|
一种强大的编程语言不仅仅是指导计算机执行任务的手段。语言还是一个框架,我们在其中组织关于过程的思想。因此,当描述一种语言时,我们应该特别注意该语言提供的将简单思想组合成更复杂思想的方式。每种强大的语言都有三种实现这一点的机制:
在编程中,我们处理两种元素:过程和数据。(稍后我们会发现它们实际上并非如此泾渭分明。)非正式地说,数据是我们想要操作的"东西",而过程是操作数据的规则描述。因此,任何强大的编程语言都应该能够描述基本数据和基本过程,并应有组合和抽象过程与数据的方法。
在本章中,我们将只处理简单的数值数据,以便专注于构建过程的规则。4在后续章节中,我们将看到同样的规则也能让我们构建操作复合数据的过程。
开始编程的一个简单方法是考察与 Scheme(Lisp 方言)解释器的一些典型交互。想象你坐在计算机终端前。你输入一个表达式,解释器通过显示其求值该表达式的结果来响应。
你可能输入的一种基本表达式是数字。(更准确地说,你输入的表达式由以十进制表示该数的数码组成。)如果你向 Lisp 提供一个数字
486
解释器将打印出5
486
表示数字的表达式可以与表示基本过程(如 + 或 *)的表达式组合,形成表示将该过程应用于这些数字的复合表达式。 例如:
(+ 137 349)
486
(- 1000 334)
666
(* 5 99)
495
(/ 10 5)
2
(+ 2.7 10)
12.7
通过在括号内界定一个表达式列表来表示过程应用而形成的表达式称为组合式。列表中最左边的元素称为运算符,其他元素称为运算对象。组合式的值通过将运算符指定的过程应用于作为运算对象值的参数而获得。
将运算符放在运算对象左侧的惯例称为前缀表示,一开始可能有些令人困惑,因为它显著偏离了传统的数学惯例。然而,前缀表示有几个优点。其中之一是它可以容纳可能接受任意数量参数的过程,如下例所示:
(+ 21 35 12 7)
75
(* 25 4 12)
1200
不会产生歧义,因为运算符总是最左边的元素,整个组合式由括号界定。
前缀表示的第二个优点是它以直接的方式扩展,允许组合式嵌套,即组合式的元素本身也是组合式:
(+ (* 3 5) (- 10 6))
19
Lisp 解释器可以求值的表达式的嵌套深度和整体复杂度(原则上)没有限制。是我们人类会被仍然相对简单的表达式弄糊涂,比如
(+ (* 3 (+ (* 2 4) (+ 3 5))) (+ (- 10 7) 6))
而解释器会轻松地将其求值为 57。我们可以通过将这种表达式写成以下形式来帮助自己
(+ (* 3
(+ (* 2 4)
(+ 3 5)))
(+ (- 10 7)
6))
遵循一种称为漂亮打印的格式惯例,其中每个长组合式被写成运算对象垂直对齐的形式。所产生的缩进清晰地展示了表达式的结构。6
即使对于复杂的表达式,解释器总是按照相同的基本循环操作:它从终端读取一个表达式,对该表达式求值,然后打印结果。这种操作模式通常被称为解释器运行在读取-求值-打印循环中。特别要注意,不需要显式地指示解释器打印表达式的值。7
编程语言的一个关键方面是它提供的使用名称来引用计算对象的方式。我们说名称标识了一个变量,其值就是该对象。
在 Lisp 的 Scheme 方言中,我们使用 define 来命名事物。输入
(define size 2)
使解释器将值 2 与名称 size 关联起来。8一旦名称 size 与数字 2 关联,我们就可以通过名称引用值 2:
size
2
(* 5 size)
10
以下是使用 define 的更多示例:
(define pi 3.14159)
(define radius 10)
(* pi (* radius radius))
314.159
(define circumference (* 2 pi radius))
circumference
62.8318
Define 是我们的语言中最简单的抽象手段,因为它允许我们使用简单的名称来引用复合操作的结果,例如上面计算的 circumference。一般来说,计算对象可能具有非常复杂的结构,如果我们每次使用它们时都要记住并重复其细节,那将极端不便。实际上,复杂的程序是通过一步一步地构建越来越复杂的计算对象而构造出来的。解释器使这种逐步的程序构造变得特别方便,因为名称-对象关联可以在连续的交互中增量创建。这一特性鼓励了程序的增量开发和测试,并且在很大程度上解释了Lisp 程序通常由大量相对简单的过程组成这一事实。
显然,将值与符号关联并在以后检索它们的可能性意味着解释器必须维护某种记录名称-对象对的内存。这种内存称为环境(更准确地说是全局环境,因为我们稍后会看到计算可能涉及多个不同的环境)。9
我们本章的目标之一是分离关于程序性思维的问题。作为一个恰当的例子,让我们考虑在求值组合式时,解释器本身也在遵循一个过程。
