|
在上一节中,我们看到了如何设计系统,使得数据对象可以用多种方式表示。关键思想是通过通用接口过程将指定数据操作的代码与多种表示联系起来。现在我们将看到如何使用同样的思想,不仅定义在不同表示上通用的操作,还能定义在不同类型的参数上通用的操作。我们已经看到几种不同的算术运算包:语言内置的原始算术(+、-、*、/)、第2.1.1节的有理数算术(add-rat、sub-rat、mul-rat、div-rat),以及我们在第2.4.3节实现的复数算术。现在我们将使用数据导向技术来构造一个算术运算包,它将我们已构造的所有算术包整合在一起。
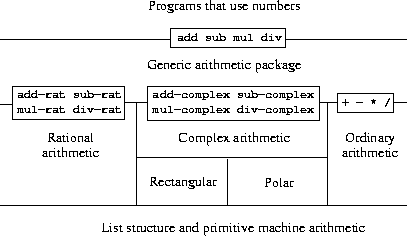
图2.23展示了我们将要构建的系统结构。注意其中的抽象屏障。从使用"数"的人的角度来看,存在一个单一的过程add,它对所提供的任何数进行操作。Add是通用接口的一部分,它使得使用数的程序能够统一地访问分离的普通算术、有理数算术和复数算术包。任何单个的算术包(如复数包)本身也可以通过通用过程(如add-complex)来访问,这些过程组合了为不同表示(如直角坐标和极坐标)设计的包。此外,系统的结构是可加的,因此我们可以单独设计各个算术包,然后将它们组合起来产生一个通用的算术系统。
设计通用算术运算的任务与设计通用复数运算的任务类似。例如,我们希望有一个通用加法过程add,它在普通数上像普通的原始加法+一样工作,在有理数上像add-rat一样工作,在复数上像add-complex一样工作。我们可以通过遵循第2.4.3节中实现复数通用选择器的相同策略来实现add和其他通用算术运算。我们将为每种数附加一个类型标签,并使通用过程根据其参数的数据类型分派到适当的包。
通用算术过程定义如下:
(define (add x y) (apply-generic 'add x y))
(define (sub x y) (apply-generic 'sub x y))
(define (mul x y) (apply-generic 'mul x y))
(define (div x y) (apply-generic 'div x y))
我们首先安装一个处理普通数的包,也就是我们语言中的原始数。我们将使用符号scheme-number来标记它们。这个包中的算术运算就是原始的算术过程(因此无需定义额外的过程来处理未标记的数)。由于这些操作每个都接受两个参数,它们以列表(scheme-number scheme-number)为键被安装到表中:
(define (install-scheme-number-package)
(define (tag x)
(attach-tag 'scheme-number x))
(put 'add '(scheme-number scheme-number)
(lambda (x y) (tag (+ x y))))
(put 'sub '(scheme-number scheme-number)
(lambda (x y) (tag (- x y))))
(put 'mul '(scheme-number scheme-number)
(lambda (x y) (tag (* x y))))
(put 'div '(scheme-number scheme-number)
(lambda (x y) (tag (/ x y))))
(put 'make 'scheme-number
(lambda (x) (tag x)))
'done)
Scheme-number 包的用户将通过以下过程创建(带标签的)普通数:
(define (make-scheme-number n)
((get 'make 'scheme-number) n))
现在,通用算术系统的框架已经就位,我们可以轻松地包含新类型的数。下面是一个执行有理数算术的包。注意,作为可加性的好处,我们可以不加修改地使用第2.1.1节中的有理数代码作为包中的内部过程:
(define (install-rational-package)
;; internal procedures
(define (numer x) (car x))
(define (denom x) (cdr x))
(define (make-rat n d)
(let ((g (gcd n d)))
(cons (/ n g) (/ d g))))
(define (add-rat x y)
(make-rat (+ (* (numer x) (denom y))
(* (numer y) (denom x)))
(* (denom x) (denom y))))
(define (sub-rat x y)
(make-rat (- (* (numer x) (denom y))
(* (numer y) (denom x)))
(* (denom x) (denom y))))
(define (mul-rat x y)
(make-rat (* (numer x) (numer y))
(* (denom x) (denom y))))
(define (div-rat x y)
(make-rat (* (numer x) (denom y))
(* (denom x) (numer y))))
;; interface to rest of the system
(define (tag x) (attach-tag 'rational x))
(put 'add '(rational rational)
(lambda (x y) (tag (add-rat x y))))
(put 'sub '(rational rational)
(lambda (x y) (tag (sub-rat x y))))
(put 'mul '(rational rational)
(lambda (x y) (tag (mul-rat x y))))
(put 'div '(rational rational)
(lambda (x y) (tag (div-rat x y))))
(put 'make 'rational
(lambda (n d) (tag (make-rat n d))))
'done)
(define (make-rational n d)
((get 'make 'rational) n d))
我们可以安装一个类似的包来处理复数,使用标签complex。在创建该包时,我们从表中提取由直角坐标包和极坐标包定义的操作make-from-real-imag和make-from-mag-ang。可加性允许我们使用第2.4.1节中相同的add-complex、sub-complex、mul-complex和div-complex过程作为内部操作。
(define (install-complex-package)
;; imported procedures from rectangular and polar packages
(define (make-from-real-imag x y)
((get 'make-from-real-imag 'rectangular) x y))
(define (make-from-mag-ang r a)
((get 'make-from-mag-ang 'polar) r a))
;; internal procedures
(define (add-complex z1 z2)
