的符号可以用不同数量的位来表示。例如,莫尔斯电码对字母表中的每个字母不使用相同数量的点和划。特别是,最频繁出现的字母E用单个点表示。一般来说,如果我们的消息中某些符号频繁出现而某些很少出现,我们可以通过为频繁符号分配更短的编码来更有效地编码数据(即每条消息使用更少的位)。考虑以下针对字母A到H的替代编码:
| A 0 | C 1010 | E 1100 | G 1110 |
| B 100 | D 1011 | F 1101 | H 1111 |
100010100101101100011010100100000111001111
这个字符串包含42位,因此与上面所示的定长编码相比,节省了超过20%的空间。
使用变长编码的困难之一是在读取0和1序列时,如何知道何时到达了一个符号的末尾。莫尔斯电码通过在每个字母的点划序列后使用一个特殊的分隔码(在这种情况下是一个停顿)来解决这个问题。另一种解决方案是以这样一种方式设计编码,使得没有任何符号的完整编码是另一个符号编码的开头(或前缀)。这样的编码称为前缀码。在上面的例子中,A被编码为0,B被编码为100,因此没有其他符号的编码可以以0或100开头。
一般来说,如果我们使用变长前缀码,利用要编码消息中符号的相对频率,我们可以实现显著的节省。一种特别的方案称为霍夫曼编码方法,以其发现者David Huffman命名。霍夫曼码可以表示为一个二叉树,其叶子是待编码的符号。在树的每个非叶子节点处,有一个包含该节点以下叶子中所有符号的集合。此外,每个叶子处的符号被赋予一个权重(即其相对频率),每个非叶子节点包含一个权重,即其以下所有叶子权重的总和。权重不用于编码或解码过程。我们将在下面看到它们如何用于帮助构造树。
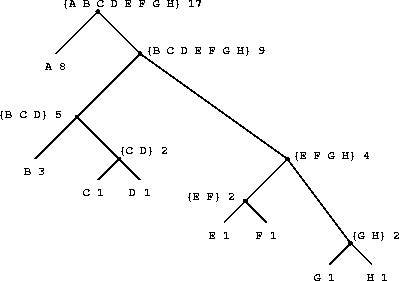
|
图2.18显示了对上述A到H编码的霍夫曼树。叶子处的权重表明,该树是为A的相对频率为8、B的相对频率为3、其他字母各为1的消息而设计的。
给定一棵霍夫曼树,我们可以通过从根开始向下移动直到到达包含该符号的叶子来找到任何符号的编码。每次我们沿左分支向下移动时,我们在编码中添加一个0,每次沿右分支向下移动时,添加一个1。(我们通过测试哪个分支是符号的叶子节点或在其集合中包含该符号来决定跟随哪个分支。)例如,从图2.18中树的根开始,我们通过依次沿右分支、左分支、右分支、右分支到达D的叶子;因此,D的编码是1011。
要使用霍夫曼树解码一个位序列,我们从根开始,使用位序列中的连续0和1来决定是向左还是向右移动。每次到达一个叶子时,我们就生成了消息中的一个新符号,此时我们从树的根重新开始寻找下一个符号。例如,假设我们有上面的树和序列10001010。从根开始,我们沿右分支向下(因为字符串的第一位是1),然后沿左分支向下(因为第二位是0),然后沿左分支向下(因为第三位也是0)。这会将我们带到B的叶子,因此解码消息的第一个符号是B。现在我们再次从根开始,因为字符串中的下一位是0,我们向左移动。这将我们带到A的叶子。然后我们用剩下的字符串1010再次从根开始,所以我们向右、向左、向右、向左移动并到达C。因此,整个消息是BAC。
给定一个符号的"字母表"及其相对频率,我们如何构造"最佳"编码?换句话说,哪棵树会用最少的位编码消息?Huffman给出了一种算法,并证明了得到的码确实是最好的变长编码,前提是消息中符号的相对频率与构建编码时使用的频率相匹配。我们在此不证明霍夫曼编码的最优性,但我们将展示霍夫曼树是如何构造的。42
生成霍夫曼树的算法非常简单。其思想是安排树的结构,使得频率最低的符号出现在距根最远的位置。从叶子节点集开始,包含符号及其频率,由最初构建编码的数据确定。现在找到两个权重最低的叶子,并将它们合并,生成一个以这两个节点作为左右分支的节点。新节点的权重是两个权重的和。从原始集合中移除这两个叶子,并用这个新节点替换它们。现在继续这个过程。每一步,合并两个权重最小的节点,将它们从集合中移除,并用以这两者为左右分支的节点替换它们。当只剩下一个节点时,过程停止,这个节点就是整棵树的根。以下是图2.18的霍夫曼树的生成过程:
| 初始叶子 | {(A 8) (B 3) (C 1) (D 1) (E 1) (F 1) (G 1) (H 1)} |
合并 | {(A 8) (B 3) ({C D} 2) (E 1) (F 1) (G 1) (H 1)} |
合并 | {(A 8) (B 3) ({C D} 2) ({E F} 2) (G 1) (H 1)} |
合并 | {(A 8) (B 3) ({C D} 2) ({E F} 2) ({G H} 2)} |
合并 | {(A 8) (B 3) ({C D} 2) ({E F G H} 4)} |
合并 | {(A 8) ({B C D} 5) ({E F G H} 4)} |
合并 | {(A 8) ({B C D E F G H} 9)} |
最终合并 | {({A B C D E F G H} 17)} |
在下面的练习中,我们将使用一个使用霍夫曼树编码和解码消息,并根据上述算法生成霍夫曼树的系统。我们将首先讨论树是如何表示的。
树的叶子由一个包含符号leaf、叶子处的符号和权重的列表表示:
(define (make-leaf symbol weight)
(list 'leaf symbol weight))
(define (leaf? object)
(eq? (car object) 'leaf))
(define (symbol-leaf x) (cadr x))
(define (weight-leaf x) (caddr x))
一般的树将是左分支、右分支、符号集和权重的列表。符号集将简单地是符号的列表,而不是某种更复杂的集合表示。当我们通过合并两个节点构造一棵树时,我们得到树的权重为节点权重的和,符号集为节点符号集的并集。由于我们的符号集被表示为列表,我们可以使用我们在2.2.1节中定义的append过程来形成并集:
(define (make-code-tree left right)
(list left
right
(append (symbols left) (symbols right))
(+ (weight left) (weight right))))
如果我们以这种方式构造树,我们有以下选择器:
(define (left-branch tree) (car tree))