1. 求值组合式的子表达式。
2. 将最左边的子表达式(运算符)的值所代表的过程应用于其他子表达式(运算对象)的值作为参数。
即使这样简单的规则也说明了关于过程的一些重要点。首先,观察第一步规定,为了完成一个组合式的求值过程,我们必须首先对组合式的每个元素执行求值过程。因此,求值规则本质上是递归的;也就是说,它在其步骤之一中包含了需要调用规则本身。10
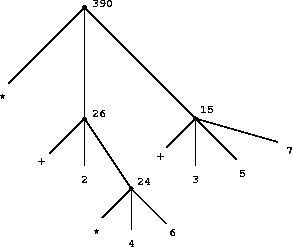
注意递归的思想多么简洁地表达了在深层嵌套组合式情况下原本会被视为相当复杂的过程。例如,求值
(* (+ 2 (* 4 6))
(+ 3 5 7))
要求将求值规则应用于四个不同的组合式。我们可以通过将组合式表示为树的形式来获得这个过程的一个图像,如图 1.1 所示。每个组合式由一个节点表示,从该节点延伸出的分支对应于组合式的运算符和运算对象。终端节点(即没有分支延伸出的节点)表示运算符或数字。从树的角度审视求值,我们可以想象运算对象的值从终端节点开始向上渗透,然后在越来越高的层次上组合。一般来说,我们将看到递归是处理层次性树状对象的一种非常强大的技术。事实上,求值规则的"值向上渗透"形式是一类称为树累积的通用过程的一个实例。
|
|
接下来,观察第一步的重复应用将我们带到需要求值基本表达式(如数字、内建运算符或其他名称)而非组合式的点。我们通过以下规定来处理基本情形:
我们可以将第二条规则视为第三条规则的特例,规定像 + 和 * 这样的符号也包含在全局环境中,并与作为其"值"的机器指令序列相关联。要注意的关键点是环境在确定表达式中符号含义方面的作用。在像 Lisp 这样的交互式语言中,讨论像 (+ x 1) 这样的表达式的值是没有意义的,除非指定了能为符号 x(甚至符号 +)提供含义的环境信息。正如我们将在第 3 章看到的,环境作为求值发生的上下文这一通用概念,将在我们对程序执行的理解中发挥重要作用。
注意上面给出的求值规则并不处理定义。例如,对 (define x 3) 求值并不是将 define 应用于两个参数(一个是符号 x 的值,另一个是 3),因为 define 的目的恰恰是将 x 与一个值关联起来。(也就是说,(define x 3) 不是一个组合式。)
这种对通用求值规则的例外称为特殊形式。Define 是我们到目前为止看到的唯一一个特殊形式的例子,但我们很快就会遇到其他的。每种特殊形式都有自己的求值规则。各种类型的表达式(每种都有其关联的求值规则)构成了编程语言的语法。与其他大多数编程语言相比,Lisp 的语法非常简单;也就是说,表达式的求值规则可以由一个简单的通用规则加上针对少数特殊形式的专用规则来描述。11
我们已经在 Lisp 中识别出任何强大编程语言必须包含的一些要素:
现在我们将学习过程定义,一种更强大的抽象技术,通过它可以将复合操作命名并作为一个单元引用。
我们首先考察如何表达"求平方"的思想。我们可以说:"要平方某个东西,将它乘以自身。"这在我们的语言中表达为
我们可以这样理解:
(define (square x) (* x x))
要平方某个东西,就把它乘以自身。
我们这里有了一个复合过程,被命名为 square。这个过程表示将某个东西乘以自身的操作。要被乘的东西被赋予一个局部名称 x,它扮演着与自然语言中代词相同的角色。对该定义求值将创建这个复合过程并将其与名称 square 关联起来。12
(define (<name> <formal parameters>) <body>)
<名称> 是一个符号,将在环境中与过程定义关联。13 <形式参数> 是在过程体内部用于引用过程对应参数的名称。 <体> 是一个表达式,当形式参数被过程所应用的实际参数替换时,它将产生过程应用的值。 <名称> 和 <形式参数> 被分组在 括号内,就像在对所定义过程的实际调用中一样。
定义了 square 之后,我们现在可以使用它:
(square 21)
441
(square (+ 2 5))
49
(square (square 3))
81
我们也可以使用 square 作为构建块来定义其他过程。例如,x2 + y2 可以表达为
(+ (square x) (square y))
我们可以轻松地定义一个过程 sum-of-squares,给定任意两个数作为参数,它产生它们平方的和:
(define (sum-of-squares x y)
(+ (square x) (square y)))
(sum-of-squares 3 4)
25
现在我们可以使用 sum-of-squares 作为构建块来构造进一步的过程:
(define (f a)
(sum-of-squares (+ a 1) (* a 2)))
(f 5)
136