(make-from-real-imag (+ (real-part z1) (real-part z2))
(+ (imag-part z1) (imag-part z2))))
(define (sub-complex z1 z2)
(make-from-real-imag (- (real-part z1) (real-part z2))
(- (imag-part z1) (imag-part z2))))
(define (mul-complex z1 z2)
(make-from-mag-ang (* (magnitude z1) (magnitude z2))
(+ (angle z1) (angle z2))))
(define (div-complex z1 z2)
(make-from-mag-ang (/ (magnitude z1) (magnitude z2))
(- (angle z1) (angle z2))))
;; interface to rest of the system
(define (tag z) (attach-tag 'complex z))
(put 'add '(complex complex)
(lambda (z1 z2) (tag (add-complex z1 z2))))
(put 'sub '(complex complex)
(lambda (z1 z2) (tag (sub-complex z1 z2))))
(put 'mul '(complex complex)
(lambda (z1 z2) (tag (mul-complex z1 z2))))
(put 'div '(complex complex)
(lambda (z1 z2) (tag (div-complex z1 z2))))
(put 'make-from-real-imag 'complex
(lambda (x y) (tag (make-from-real-imag x y))))
(put 'make-from-mag-ang 'complex
(lambda (r a) (tag (make-from-mag-ang r a))))
'done)
复数包外部的程序可以通过实部和虚部或者通过模和幅角来构造复数。注意底层过程最初定义在直角坐标包和极坐标包中,如何被导出到复数包,又从那里导出到外部世界。
(define (make-complex-from-real-imag x y)
((get 'make-from-real-imag 'complex) x y))
(define (make-complex-from-mag-ang r a)
((get 'make-from-mag-ang 'complex) r a))
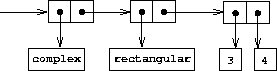
我们这里有的是一个两层标签系统。一个典型的复数,例如直角坐标形式的 3 + 4i,将如图2.24所示表示。外层标签(complex)用于将数导向复数包。进入复数包后,下一层标签(rectangular)用于将数导向直角坐标包。在一个大型而复杂的系统中,可能有多个层次,每一层通过通用操作与下一层连接。当数据对象被"向下"传递时,用于将其导向适当包的外层标签被剥离(通过应用contents),下一层标签(如果有的话)变得可见,用于进一步分派。
|
在上面的包中,我们完全按照最初编写的方式使用了add-rat、add-complex和其他算术过程。然而,一旦这些定义位于不同的安装过程内部,它们就不再需要彼此不同的名称:我们可以简单地在两个包中将它们命名为add、sub、mul和div。
练习 2.77. Louis Reasoner 尝试求值表达式(magnitude z),其中z是图2.24所示的对象。令他惊讶的是,他没有得到答案 5,而是从apply-generic收到了一个错误消息,说对于类型(complex)没有操作magnitude的方法。他把这个交互过程展示给 Alyssa P. Hacker,她说:"问题在于复数选择器从未为complex数定义过,只是为polar和rectangular数定义的。要使它工作,你所要做的就是向complex包中添加以下内容:"
(put 'real-part '(complex) real-part)
(put 'imag-part '(complex) imag-part)
(put 'magnitude '(complex) magnitude)
(put 'angle '(complex) angle)
详细描述为什么这会有效。作为例子,跟踪求值表达式(magnitude z)时调用的所有过程,其中z是图2.24所示的对象。特别地,apply-generic被调用了多少次?每种情况下分派到哪个过程?
练习 2.78. scheme-number包中的内部过程本质上不过是调用原始过程+、-等。之所以不能直接使用语言的原语,是因为我们的类型标签系统要求每个数据对象都附有一个类型。然而,实际上所有 Lisp 实现内部都有一个类型系统。像symbol?和number?这样的原始谓词可以判断数据对象是否具有特定类型。修改第2.4.2节中type-tag、contents和attach-tag的定义,使我们的通用系统利用 Scheme 的内部类型系统。也就是说,系统应该像以前一样工作,只是普通数应该简单地表示为 Scheme 数,而不是其car为符号scheme-number的数对。
练习 2.79. 定义一个通用的相等谓词equ?,用于测试两个数的相等性,并将其安装到通用算术包中。该操作应对普通数、有理数和复数都有效。
练习 2.80. 定义一个通用的谓词=zero?,用于测试其参数是否为零,并将其安装到通用算术包中。该操作应对普通数、有理数和复数都有效。
我们已经看到如何定义一个统一的算术系统,它包含普通数、复数、有理数以及我们可能决定发明的任何其他类型的数,但我们忽略了一个重要问题。到目前为止定义的操作将不同的数据类型视为完全独立的。因此,有用于加法(例如两个普通数或两个复数)的独立包。我们尚未考虑的是,定义跨越类型边界的操作是有意义的,例如将复数与普通数相加。我们费了很大力气在程序各部分之间引入屏障,以便它们可以独立开发和理解。我们希望以某种谨慎可控的方式引入跨类型操作,以便在不会严重破坏模块边界的情况下支持它们。
处理跨类型操作的一种方法是为每个可能的类型组合设计一个不同的过程,只要该操作对该组合有效。例如,我们可以扩展复数包,使其提供一个将复数与普通数相加的过程,并将其安装到表中,使用标签(complex scheme-number):49
;; to be included in the complex package
(define (add-complex-to-schemenum z x)
(make-from-real-imag (+ (real-part z) x)
(imag-part z)))
(put 'add '(complex scheme-number)
(lambda (z x) (tag (add-complex-to-schemenum z x))))
这种技术可行,但很笨重。在这样一个系统中,引入新类型的代价不仅是构造该类型的过程包,还要构造和安装实现跨类型操作的过程。这很容易比定义类型本身的操作所需要的代码多得多。这种方法还削弱了我们以可加方式组合独立包的能力,或者至少限制了个别包实现者需要考虑其他包的程度。例如,在上面的例子中,处理复数和普通数的混合操作似乎是复数包的责任。然而,组合有理数和复数可能由复数包、有理数包或某个使用从这两个包中提取的操作的第三方包来完成。在有许多包和许多跨类型操作的系统中,制定关于包间职责划分的一致策略可能是一项艰巨的任务。