(define (right-branch tree) (cadr tree))
(define (symbols tree)
(if (leaf? tree)
(list (symbol-leaf tree))
(caddr tree)))
(define (weight tree)
(if (leaf? tree)
(weight-leaf tree)
(cadddr tree)))
过程symbols和weight在被叶子或一般树调用时需要做一些略有不同的事情。这些是通用过程(可以处理多种数据的程序)的简单例子,我们将在2.4节和2.5节中详细讨论。
以下过程实现了解码算法。它接受一个0和1的列表以及一个霍夫曼树作为参数。
(define (decode bits tree)
(define (decode-1 bits current-branch)
(if (null? bits)
'()
(let ((next-branch
(choose-branch (car bits) current-branch)))
(if (leaf? next-branch)
(cons (symbol-leaf next-branch)
(decode-1 (cdr bits) tree))
(decode-1 (cdr bits) next-branch)))))
(decode-1 bits tree))
(define (choose-branch bit branch)
(cond ((= bit 0) (left-branch branch))
((= bit 1) (right-branch branch))
(else (error "bad bit -- CHOOSE-BRANCH" bit))))
过程decode-1接受两个参数:剩余位的列表和树中的当前位置。它持续在树中"向下"移动,根据列表中的下一位是0还是1选择左分支或右分支(这是通过过程choose-branch完成的)。当它到达一个叶子时,它将该叶子处的符号作为消息中的下一个符号返回,通过cons将其连接到从根开始解码消息剩余部分的结果上。注意choose-branch最后子句中的错误检查,如果过程在输入数据中发现不是0或1的东西,它会报错。
在我们的树表示中,每个非叶子节点包含一个符号集,我们将其表示为简单列表。然而,上面讨论的树生成算法要求我们还处理叶子和树的集合,依次合并两个最小的项。由于我们需要重复地找到集合中的最小项,因此对此类集合使用有序表示很方便。
我们将叶子和树的集合表示为元素列表,按权重递增顺序排列。以下用于构造集合的adjoin-set过程与练习2.61中描述的类似;然而,项是通过它们的权重进行比较的,并且要添加到集合中的元素从不在其中。
(define (adjoin-set x set)
(cond ((null? set) (list x))
((< (weight x) (weight (car set))) (cons x set))
(else (cons (car set)
(adjoin-set x (cdr set))))))
以下过程接受一个符号-频率对列表,例如((A 4) (B 2) (C 1) (D 1)),并构造一个初始的有序叶子集合,准备根据霍夫曼算法进行合并:
(define (make-leaf-set pairs)
(if (null? pairs)
'()
(let ((pair (car pairs)))
(adjoin-set (make-leaf (car pair) ; 符号
(cadr pair)) ; 频率
(make-leaf-set (cdr pairs))))))
(define sample-tree
(make-code-tree (make-leaf 'A 4)
(make-code-tree
(make-leaf 'B 2)
(make-code-tree (make-leaf 'D 1)
(make-leaf 'C 1)))))
(define sample-message '(0 1 1 0 0 1 0 1 0 1 1 1 0))
使用decode过程解码该消息,并给出结果。
练习 2.68. encode过程接受一个消息和一棵树作为参数,并产生给出编码消息的位列表。
(define (encode message tree)
(if (null? message)
'()
(append (encode-symbol (car message) tree)
(encode (cdr message) tree))))
Encode-symbol是你必须编写的过程,它根据给定的树返回对给定符号进行编码的位列表。你应该设计encode-symbol,使得如果符号根本不在树中,它会报错。通过使用示例树对练习2.67中获得的结果进行编码,并检查它是否与原始示例消息相同,来测试你的过程。
练习 2.69. 以下过程接受一个符号-频率对列表(其中没有符号出现在多个对中)作为参数,并根据霍夫曼算法生成一个霍夫曼编码树。
(define (generate-huffman-tree pairs)
(successive-merge (make-leaf-set pairs)))
Make-leaf-set是上面给出的将成对列表转换为有序叶子集合的过程。Successive-merge是你必须编写的过程,使用make-code-tree依次合并集合中权重最小的元素,直到只剩下一个元素,这就是所需的霍夫曼树。(这个过程有点棘手,但并不真正复杂。如果你发现自己设计了一个复杂的过程,那么你几乎肯定做错了什么。你可以充分利用我们使用有序集合表示这一事实。)
练习 2.70. 以下八个符号的字母表及其关联的相对频率是为有效编码1950年代摇滚歌曲的歌词而设计的。(注意,"字母表"的"符号"不必是单个字母。)
| A | 2 | NA | 16 |
| BOOM | 1 | SHA | 3 |
| GET | 2 | YIP | 9 |
| JOB | 2 | WAH | 1 |
Get a job
Sha na na na na na na na na
Get a job
Sha na na na na na na na na
Wah yip yip yip yip yip yip yip yip yip
Sha boom
编码需要多少位?如果对这个八符号字母表使用定长编码,需要多少位才能编码这首歌?