复合过程的使用方式与基本过程完全相同。事实上,仅通过查看上面给出的 sum-of-squares 的定义,无法判断 square 是像 + 和 * 那样内建在解释器中,还是定义为复合过程。
为了求值运算符命名一个复合过程的组合式,解释器遵循与运算符命名基本过程的组合式(我们在第 1.1.3 节中描述的)大致相同的过程。也就是说,解释器对组合式的元素求值,并将过程(即组合式运算符的值)应用于参数(即组合式运算对象的值)。
我们可以假设将基本过程应用于参数的机制是内建在解释器中的。对于复合过程,应用过程如下:
为了说明这个过程,让我们求值组合式
(f 5)
其中 f 是在第 1.1.4 节中定义的过程。我们首先检索 f 的体:
(sum-of-squares (+ a 1) (* a 2))
然后我们将形式参数 a 替换为参数 5:
(sum-of-squares (+ 5 1) (* 5 2))
因此问题简化为对具有两个运算对象和一个运算符 sum-of-squares 的组合式求值。对这个组合式求值涉及三个子问题。我们必须对运算符求值以得到要应用的过程,并且必须对运算对象求值以得到参数。现在 (+ 5 1) 产生 6,(* 5 2) 产生 10,因此我们必须将 sum-of-squares 过程应用于 6 和 10。这些值被替换为 sum-of-squares 体中的形式参数 x 和 y,将表达式简化为
(+ (square 6) (square 10))
如果我们使用 square 的定义,这简化为
(+ (* 6 6) (* 10 10))
通过乘法简化为
(+ 36 100)
最终得到
136
我们刚刚描述的过程称为过程应用的代换模型。就本章所涉及的过程而言,它可以被视为确定过程应用的"含义"的模型。但有两个要点需要强调:
根据第 1.1.3 节给出的求值描述,解释器首先求值运算符和运算对象,然后将得到的过程应用于得到的参数。这并不是执行求值的唯一方式。另一种求值模型直到需要值时才求值运算对象。相反,它首先将运算对象表达式代换为参数,直到得到只涉及基本运算符的表达式,然后执行求值。 如果我们使用这种方法,
(f 5)
将按照以下展开序列进行
(sum-of-squares (+ 5 1) (* 5 2))
(+ (square (+ 5 1)) (square (* 5 2)) )
(+ (* (+ 5 1) (+ 5 1)) (* (* 5 2) (* 5 2)))
然后进行归约
(+ (* 6 6) (* 10 10))
(+ 36 100)
136
这给出了与之前求值模型相同的答案,但过程不同。特别地,这里 (+ 5 1) 和 (* 5 2) 的求值各执行了两次,对应于表达式的归约
(* x x)
其中 x 分别被替换为 (+ 5 1) 和 (* 5 2)。
这种替代性的"完全展开然后归约"求值方法称为正则序求值,与解释器实际使用的"先求值参数然后应用"方法形成对比,后者称为应用序求值。 可以证明,对于可以使用代换建模(包括本书前两章中的所有过程)并产生合法值的过程应用,正则序和应用序求值产生相同的值。求值不会给出相同结果。)
Lisp 使用应用序求值,部分原因是避免了像上面 (+ 5 1) 和 (* 5 2) 所示的那种表达式的多次求值所带来的额外效率,更重要的是,因为当我们离开可以用代换建模的过程领域时,正则序求值处理起来要复杂得多。 另一方面,正则序求值可以是一种极其有价值的工具,我们将在第 3 章和第 4 章中考察它的一些含义。16
我们在这一点上可以定义的过程类的表达能力非常有限,因为我们无法进行测试并根据测试结果执行不同的操作。 例如,我们不能定义一个过程,通过测试一个数是正数、负数还是零,并根据规则在不同情况下采取不同行动来计算绝对值。
这种构造称为情况分析,Lisp 中有一种特殊形式用于表示这种情况分析。它被称为 cond(代表"条件"),使用方式如下:
(define (abs x)
(cond ((> x 0) x)
((= x 0) 0)
((< x 0) (- x))))
条件表达式的一般形式是
(cond (<p1> <e1>)
(<p2> <e2>)

(<pn> <en>))
由符号 cond 后跟括号对表达式 (<p> <e>) 组成,称为子句。每对中的第一个表达式是一个谓词——即其值被解释为真或假的表达式。17
条件表达式的求值方式如下。首先对谓词 <p1> 求值。如果它的值为假,则对 <p2> 求值。如果 <p2> 的值也为假,则对 <p3> 求值。这个过程持续进行,直到找到值为真的谓词,此时解释器返回该子句的相应结果表达式 <e> 的值作为条件表达式的值。如果没有找到任何 <p> 的值为真,则 cond 的值未定义。