在操作完全无关、类型也完全无关的一般情况下,实现显式的跨类型操作(尽管笨重)是我们所能期望的最好结果。幸运的是,通过利用可能潜伏在类型系统中的额外结构,我们通常可以做得更好。通常不同的数据类型并非完全独立,可能存在某种方式使得一种类型的对象可以被视为另一种类型。这个过程称为强制转换。例如,如果要求我们将一个普通数与一个复数进行算术组合,我们可以将普通数视为虚部为零的复数。这将问题转化为组合两个复数,这可以由复数算术包以通常的方式处理。
一般来说,我们可以通过设计强制转换过程来实现这个思想,这些过程将一种类型的对象转换为另一种类型的等价对象。下面是一个典型的强制转换过程,它将给定的普通数转换为具有该实部和零虚部的复数:
(define (scheme-number->complex n)
(make-complex-from-real-imag (contents n) 0))
我们将这些强制转换过程安装在一个特殊的强制转换表中,以两种类型的名称为索引:
(put-coercion 'scheme-number 'complex scheme-number->complex)
(我们假设有put-coercion和get-coercion过程可用于操作这个表。)通常表中的一些槽将是空的,因为通常不可能将任意数据对象从每种类型强制转换为所有其他类型。例如,没有办法将任意复数强制转换为普通数,因此表中不会包含通用的complex->scheme-number过程。
一旦建立了强制转换表,我们可以通过修改第2.4.3节的apply-generic过程来以统一的方式处理强制转换。当被要求应用一个操作时,我们首先检查该操作是否已为参数的类型定义,和之前一样。如果是,我们分派到操作-类型表中找到的过程。否则,我们尝试强制转换。为简单起见,我们只考虑有两个参数的情况。50 我们检查强制转换表,看第一类型的对象是否可以强制转换为第二类型。如果可以,我们强制转换第一个参数并再次尝试该操作。如果第一类型的对象通常不能强制转换为第二类型,我们尝试另一种方向的强制转换,看看是否可以将第二个参数强制转换为第一个参数的类型。最后,如果没有已知的方法可以将任一类型强制转换为另一类型,我们就放弃。以下是该过程:
(define (apply-generic op . args)
(let ((type-tags (map type-tag args)))
(let ((proc (get op type-tags)))
(if proc
(apply proc (map contents args))
(if (= (length args) 2)
(let ((type1 (car type-tags))
(type2 (cadr type-tags))
(a1 (car args))
(a2 (cadr args)))
(let ((t1->t2 (get-coercion type1 type2))
(t2->t1 (get-coercion type2 type1)))
(cond (t1->t2
(apply-generic op (t1->t2 a1) a2))
(t2->t1
(apply-generic op a1 (t2->t1 a2)))
(else
(error "No method for these types"
(list op type-tags))))))
(error "No method for these types"
(list op type-tags)))))))
这种强制转换方案相比于上面概述的定义显式跨类型操作的方法有许多优点。尽管我们仍然需要编写强制转换过程来关联类型(对于一个有n种类型的系统,可能需要n2个过程),但我们只需要为每对类型编写一个过程,而不是为每个类型集合和每个通用操作编写一个不同的过程。51 我们这里所依赖的事实是,类型之间的适当变换只取决于类型本身,而不是要应用的操作。
另一方面,可能存在我们的强制转换方案不够通用的应用。即使两个要组合的对象都不能转换为对方的类型,仍有可能通过将两个对象都转换为第三种类型来执行操作。为了处理这种复杂性并同时保持程序的模块性,通常需要构建利用类型之间关系中更进一步结构的系统,我们接下来将讨论这一点。
上面介绍的强制转换方案依赖于类型对之间存在的自然关系。通常,不同类型之间如何相互关联存在更"全局"的结构。例如,假设我们正在构建一个通用算术系统来处理整数、有理数、实数和复数。在这样的系统中,很自然地将整数视为一种特殊的有理数,而有理数又是一种特殊的实数,实数又是一种特殊的复数。我们实际上拥有的是一个所谓的类型层次结构,其中,例如,整数是有理数的子类型(即,任何可以应用于有理数的操作都可以自动应用于整数)。反过来,我们说有理数构成整数的超类型。我们这里的具体层次结构是一种非常简单的类型,其中每个类型至多有一个超类型和至多一个子类型。这样的结构称为塔,如图2.25所示。
如果我们有一个塔结构,那么向层次结构中添加新类型的问题就可以大大简化,因为我们只需要指定新类型如何嵌入到它上面的下一个超类型中,以及它如何作为下面类型的超类型。例如,如果我们想将一个整数加到一个复数上,我们不需要显式定义一个特殊的强制转换过程integer->complex。相反,我们定义整数如何转换为有理数,有理数如何转换为实数,以及实数如何转换为复数。然后我们让系统通过这些步骤将整数转换为复数,然后再将两个复数相加。
我们可以按以下方式重新设计我们的apply-generic过程:对于每种类型,我们需要提供一个raise过程,它将该类型的对象在塔中"提升"一级。然后当系统需要对不同类型的对象进行操作时,它可以连续提升较低的类型,直到所有对象都处于塔中的同一层次。(练习2.83和2.84涉及实现这种策略的细节。)
塔的另一个优点是,我们可以轻松地实现每个类型"继承"在超类型上定义的所有操作的概念。例如,如果我们没有提供寻找整数实部的特殊过程,我们仍然期望real-part对于整数有定义,因为整数是复数的子类型。在塔中,我们可以通过修改apply-generic来以统一的方式安排这种情况。如果所需操作没有为给定对象的类型直接定义,我们将对象提升到其超类型并再次尝试。因此,我们在塔中向上爬,一边爬一边转换参数,直到找到可以执行所需操作的层次,或者到达顶部(此时放弃)。
塔相对于更一般的层次结构的另一个优点是,它给了我们一种简单的方法来将数据对象"降低"到最简单的表示。例如,如果我们将 2 + 3i 加到 4 - 3i 上,得到整数 6 而不是复数 6 + 0i 将会很好。练习2.85讨论了实现这种降低操作的一种方法。(技巧在于我们需要一种通用的方法来区分那些可以降低的对象,例如 6 + 0i,和那些不能降低的对象,例如 6 + 2i。)
|
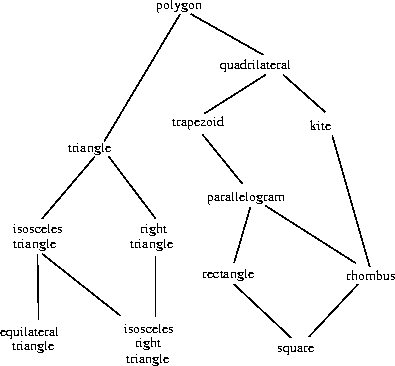
如我们所见,如果系统中的数据类型可以自然地排列成塔,这将大大简化处理不同类型上的通用操作的问题。不幸的是,通常情况并非如此。图2.26展示了一种更复杂的混合类型排列,展示了不同几何图形类型之间的关系。我们看到,一般来说,一个类型可能有多个子类型。例如,三角形和四边形都是多边形的子类型。此外,一个类型可能有多个超类型。例如,等腰直角三角形既可以看作等腰三角形,也可以看作直角三角形。这种多超类型问题尤其棘手,因为它意味着没有唯一的方法来"提升"层次结构中的类型。对于诸如apply-generic这样的过程来说,找到对对象应用操作的"正确"超类型可能涉及在整个类型网络中进行大量搜索。由于一个类型通常有多个子类型,在类型层次结构中向"下"强制转换值也存在类似的问题。处理大量相互关联的类型同时保持大型系统设计中的模块性是非常困难的,并且是目前许多研究的领域。52