练习 2.71. 假设我们有一个包含n个符号的字母表的霍夫曼树,符号的相对频率是1, 2, 4, ..., 2n-1。画出n=5时的树;n=10时的树。在这样的树中(对一般的n),编码最频繁的符号需要多少位?编码最不频繁的符号呢?
练习 2.72. 考虑你在练习2.68中设计的编码过程。编码一个符号所需的步数的增长阶是多少?一定要包括在每个遇到的节点搜索符号列表所需的步数。要一般性地回答这个问题是困难的。考虑n个符号的相对频率如练习2.71中所述的特殊情况,并给出编码字母表中出现最频繁和最不频繁符号所需的步数的增长阶(作为n的函数)。
32 在语言中允许引用会严重破坏用简单术语推理语言的能力,因为它破坏了等号可以替换等号的概念。例如,3等于1加2,但单词"three"不是短语"one plus two"。引用之所以强大,是因为它为我们提供了一种构建操作其他表达式的表达式的方式(正如我们在第4章编写解释器时将看到的)。但是允许语言中的语句谈论同一语言中的其他语句,使得维持"等号可以替换等号"的任何连贯原则变得非常困难。例如,如果我们知道长庚星就是启明星,那么从"长庚星是金星"我们可以推断"启明星是金星"。然而,已知"John知道长庚星是金星",我们不能推断"John知道启明星是金星"。
33 单引号不同于我们一直用来括起要打印的字符串的双引号。单引号可用于表示列表或符号,而双引号仅用于字符串。在本书中,字符串的唯一用途是作为要打印的项目。
34 严格来说,我们使用引号违反了所有复合表达式应由括号分隔且看起来像列表的一般规则。我们可以通过引入特殊形式quote来恢复一致性,它服务于与引号相同的目的。因此,我们会输入(quote a)而不是'a,输入(quote (a b c))而不是'(a b c)。这正是解释器的工作方式。引号只是一个单字符缩写,用于将下一个完整表达式用quote包裹,形成(quote <表达式>)。这很重要,因为它维护了解释器所见任何表达式都可以作为数据对象来操作的原则。例如,我们可以通过求值(list 'car (list 'quote '(a b c)))来构造表达式(car '(a b c)),这与(car (quote (a b c)))相同。
35 我们可以认为如果两个符号由相同顺序的相同字符组成,则它们是"相同"的。这样的定义回避了一个我们尚未准备好解决的深层问题:编程语言中"相同"的含义。我们将在第3章(3.1.3节)回到这个问题。
36 在实践中,程序员使用equal?来比较包含数字和符号的列表。数不被视为符号。两个数值相等的数(由=测试)是否也是eq?的问题高度依赖于实现。equal?的一个更好的定义(例如Scheme中作为原语提供的那个)还会规定,如果a和b都是数,那么当它们数值相等时a和b是equal?。
37 如果我们想要更正式,我们可以指定"与上述解释一致"意味着操作满足一组规则,例如:
38 每一步将问题规模减半是对数增长的区别特征,正如我们在1.2.4节的快速幂算法和1.3.3节的半区间搜索方法中看到的那样。
39 我们是用树来表示集合,用列表来表示树——实际上,是一个建立在另一个数据抽象之上的数据抽象。我们可以将过程entry、left-branch、right-branch和make-tree视为将"二叉树"的抽象与我们可能希望用列表结构表示这种树的特定方式隔离开来。
40 此类结构的例子包括B树和红黑树。关于这个问题的数据结构有大量文献。参见Cormen、Leiserson和Rivest 1990。
41 练习2.63-2.65 由Paul Hilfinger提供。
42 关于霍夫曼编码的数学性质的讨论,参见Hamming 1980。