术语谓词用于返回真或假的过程,以及求值结果为真或假的表达式。 绝对值过程 abs 使用基本谓词 >、< 和 =。18这些谓词以两个数为参数,测试第一个数是否分别大于、小于或等于第二个数,并相应地返回真或假。
编写绝对值过程的另一种方式是
(define (abs x)
(cond ((< x 0) (- x))
(else x)))
用中文可以表达为"如果 x 小于零则返回 -x;否则返回 x。"Else 是一个特殊符号,可以在 cond 的最后子句中替代 <p>。这导致每当之前的所有子句都被跳过时,cond 返回相应 <e> 的值作为其值。事实上,任何总是求值为真值的表达式都可以在这里用作 <p>。
这是编写绝对值过程的又一种方式:
(define (abs x)
(if (< x 0)
(- x)
x))
这使用了特殊形式 if,一种受限的条件语句,当情况分析中恰好有两种情况时可以使用。if 表达式的一般形式是
(if <predicate> <consequent> <alternative>)
为了求值 if 表达式,解释器首先求值表达式的<谓词>部分。如果 <谓词> 求值为真值,解释器然后求值<结果>并返回其值。否则它求值<替代>并返回其值。19
除了像 <、= 和 > 这样的基本谓词外,还有逻辑组合操作,使我们能够构造复合谓词。最常用的三种是:
解释器从左到右逐个求值表达式 <e>。如果任何一个 <e> 求值为假,and 表达式的值就是假,其余 <e> 不被求值。如果所有 <e> 都求值为真值,and 表达式的值是最后一个的值。
解释器从左到右逐个求值表达式 <e>。如果任何一个 <e> 求值为真值,该值作为 or 表达式的值返回,其余 <e> 不被求值。如果所有 <e> 都求值为假,or 表达式的值是假。
not 表达式的值在表达式 <e> 求值为假时为真,否则为假。
注意 and 和 or 是特殊形式,不是过程,因为子表达式不一定都被求值。Not 是普通过程。
作为这些用法的一个例子,数 x 在区间 5 < x < 10 的条件可以表达为
(and (> x 5) (< x 10))
另一个例子是,我们可以定义一个谓词来测试一个数是否大于或等于另一个数:
(define (>= x y)
(or (> x y) (= x y)))
或者也可以定义为
(define (>= x y)
(not (< x y)))
练习 1.1. 下面是一个表达式序列。解释器对每个表达式打印的结果是什么?假设序列按照呈现的顺序求值。
10
(+ 5 3 4)
(- 9 1)
(/ 6 2)
(+ (* 2 4) (- 4 6))
(define a 3)
(define b (+ a 1))
(+ a b (* a b))
(= a b)
(if (and (> b a) (< b (* a b)))
b
a)
(cond ((= a 4) 6)
((= b 4) (+ 6 7 a))
(else 25))
(+ 2 (if (> b a) b a))
(* (cond ((> a b) a)
((< a b) b)
(else -1))
(+ a 1))
练习 1.3. 定义一个以三个数为参数的过程,返回两个较大数的平方和。
练习 1.4. 观察到我们的求值模型允许运算符为复合表达式的组合式。利用这一观察,描述以下过程的行为:
(define (a-plus-abs-b a b)
((if (> b 0) + -) a b))
练习 1.5. Ben Bitdiddle 发明了一个测试来确定他面对的解释器是使用应用序求值还是正则序求值。他定义了以下两个过程:
(define (p) (p))
(define (test x y)
(if (= x 0)
0
y))
然后他求值表达式
(test 0 (p))
Ben 在使用应用序求值的解释器上会观察到什么行为?在使用正则序求值的解释器上会观察到什么行为?解释你的答案。(假设特殊形式 if 的求值规则在解释器使用正则序或应用序时相同:先求值谓词表达式,结果决定是求值结果表达式还是替代表达式。)
如上所述,过程很像普通的数学函数。它们指定一个由一個或多个参数确定的值。但数学函数和计算机过程之间有一个重要区别。过程必须是有效的。
作为一个恰当的例子,考虑计算平方根的问题。我们可以将平方根函数定义为
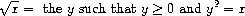
这描述了一个完全合法的数学函数。我们可以用它来识别一个数是否是另一个数的平方根,或者推导关于平方根的一般事实。另一方面,这个定义并没有描述一个过程。事实上,它几乎没有告诉我们如何实际找到一个给定数的平方根。用伪 Lisp 改写这个定义也无济于事:
(define (sqrt x)
(the y (and (>= y 0)
(= (square y) x))))
这只是在回避问题。