练习 2.81. Louis Reasoner 注意到,即使两个参数已经具有相同的类型,apply-generic也可能尝试将参数强制转换为对方的类型。因此,他认为我们需要在强制转换表中放置将每种类型的参数"强制转换"到自身的过程。例如,除了上面展示的scheme-number->complex强制转换外,他还将这样做:
(define (scheme-number->scheme-number n) n)
(define (complex->complex z) z)
(put-coercion 'scheme-number 'scheme-number
scheme-number->scheme-number)
(put-coercion 'complex 'complex complex->complex)
a. 在安装了 Louis 的强制转换过程后,如果apply-generic被调用时带有两个scheme-number类型的参数或两个complex类型的参数,对于一个在表中未找到的操作,会发生什么?例如,假设我们定义了一个通用乘幂操作:
(define (exp x y) (apply-generic 'exp x y))
并且我们在 Scheme-number 包中放置了一个乘幂过程,但未在任何其他包中放置:
;; following added to Scheme-number package
(put 'exp '(scheme-number scheme-number)
(lambda (x y) (tag (expt x y)))) ; using primitive expt
如果我们用两个复数作为参数调用exp,会发生什么?
b. Louis 认为必须对相同类型参数的强制转换采取一些措施,这个看法正确吗?还是apply-generic按原样工作是正确的?
c. 修改apply-generic,使其在两个参数具有相同类型时不尝试强制转换。
练习 2.82. 展示如何将apply-generic推广到处理多个参数情况下的强制转换。一种策略是尝试将所有参数强制转换为第一个参数的类型,然后是第二个参数的类型,依此类推。给出一个例子,说明这种策略(以及上面给出的两参数版本)不够通用。(提示:考虑表中存在某些合适的混合类型操作但不会被尝试的情况。)
练习 2.83. 假设你正在设计一个通用算术系统,用于处理图2.25所示的类型塔:整数、有理数、实数、复数。对于每种类型(除了复数),设计一个将该类型的对象在塔中提升一级的过程。展示如何安装一个通用的raise操作,使其对每种类型(除了复数)都有效。
练习 2.84. 使用练习2.83中的raise操作,修改apply-generic过程,使其通过本节讨论的连续提升方法将其参数强制转换为相同的类型。你需要设计一种方法来测试两个类型中哪一个在塔中更高。请以与系统其余部分"兼容"的方式执行此操作,并且不会在向塔中添加新层次时导致问题。
练习 2.85. 本节提到了一种通过在类型塔中尽可能降低来"简化"数据对象的方法。设计一个过程drop,对练习2.83中描述的塔实现此功能。关键在于以某种通用方式判断一个对象是否可以降低。例如,复数 1.5 + 0i 可以一直降低到real,复数 1 + 0i 可以降低到integer,而复数 2 + 3i 则完全不能降低。以下是一个判断对象是否可以降低的计划:首先定义一个通用操作project,它将对象在塔中"向下推"。例如,投影一个复数涉及丢弃虚部。然后,一个数如果可以降低,当我们project它并将结果raise回我们开始的类型时,我们最终得到的东西等于我们开始的东西。详细展示如何实现这个想法,编写一个drop过程,尽可能降低一个对象。你将需要设计各种投影操作53,并将project作为通用操作安装在系统中。你还需要使用一个通用的相等谓词,如练习2.79中所述。最后,使用drop重写练习2.84中的apply-generic,使其"简化"其结果。
练习 2.86. 假设我们想处理其实部、虚部、模和幅角可以是普通数、有理数或我们可能想添加到系统中的其他数的复数。描述并实现系统所需的更改以适应这一点。你将需要定义诸如sine和cosine之类的操作,它们在普通数和有理数上是通用的。
符号代数表达式的操作是一个复杂的过程,它说明了大型系统设计中出现的许多最困难的问题。一个代数表达式,一般可以看作一个层次结构,一个应用于操作数的运算符树。我们可以通过从一组原始对象(如常量和变量)开始,然后通过代数运算符(如加法和乘法)组合它们来构造代数表达式。与其他语言一样,我们形成抽象,使我们能够用简单的术语指代复合对象。符号代数中典型的抽象有线性组合、多项式、有理函数或三角函数等概念。我们可以将这些视为复合的"类型",它们通常用于指导表达式的处理。例如,我们可以将表达式
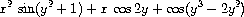
描述为一个在x上的多项式,其系数是y上的多项式的三角函数,而这些多项式的系数是整数。
我们不会在此尝试开发一个完整的代数操作系统。这样的系统是非常复杂的程序,包含深入的代数知识和优雅的算法。我们要做的是考察代数操作的一个简单但重要的部分:多项式的算术。我们将说明此类系统的设计者面临的各种决策,以及如何应用抽象数据和通用操作的思想来帮助组织这项工作。
在设计用于执行多项式算术的系统时,我们的首要任务是确定多项式到底是什么。多项式通常相对于某些变量(多项式的自变量)来定义。为简单起见,我们将限制自己只处理只有一个自变量的多项式(一元多项式)。54 我们将多项式定义为项的和,每个项要么是一个系数,要么是自变量的一个幂,要么是系数与自变量幂的乘积。系数定义为不依赖于多项式自变量的代数表达式。例如,
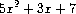
是一个关于x的简单多项式,而
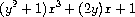
是一个关于x的多项式,其系数是关于y的多项式。
我们已经触及一些棘手的问题。第一个多项式是否与多项式 5y2 + 3y + 7 相同?一个合理的答案可能是:"是的,如果我们纯粹将多项式视为数学函数,但如果将多项式视为语法形式,则不是。"第二个多项式代数上等价于一个关于y的多项式,其系数是关于x的多项式。我们的系统是否应该识别这一点?此外,还有多种其他方式来表示多项式——例如,作为因子的乘积,或者(对于一元多项式)作为根的集合,或者作为多项式在一组指定点上的值的列表。55 我们可以通过决定在我们的代数操作系统中,"多项式"将是一种特定的语法形式,而不是其底层的数学意义,来回避这些问题。
现在我们必须考虑如何进行多项式的算术运算。在这个简单的系统中,我们只考虑加法和乘法。此外,我们将坚持要求要组合的两个多项式必须具有相同的自变量。
我们将通过遵循熟悉的数据抽象规范来设计我们的系统。我们将使用一种称为poly的数据结构来表示多项式,它由一个变量和一个项集合组成。我们假设有选择器variable和term-list从 poly 中提取这些部分,以及一个构造函数make-poly从给定的变量和项列表组装成一个 poly。变量只是一个符号,因此我们可以使用第2.3.2节的same-variable?过程来比较变量。 以下过程定义了 poly 的加法和乘法:
(define (add-poly p1 p2)
(if (same-variable? (variable p1) (variable p2))
(make-poly (variable p1)
(add-terms (term-list p1)
(term-list p2)))
(error "Polys not in same var -- ADD-POLY"
(list p1 p2))))
(define (mul-poly p1 p2)
(if (same-variable? (variable p1) (variable p2))
(make-poly (variable p1)
(mul-terms (term-list p1)
(term-list p2)))
(error "Polys not in same var -- MUL-POLY"
(list p1 p2))))
为了将多项式整合到我们的通用算术系统中,我们需要为它们提供类型标签。我们将使用标签polynomial,并在操作表中安装带标签的多项式的适当操作。我们将把所有代码嵌入到多项式包的安装过程中,类似于第2.5.1节中的那些过程:
(define (install-polynomial-package)
;; internal procedures
;; representation of poly
(define (make-poly variable term-list)
(cons variable term-list))
(define (variable p) (car p))
(define (term-list p) (cdr p))
<procedures same-variable? and variable? from section 2.3.2>
;; representation of terms and term lists
<procedures adjoin-term ...coeff from text below>
;; continued on next page
(define (add-poly p1 p2) ...)
<procedures used by add-poly>
(define (mul-poly p1 p2) ...)
<procedures used by mul-poly>
;; interface to rest of the system
(define (tag p) (attach-tag 'polynomial p))
(put 'add '(polynomial polynomial)
(lambda (p1 p2) (tag (add-poly p1 p2))))
(put 'mul '(polynomial polynomial)
(lambda (p1 p2) (tag (mul-poly p1 p2))))
(put 'make 'polynomial
(lambda (var terms) (tag (make-poly var terms))))
'done)
多项式加法按项进行。相同阶数(即具有相同自变量幂)的项必须合并。这是通过形成一个新的同阶项来完成的,其系数是被加数的系数之和。一个加数中存在而另一个加数中没有同阶项的项,直接累加到正在构建的和多项式中。
为了操作项列表,我们将假设我们有一个构造函数the-empty-termlist返回一个空项列表,以及一个构造函数adjoin-term将一个新项加入项列表。我们还将假设我们有一个谓词empty-termlist?判断给定项列表是否为空,一个选择器first-term提取项列表中最高阶的项,以及一个选择器rest-terms返回除最高阶项外的所有项。为了操作项,我们将假设我们有一个构造函数make-term用给定的阶数和系数构造一个项,以及选择器order和coeff分别返回项的阶数和系数。这些操作使我们能够将项和项列表都视为数据抽象,其具体表示我们可以分别考虑。
以下是构造两个多项式和的项列表的过程:56
(define (add-terms L1 L2)
(cond ((empty-termlist? L1) L2)
((empty-termlist? L2) L1)
(else
(let ((t1 (first-term L1)) (t2 (first-term L2)))
(cond ((> (order t1) (order t2))
(adjoin-term
t1 (add-terms (rest-terms L1) L2)))
((< (order t1) (order t2))
(adjoin-term
t2 (add-terms L1 (rest-terms L2))))
(else
(adjoin-term
(make-term (order t1)
(add (coeff t1) (coeff t2)))
(add-terms (rest-terms L1)
(rest-terms L2)))))))))
这里需要注意的最重要的一点是,我们使用了通用加法过程add来将被组合的项的系数相加。这具有强大的后果,如下所示。
为了将两个项列表相乘,我们将第一个列表的每个项与另一个列表的所有项相乘,重复使用mul-term-by-all-terms,它将一个给定的项与给定项列表中的所有项相乘。得到的项列表(第一个列表的每个项对应一个)被累加成一个和。将两个项相乘,形成一个阶数为因子阶数之和、系数为因子系数之积的项:
(define (mul-terms L1 L2)
(if (empty-termlist? L1)
(the-empty-termlist)
(add-terms (mul-term-by-all-terms (first-term L1) L2)
(mul-terms (rest-terms L1) L2))))
(define (mul-term-by-all-terms t1 L)
(if (empty-termlist? L)
(the-empty-termlist)
(let ((t2 (first-term L)))
(adjoin-term
(make-term (+ (order t1) (order t2))
(mul (coeff t1) (coeff t2)))
(mul-term-by-all-terms t1 (rest-terms L))))))
这就是多项式加法和乘法的全部内容。 注意,由于我们使用通用过程add和mul来操作项,我们的多项式包能够自动处理通用算术包已知的任何类型的系数。如果我们包含一个类似于第2.5.2节中讨论的强制转换机制,那么我们还能自动处理不同系数类型的多项式上的操作,例如
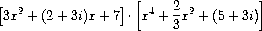
由于我们将多项式加法和乘法过程add-poly和mul-poly作为类型polynomial的add和mul操作安装在通用算术系统中,我们的系统也能够自动处理像这样的多项式操作:
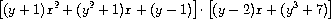
原因是当系统尝试组合系数时,它将通过add和mul进行分派。由于系数本身就是多项式(关于y),这些将使用add-poly和mul-poly进行组合。结果是一种"数据导向的递归",例如,对mul-poly的调用将导致递归调用mul-poly来相乘系数。如果系数的系数本身又是多项式(可能用于表示三个变量的多项式),数据导向将确保系统再跟进一层递归调用,以此类推,沿数据的结构决定有多少层。57
最后,我们必须面对实现一个好的项列表表示的任务。项列表实际上是一组按项阶数索引的系数。因此,第2.3.3节中讨论的任何表示集合的方法都可以应用于此任务。另一方面,我们的过程add-terms和mul-terms总是从最高阶到最低阶顺序访问项列表。因此,我们将使用某种有序列表表示。
我们如何构造表示项列表的列表?一个考虑因素是我们打算操作的多项式的"密度"。如果一个多项式在大部分阶数上都有非零系数,则称其为稠密的。如果它有许多零项,则称其为稀疏的。例如,
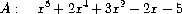
是一个稠密多项式,而
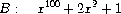
是稀疏的。
稠密多项式的项列表最有效地表示为系数列表。例如,上面的A可以很好地表示为(1 2 0 3 -2 -5)。在这种表示中,项的阶数是始于该系数开始的子列表的长度减1。58 这对于像B这样的稀疏多项式将是一种糟糕的表示:会有巨大的一列零,其中点缀着几个孤独的非零项。稀疏多项式的项列表更合理的表示是作为非零项的列表,其中每个项是一个包含该项阶数和系数的列表。在这样的方案中,多项式B可以有效地表示为((100 1) (2 2) (0 1))。由于大多数多项式操作是在稀疏多项式上进行的,我们将使用这种方法。我们将假设项列表表示为项的列表,按从最高阶到最低阶排列。一旦做出这个决定,实现项和项列表的选择器和构造函数就很简单了:59
(define (adjoin-term term term-list)
(if (=zero? (coeff term))
term-list
(cons term term-list)))
(define (the-empty-termlist) '())
(define (first-term term-list) (car term-list))
(define (rest-terms term-list) (cdr term-list))
(define (empty-termlist? term-list) (null? term-list))
(define (make-term order coeff) (list order coeff))
(define (order term) (car term))
(define (coeff term) (cadr term))
其中=zero?如练习2.80中所定义。(另见下面的练习2.87。)
多项式包的用户将通过以下过程创建(带标签的)多项式:
(define (make-polynomial var terms)
((get 'make 'polynomial) var terms))
练习 2.87. 在通用算术包中为多项式安装=zero?。这将允许adjoin-term用于系数本身是多边形的多项式。
练习 2.88. 扩展多项式系统以包含多项式的减法。(提示:你可能发现定义一个通用的取反操作很有帮助。)
练习 2.89. 定义实现上述描述的适用于稠密多项式的项列表表示的过程。
练习 2.90. 假设我们希望有一个同时对稀疏和稠密多项式都高效的多项式系统。一种方法是允许系统中两种类型的项列表表示。这种情况类似于第2.4节的复数示例,其中我们允许直角坐标和极坐标两种表示。要做到这一点,我们必须区分不同类型的项列表,并使项列表上的操作成为通用的。重新设计多项式系统以实现这种推广。这是一项重大的工作,不是局部修改。
练习 2.91. 一个一元多项式可以除以另一个一元多项式,产生一个多项式商和多项式余式。例如,
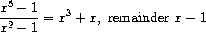
除法可以通过长除法进行。也就是说,将被除数的最高阶项除以除数的最高阶项。结果是商的第一项。接下来,将结果乘以除数,从被除数中减去,然后通过递归地将差除以除数来产生答案的其余部分。当除数的阶数超过被除数的阶数时停止,并声明被除数为余式。此外,如果被除数变为零,则返回零作为商和余式。
我们可以以add-poly和mul-poly为模型设计一个div-poly过程。该过程检查两个多项式是否具有相同的变量。如果是,div-poly剥离变量并将问题传递给div-terms,后者在项列表上执行除法运算。Div-poly最后将变量重新附加到div-terms提供的结果上。将div-terms设计为同时计算除法的商和余式是很方便的。Div-terms可以接受两个项列表作为参数,并返回一个列表,包含商项列表和余式项列表。
通过填写缺少的表达式来完成以下div-terms的定义。使用它来实现div-poly,它接受两个多项式作为参数,并返回商多项式和余式多项式的列表。
(define (div-terms L1 L2)
(if (empty-termlist? L1)
(list (the-empty-termlist) (the-empty-termlist))
(let ((t1 (first-term L1))
(t2 (first-term L2)))
(if (> (order t2) (order t1))
(list (the-empty-termlist) L1)
(let ((new-c (div (coeff t1) (coeff t2)))
(new-o (- (order t1) (order t2))))
(let ((rest-of-result
<compute rest of result recursively>
))
<form complete result>
))))))
我们的多项式系统说明了一种类型的对象(多项式)实际上可能是复合对象,其组成部分是许多不同类型的对象。这并不会给定义通用操作带来真正的困难。我们只需要安装适当的通用操作来执行复合类型各部分所需的操作。事实上,我们看到多项式形成了一种"递归数据抽象",因为多项式的部分本身可能是多项式。我们的通用操作和数据导向编程风格可以毫无困难地处理这种复杂性。
另一方面,多项式代数是一个系统的数据类型不能自然地排列成塔的例子。例如,可能有关于x的多项式,其系数是关于y的多项式。也可能有关于y的多项式,其系数是关于x的多项式。这两种类型没有一种在自然意义上"高于"另一种,但往往需要将每组中的元素相加。有几种方法可以做到这一点。一种可能性是通过展开和重排项,使两个多项式具有相同的主变量,将一个多项式转换为另一个多项式的类型。可以通过对变量进行排序,从而始终将任何多项式转换为一种"规范形式",其中最高优先级的变量占主导地位,较低优先级的变量埋藏在系数中,来对此施加一种类似塔的结构。这种策略效果相当好,只是转换可能会不必要地展开多项式,使其难以阅读,并且可能降低操作效率。塔策略对于这个领域或任何用户可以动态使用旧类型以各种组合形式(如三角函数、幂级数和积分)发明新类型的领域来说,当然是不自然的。
控制强制转换是大型代数操作系统设计中的一个严重问题,这不应该令人惊讶。这类系统的许多复杂性都与不同种类类型之间的关系有关。事实上,公平地说,我们尚未完全理解强制转换。实际上,我们甚至尚未完全理解数据类型的概念。尽管如此,我们所知道的为我们提供了强大的结构和模块化原则,以支持大型系统的设计。
练习 2.92. 通过对变量施加排序,扩展多项式包,使得多项式的加法与乘法对具有不同变量的多项式也能工作。(这并不容易!)