函数与过程之间的对比反映了描述事物属性和描述如何做事情之间的一般区别,或者有时被称为声明性知识与命令性知识的区别。在数学中,我们通常关注声明性的(是什么)描述,而在计算机科学中,我们通常关注命令性的(如何做)描述。20
如何计算平方根?最常用的方法是牛顿的逐次逼近法,即每当我们有一个数 x 的平方根的猜测值 y 时,我们可以通过将 y 与 x/y 平均来执行一个简单的操作,得到一个更好的猜测(更接近实际平方根)。21 例如,我们可以按如下方式计算 2 的平方根。假设我们的初始猜测为 1:
| 猜测 | 商 | 平均 |
| 1 | (2/1) = 2 | ((2 + 1)/2) = 1.5 |
| 1.5 | (2/1.5) = 1.3333 | ((1.3333 + 1.5)/2) = 1.4167 |
| 1.4167 | (2/1.4167) = 1.4118 | ((1.4167 + 1.4118)/2) = 1.4142 |
| 1.4142 | ... | ... |
继续这个过程,我们得到越来越好的平方根近似值。
现在让我们用过程来形式化这个过程。我们从被开方数(我们试图计算平方根的数)的值和猜测值开始。如果猜测对我们的目的来说足够好,我们就完成了;如果不是,我们必须用改进的猜测重复这个过程。我们将这个基本策略写成一个过程:
(define (sqrt-iter guess x)
(if (good-enough? guess x)
guess
(sqrt-iter (improve guess x)
x)))
通过将猜测与被开方数除以旧猜测的商进行平均来改进猜测:
(define (improve guess x)
(average guess (/ x guess)))
其中
(define (average x y)
(/ (+ x y) 2))
我们还必须说明"足够好"的含义。下面的方法可以用来说明,但并不是一个很好的测试。(见练习 1.7。) 其思想是改进答案,直到它足够接近,使其平方与被开方数的差小于一个预定的容差(这里为 0.001):22
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001))
最后,我们需要一种开始的方法。例如,我们总是可以猜测任何数的平方根为 1:23
(define (sqrt x)
(sqrt-iter 1.0 x))
如果我们将这些定义输入解释器,就可以像使用任何过程一样使用 sqrt:
(sqrt 9)
3.00009155413138
(sqrt (+ 100 37))
11.704699917758145
(sqrt (+ (sqrt 2) (sqrt 3)))
1.7739279023207892
(square (sqrt 1000))
1000.000369924366
sqrt 程序也说明,我们迄今介绍的简单过程语言足以编写人们用 C 或 Pascal 等语言编写的任何纯数值程序。 这可能看起来令人惊讶,因为我们的语言中没有包含任何指示计算机反复做某事的迭代(循环)构造。而另一方面,Sqrt-iter 展示了如何仅使用调用过程的普通能力,而不需要任何特殊构造来实现迭代。24
练习 1.6. Alyssa P. Hacker 不明白为什么 if 需要作为特殊形式提供。"为什么我不能简单地用 cond 将其定义为普通过程?"她问道。Alyssa 的朋友 Eva Lu Ator 声称这确实可以做到,她定义了一个新版本的 if:
(define (new-if predicate then-clause else-clause)
(cond (predicate then-clause)
(else else-clause)))
Eva 向 Alyssa 演示了这个程序:
(new-if (= 2 3) 0 5)
5
(new-if (= 1 1) 0 5)
0
很高兴的 Alyssa 使用 new-if 重写了平方根程序:
(define (sqrt-iter guess x)
(new-if (good-enough? guess x)
guess
(sqrt-iter (improve guess x)
x)))
当 Alyssa 尝试用这个程序计算平方根时会发生什么?请解释。
练习 1.7. 在计算平方根中使用的 good-enough? 测试对于求非常小的数的平方根效果不佳。此外,在真实计算机中,算术运算几乎总是以有限精度执行的。这使得我们的测试对于非常大的数也不够用。用例子解释这些说法,展示测试如何对小和大数失效。实现 good-enough? 的另一种策略是观察 guess 在每次迭代之间的变化,当变化是猜测的一个非常小的部分时停止。设计一个使用这种结束测试的平方根过程。这对小和大数效果更好吗?
练习 1.8. 牛顿的立方根方法基于如下事实:如果 y 是 x 的立方根的近似值,那么更好的近似值由以下公式给出
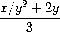
使用这个公式实现一个类似于平方根过程的立方根过程。(在第 1.3.4 节中,我们将看到如何将牛顿法实现为这些平方根和立方根过程的通用抽象。)
Sqrt 是我们第一个由一组相互定义的过程所定义的过程的实例。注意 sqrt-iter 的定义是 递归的;也就是说,该过程是根据自身定义的。能够根据自身定义过程的想法可能令人不安;似乎不清楚这样的一种"循环"定义怎么可能有任何意义,更不用说指定一个由计算机执行的明确定义的过程了,更不用说指定一个由计算机执行的明确定义的过程了。这个问题将在第 1.2 节更仔细地讨论。但首先让我们考虑 sqrt 示例所说明的其他一些重要点。
观察到计算平方根的问题自然地分解为若干子问题:如何判断一个猜测是否足够好,如何改进猜测,等等。这些任务中的每一个都由一个单独的过程完成。整个 sqrt 程序可以看作一个过程簇(如图 1.2 所示),它反映了问题分解为子问题的结构。
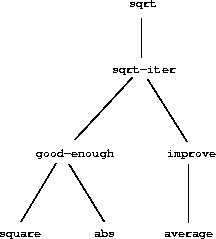
|
这种分解策略的重要性不仅仅在于将程序划分成部分。毕竟,我们可以将任何大型程序划分成部分——前十行、接下来十行、再接下来十行,等等。相反,关键在于 每个过程完成一个可识别的任务,可以作为模块用于定义其他过程。例如,当我们用 square 定义 good-enough? 过程时,我们能够将 square 过程视为一个"黑箱"。我们此时不关心过程如何计算其结果,只关心它能计算平方。平方如何计算的细节可以被隐藏,留待以后考虑。实际上,就 good-enough? 过程而言,square 不完全是过程,而是过程的抽象,一种所谓的过程抽象。 在这个抽象层次上,任何计算平方的过程都同样好。
因此,仅考虑它们返回的值时,以下两个求一个数平方的过程应该是无法区分的。每个过程接受一个数值参数,并产生该数的平方作为值。25
(define (square x) (* x x))
(define (square x)
(exp (double (log x))))
(define (double x) (+ x x))
因此,过程定义应该能够隐藏细节。过程的使用者可能不是自己编写这个过程,而是从其他程序员那里将其作为黑箱获得的。使用者不需要知道过程是如何实现的才能使用它。
过程的实现中一个不应影响过程使用者的细节是,实现者为过程的形式参数选择的名称。 Thus, the following procedures should not be distinguishable:
(define (square x) (* x x))
(define (square y) (* y y))
这个原理——过程的意义应该独立于其作者使用的参数名称——表面上看是不言自明的,但其后果是深远的。最简单的后果是过程的参数名必须局限于过程体内部。 例如,在我们的平方根过程中,我们在 good-enough? 的定义中使用了 square:
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001))
good-enough? 的作者意图是确定第一个参数的平方是否在给定容差内接近第二个参数。 我们看到 good-enough? 的作者使用名称 guess 引用第一个参数,使用 x 引用第二个参数。square 的参数是 guess。如果 square 的作者使用 x(如上所示)来引用该参数,我们看到 good-enough? 中的 x 必须与 square 中的 x 不同。运行过程 square 不得影响 good-enough? 使用的 x 的值, 因为 square 计算完成后,good-enough? 可能还需要该 x 的值。
如果参数不局限于各自过程体内部,那么 square 中的参数 x 就会与 good-enough? 中的参数 x 混淆,good-enough? 的行为将取决于我们使用哪个 square 版本。因此,square 将不是我们想要的黑箱。
过程的形式参数在过程定义中有一个非常特殊的角色,即形式参数的名称是什么并不重要。这样的名称称为约束变量,我们说过程定义绑定了其形式参数。 如果在整个定义中一致地重命名约束变量,过程定义的含义不变。26 如果变量不是被绑定的,我们说它是自由的。绑定定义名称的一组表达式称为该名称的作用域。在过程定义中,声明为过程形式参数的约束变量以过程体作为它们的作用域。
在上面 good-enough? 的定义中,guess 和 x 是约束变量,而 <、-、abs 和 square 是自由的。 good-enough? 的含义应该独立于我们为 guess 和 x 选择的名称,只要它们与 <、-、abs 和 square 不同且彼此不同即可。 (如果我们将 guess 重命名为 abs,就会因 捕获变量 abs 而引入一个错误。它将从自由变为约束。)然而,good-enough? 的含义并非独立于其自由变量的名称。它确实依赖于(该定义外部的)符号 abs 命名了一个计算数绝对值的函数这一事实。如果在定义中用 cos 替换 abs,good-enough? 将计算一个不同的函数。