我们可以扩展通用算术系统以包含有理函数。这些是其分子和分母都是多项式的"分数",例如
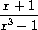
系统应该能够加、减、乘和除有理函数,并执行如下计算:
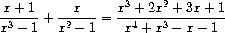
(这里的和已通过消除公因子进行了简化。普通的"交叉相乘"将产生一个四次多项式除以一个五次多项式。)
如果我们修改有理数算术包使其使用通用操作,那么它将做我们想要的,除了将分数化为最简形式的问题。
练习 2.93. 修改有理数算术包以使用通用操作,但修改make-rat使其不尝试将分数化为最简形式。通过在两个多项式上调用make-rational来产生一个有理函数来测试你的系统:
(define p1 (make-polynomial 'x '((2 1)(0 1))))
(define p2 (make-polynomial 'x '((3 1)(0 1))))
(define rf (make-rational p2 p1))
现在使用add将rf与自身相加。你将观察到这个加法过程不会将分数化为最简形式。
我们可以使用与整数相同的思想将多项式分数化为最简形式:修改make-rat,将分子和分母都除以它们的最大公约数。"最大公约数"的概念对多项式是有意义的。事实上,我们可以使用本质上与整数相同的欧几里得算法来计算两个多项式的 GCD。60 整数版本是
(define (gcd a b)
(if (= b 0)
a
(gcd b (remainder a b))))
使用此方法,我们可以进行明显的修改来定义一个在项列表上工作的 GCD 操作:
(define (gcd-terms a b)
(if (empty-termlist? b)
a
(gcd-terms b (remainder-terms a b))))
其中remainder-terms从练习2.91中实现的项列表除法操作div-terms返回的列表中挑选出余式部分。
练习 2.94. 使用div-terms,实现过程remainder-terms,并使用它按上述方式定义gcd-terms。现在编写一个过程gcd-poly,计算两个多项式的多项式 GCD。(该过程应在两个多项式不在同一变量时发出错误信号。)在系统中安装一个通用操作greatest-common-divisor,对多项式归结为gcd-poly,对普通数归结为普通的gcd。作为测试,尝试
(define p1 (make-polynomial 'x '((4 1) (3 -1) (2 -2) (1 2))))
(define p2 (make-polynomial 'x '((3 1) (1 -1))))
(greatest-common-divisor p1 p2)
并用手工检查结果。
练习 2.95. 定义 P1、P2 和 P3 为以下多项式:
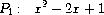
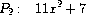
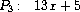
现在定义 Q1 为 P1 和 P2 的乘积,Q2 为 P1 和 P3 的乘积,并使用greatest-common-divisor(练习2.94)计算 Q1 和 Q2 的 GCD。注意结果与 P1 不同。这个例子在计算中引入了非整数操作,导致 GCD 算法出现问题。61 要理解发生了什么,尝试在计算 GCD 时跟踪gcd-terms,或手工进行除法。
如果使用以下 GCD 算法的修改版本,我们可以解决练习2.95中展示的问题(这实际上只适用于系数为整数的多项式的情况)。在进行 GCD 计算中的任何多项式除法之前,我们将被除数乘以一个整数常数因子,选择该因子以保证除法过程中不会出现分数。因此,我们的答案将与实际的 GCD 相差一个整数常数因子,但在将有理函数化为最简形式的情况下,这无关紧要;GCD 将用于同时除以分子和分母,因此整数常数因子将被抵消。
更精确地说,如果 P 和 Q 是多项式,令 O1 为 P 的阶数(即 P 的最大项的阶数),令 O2 为 Q 的阶数。令 c 为 Q 的首项系数。那么可以证明,如果我们将 P 乘以整化因子 c1+O1 -O2,生成的多项式可以使用div-terms算法除以 Q 而不会引入任何分数。将被除数乘以这个常数然后进行除法的操作有时被称为 P 除以 Q 的伪除法。除法的余式称为伪余式。
练习 2.96. a. 实现过程pseudoremainder-terms,它与remainder-terms类似,只是在调用div-terms之前将上述整化因子乘以被除数。修改gcd-terms以使用pseudoremainder-terms,并验证greatest-common-divisor现在对练习2.95中的例子产生了具有整数系数的答案。
b. GCD 现在具有整数系数,但它们比 P1 的系数大。修改gcd-terms,通过将答案的所有系数除以它们的(整数)最大公约数来消除答案系数中的公因子。
练习 2.97. a. 将上述算法实现为一个过程reduce-terms,它接受两个项列表 n 和 d 作为参数,并返回一个列表 nn、dd,它们是通过上述算法将 n 和 d 化为最简形式的结果。还要编写一个过程reduce-poly,类似于add-poly,检查两个多项式是否具有相同的变量。如果是,reduce-poly剥离变量并将问题传递给reduce-terms,然后将变量重新附加到由reduce-terms提供的两个项列表上。
b. 定义一个类似于reduce-terms的过程,它执行原始make-rat对整数所做的操作:
(define (reduce-integers n d)
(let ((g (gcd n d)))