我们目前有一种名称隔离可用:过程的形式参数局限于过程体内部。平方根程序说明了我们希望控制名称使用的另一种方式。现有程序由几个独立的过程组成:
(define (sqrt x)
(sqrt-iter 1.0 x))
(define (sqrt-iter guess x)
(if (good-enough? guess x)
guess
(sqrt-iter (improve guess x) x)))
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001))
(define (improve guess x)
(average guess (/ x guess)))
这个程序的问题是,对 sqrt 的用户来说唯一重要的过程是 sqrt。其他过程(sqrt-iter、good-enough? 和 improve)只会干扰他们的思维。他们不能定义另一个名为 good-enough? 的过程作为另一个程序的一部分来与平方根程序协同工作,因为 sqrt 需要它。这个问题在由多个独立程序员构建大型系统时尤为严重。例如,在构建一个大型数值过程库时,许多数值函数是通过逐次逼近计算的,因此可能有用 good-enough? 和 improve 作为辅助过程的同名过程。 我们希望通过将子过程局部化,将它们隐藏在 sqrt 内部,使得 sqrt 可以与其他逐次逼近过程共存,每个都有自己的私有 good-enough? 过程。为了实现这一点,我们允许过程拥有对该过程来说是局部的内部定义。例如,在平方根问题中我们可以写
(define (sqrt x)
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001))
(define (improve guess x)
(average guess (/ x guess)))
(define (sqrt-iter guess x)
(if (good-enough? guess x)
guess
(sqrt-iter (improve guess x) x)))
(sqrt-iter 1.0 x))
这种定义的嵌套称为块结构,基本上是最简单的名称包装问题的正确解决方案。但这里潜伏着一个更好的想法。除了将辅助过程的定义内化之外,我们还可以简化它们。由于 x 在 sqrt 的定义中被绑定,在 sqrt 内部定义的 good-enough?、improve 和 sqrt-iter 过程都在 x 的作用域中。因此,不需要显式地将 x 传递给这些过程中的每一个。相反,我们允许 x 成为内部定义中的 自由变量,如下所示。然后 x 从调用外围过程 sqrt 的参数中获得其值。这种规则称为 词法作用域。27
(define (sqrt x)
(define (good-enough? guess)
(< (abs (- (square guess) x)) 0.001))
(define (improve guess)
(average guess (/ x guess)))
(define (sqrt-iter guess)
(if (good-enough? guess)
guess
(sqrt-iter (improve guess))))
(sqrt-iter 1.0))
我们将广泛使用块结构来帮助我们将大型程序分解为易于处理的部分。28 块结构的思想起源于编程语言 Algol 60。它出现在大多数高级编程语言中,是帮助组织大型程序构建的重要工具。
4 将数字描述为"简单数据"是赤裸裸的虚张声势。实际上,数字的处理是任何编程语言中最棘手和最令人困惑的方面之一。涉及的一些典型问题是这样的:有些计算机系统区分整数(如 2)和实数(如 2.71)。实数 2.00 与整数 2 不同吗?用于整数的算术运算与用于实数的算术运算相同吗?6 除以 2 产生 3 还是 3.0?我们能表示多大的数?我们能表示多少位小数的精度? 整数与实数的范围相同吗?当然,在这些问题之上还存在关于舍入和截断误差的一系列问题——即整个数值分析科学。由于本书的重点是大规模程序设计而非数值技术,我们将忽略这些问题。本章中的数值示例将展示在非整数运算中使用保留有限小数位精度的算术运算时观察到的通常的舍入行为。
5 在本书中,当我们希望强调用户输入和解释器打印的响应之间的区别时,我们将以后者用斜体字符显示。
6 Lisp 系统通常提供帮助用户格式化表达式的功能。两个特别有用的功能是:每当新行开始时自动缩进到适当的漂亮打印位置,以及每当输入右括号时高亮显示匹配的左括号。
7 Lisp 遵循每个表达式都有值的约定。这个约定,加上 Lisp 作为一种低效语言的古老名声,是 Alan Perlis(改写 Oscar Wilde 的话)那句俏皮话的源头:“Lisp 程序员知道一切的价值,却什么也不知道成本。”。
8 在本书中,我们不显示解释器对求值定义的响应,因为这高度依赖于实现。
9 第 3 章将表明,环境的概念对于理解解释器的工作方式和实现解释器都至关重要。
10 求值规则在第一步中说我们应该求值组合式的最左边元素,这可能看起来很奇怪,因为在这一点上它只能是像 + 或 * 这样的运算符,表示像加法或乘法这样的内建基本过程。我们稍后将看到能够处理运算符本身就是复合表达式的组合式是很有用的。
11 那些只是可以用更统一的方式书写的东西的方便替代表层结构的特殊语法形式,有时被称为 语法糖,这是借用 Peter Landin 创造的一个短语。与其他语言的用户相比,Lisp 程序员通常不太关心语法问题。(相比之下,检查任何 Pascal 手册,注意有多少内容专门用于描述语法。)这种对语法的轻视部分归因于 Lisp 的灵活性,使改变表层语法变得容易,部分归因于观察到许多使语言不太统一的“方便”语法构造,当程序变得庞大和复杂时,最终带来的麻烦超过了它们的价值。用 Alan Perlis 的话说:“语法糖导致分号癌。”
12 注意这里组合了两个不同的操作:我们在创建过程,并为其赋予名称 square。能够分离这两个概念——创建过程而不命名它们,以及为已经创建的过程赋予名称——是可能的,实际上也是重要的。让我们能够分离这两个概念——创建过程而不命名它们,以及为已经创建的过程赋予名称。我们将在第 1.3.2 节看到如何做到这一点。
13 在本书中,我们将使用尖括号界定的斜体符号——例如 <名称>——来描述表达式的一般语法,以表示在实际使用这类表达式时表达式中需要填充的"槽"。
14 更一般地,过程体可以是一个表达式序列。在这种情况下,解释器依次求值序列中的每个表达式,并返回最终表达式的值作为过程应用的值。
15 尽管代换思想很简单,但给出代换过程的严格数学定义却惊人地复杂。问题源于过程的形式参数所使用的名称与过程可能应用于的表达式中使用的(可能相同的)名称之间可能产生混淆。事实上,在逻辑学和编程语义学的文献中,对于代换的错误定义有着长久的历史。参见 Stoy 1977 对代换的详细讨论。
16 在第 3 章中,我们将介绍流处理,这是一种通过结合有限形式的正则序求值来处理表面上“无限”数据结构的方式。在第 4.2 节中,我们将修改 Scheme 解释器以产生 Scheme 的正则序变体。
17 "解释为真或假"意味着:在 Scheme 中,有两个由常量 #t 和 #f 表示的特殊的真值。当解释器检查谓词的值时,它将 #f 解释为假。任何其他值都被视为真。(因此,提供 #t 在逻辑上是不必要的,但很方便。)在本书中,我们将使用名称 true 和 false,它们分别与值 #t 和 #f 关联。
18 Abs 也使用"负号"运算符 -,当与单个运算对象一起使用时,如 (- x),表示取反。
19 if 和 cond 之间的一个小区别在于,每个 cond 子句的 <e> 部分可以是一个表达式序列。如果找到对应的 <p> 为真,则依次求值表达式 <e>,序列中最终表达式的值作为 cond 的值返回。然而,在 if 表达式中,<结果> 和 <替代> 必须是单个表达式。
20 声明性描述和命令性描述是密切相关的,数学和计算机科学也是如此。例如,说程序产生的答案是 "正确"的就是对程序做了一个声明性陈述。有大量的研究致力于建立证明程序正确性的技术,这个主题的大部分技术难度与处理命令性语句(程序由之构建)和声明性语句(可用于推导事物)之间的过渡有关。与此相关,编程语言设计的一个重要当前领域是探索所谓的超高级语言,在這種语言中人们实际上根据声明性语句进行编程。其思想是使解释器足够复杂,以至于给定由程序员指定的"是什么"知识,它们可以自动生成"如何做"知识。一般无法做到这一点,但在重要领域中已经取得了进展。我们将在第 4 章重新讨论这个想法。
21 这个平方根算法实际上是牛顿法的一个特例,牛顿法是一种求方程根的通用技术。平方根算法本身是由亚历山大港的 Heron 在公元一世纪提出的。我们将在第 1.3.4 节看到如何将通用牛顿法表达为 Lisp 过程。
22 我们通常给谓词的名字以问号结尾,以帮助我们记住它们是谓词。这只是一种风格约定。就解释器而言,问号只是一个普通字符。
23 注意我们将初始猜测表示为 1.0 而不是 1。这在许多 Lisp 实现中不会产生任何区别。 然而,MIT Scheme 区分精确整数和小数值,两个整数相除会产生有理数而不是小数。例如,10 除以 6 产生 5/3,而 10.0 除以 6.0 产生 1.6666666666666667。(我们将在第 2.1.1 节学习如何实现有理数的算术运算。)如果在我们的平方根程序中以初始猜测 1 开始,且 x 是精确整数,则平方根计算中产生的所有后续值将是有理数而非小数。有理数和小数的混合运算总是产生小数,因此以初始猜测 1.0 开始会迫使所有后续值为小数。
24 担心使用过程调用来实现迭代所涉及效率问题的读者,应注意第 1.2.1 节关于“尾递归”的论述。
25 甚至不清楚这些过程中哪一个效率更高。这取决于可用的硬件。有些机器上“显而易见”的实现反而是效率较低的。考虑一台以非常高效的方式存储了大量对数和反对数表的机器。
26 一致重命名的概念实际上很微妙且难以形式化定义。著名的逻辑学家在这里犯过令人尴尬的错误。
27 词法作用域规定过程中的自由变量被认为引用由外围过程定义建立的绑定;也就是说,它们在定义该过程的环境中查找。我们将在第 3 章学习环境和解释器的详细行为时,详细看到这是如何工作的。
28 嵌入的定义必须放在过程体的最前面。管理层对运行交织定义和使用的程序的后果不负责任。