(list (/ n g) (/ d g))))
并将reduce定义为一个通用操作,它调用apply-generic分派到reduce-poly(对于polynomial参数)或reduce-integers(对于scheme-number参数)。现在,你可以通过让make-rat在组合给定的分子和分母形成有理数之前调用reduce,轻松地使有理数算术包将分数化为最简形式。该系统现在可以处理整数或多边形的有理表达式。要测试你的程序,尝试本扩展练习开头的例子:
(define p1 (make-polynomial 'x '((1 1)(0 1))))
(define p2 (make-polynomial 'x '((3 1)(0 -1))))
(define p3 (make-polynomial 'x '((1 1))))
(define p4 (make-polynomial 'x '((2 1)(0 -1))))
(define rf1 (make-rational p1 p2))
(define rf2 (make-rational p3 p4))
(add rf1 rf2)
看看你是否能得到正确的答案,并正确地化为最简形式。
GCD 计算是任何进行有理函数运算的系统的核心。上面使用的算法虽然在数学上很直接,但非常缓慢。缓慢的部分原因是大量的除法操作,部分原因是伪除法产生的中间系数极其庞大。代数操作系统发展中的一个活跃领域是设计更好的多项式 GCD 算法。62
49 我们还需要提供一个几乎相同的过程来处理(scheme-number complex)类型。
51 如果我们足够聪明,通常可以用少于n2个强制转换过程。例如,如果我们知道如何从类型1转换为类型2以及从类型2转换为类型3,那么我们可以利用这个知识从类型1转换为类型3。这可以在我们向系统添加新类型时大大减少需要显式提供的强制转换过程的数量。如果我们愿意在系统中构建所需的复杂程度,我们可以让它搜索类型之间的关系"图",并自动生成那些可以从显式提供的过程推断出来的强制转换过程。
52 这个陈述也出现在本书的第一版中,现在它和我们十二年前写下它时一样真实。开发一个有用的、通用的框架来表达不同类型实体之间的关系(哲学家称之为"本体论")似乎困难得难以处理。十年前存在的混乱和现在存在的混乱之间的主要区别是,现在各种不充分的本体论理论已被体现在大量相应不充分的编程语言中。例如,面向对象编程语言的许多复杂性——以及当代面向对象语言之间微妙而令人困惑的差异——都集中在如何处理相互关联类型上的通用操作。我们在第3章中对计算对象的讨论完全回避了这些问题。熟悉面向对象编程的读者会注意到,我们在第3章中有很多关于局部状态的讨论,但我们甚至没有提到"类"或"继承"。事实上,我们怀疑这些问题不能仅通过计算机语言设计来充分解决,还需要借助知识表示和自动推理方面的工作。
53 实数可以使用round原始过程投影为整数,该过程返回最接近参数的整数。
54 另一方面,我们将允许系数本身是其他变量中的多项式。这将给我们基本上与完整多变量系统相同的表示能力,尽管它确实会导致强制转换问题,如下文所述。
55 对于一元多项式,在给定一组点上给出多项式的值可以是一种特别好的表示。这使得多项式算术变得极其简单。例如,要得到以这种方式表示的两个多项式的和,我们只需要将多项式在对应点上的值相加。要转换回更熟悉的表示,我们可以使用拉格朗日插值公式,该公式展示了如何根据多项式在 n + 1 个点上的值恢复 n 次多项式的系数。
56 这个操作非常类似于我们在练习2.62中开发的union-set操作。实际上,如果我们将多项式的项视为按照自变量幂排序的集合,那么产生和项列表的程序几乎与union-set相同。
57 为了使这个工作完全平滑,我们还应该在我们的通用算术系统中添加将"数"强制转换为多项式的能力,通过将其视为零次多项式,其系数就是该数。如果我们要执行诸如
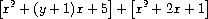
之类的操作,这是必要的,因为该操作需要将系数 y + 1 加到系数 2 上。
58 在这些多项式示例中,我们假设我们已经使用练习2.78中建议的类型机制实现了通用算术系统。因此,作为普通数的系数将表示为数本身,而不是其car为符号scheme-number的数对。
59 虽然我们假设项列表是有序的,但我们已经实现adjoin-term简单地将新项cons到现有项列表中。只要保证使用adjoin-term的过程(例如add-terms)总是用比列表中出现的任何项更高阶的项来调用它,我们就可以这样做。如果我们不想做这样的保证,我们可以将adjoin-term实现为类似于有序列表表示集合的adjoin-set构造函数(练习2.61)。
60 欧几里得算法对多项式也成立这一事实在代数中被形式化为多项式构成一种称为欧几里得环的代数域。欧几里得环是一个允许加法、减法和可交换乘法的域,同时有一种方法为环的每个元素 x 分配一个正整数"测度" m(x),满足对于任何非零 x 和 y 有 m(xy)> m(x),并且给定任何 x 和 y,存在 q 使得 y = qx + r,并且要么 r = 0,要么 m(r)< m(x)。从抽象的角度来看,这就是证明欧几里得算法所需的条件。对于整数域,整数 m 的测度是整数本身的绝对值。对于多项式域,多项式的测度是其次数。
61 在像 MIT Scheme 这样的实现中,这会生成一个确实是 Q1 和 Q2 的因子的多项式,但具有有理系数。在许多其他 Scheme 系统中,其中整数除法可能产生有限精度的小数,我们可能无法得到有效的因子。
62 一种极其高效且优雅的计算多项式 GCD 的方法是由Richard Zippel(1979)发现的。该方法是一种概率算法,就像我们在第1章中讨论的快速素数测试一样。Zippel 的著作(1993)描述了这种方法,以及其他计算多项式 GCD 的方法。
