
|
我们现在已经考察了程序设计的基本元素:我们使用了基本算术运算,组合了这些运算,并通过将它们定义为复合过程来抽象了这些复合操作。但这还不足以让我们说我们知道如何编程。 我们的处境类似于某人学会了国际象棋棋子如何移动的规则,但对典型的开局、战术或策略一无所知。像初学棋手一样,我们还不知道领域中的常见使用模式。我们缺乏哪些走法是值得的(哪些过程是值得定义的)的知识。我们缺乏预测走棋(执行过程)后果的经验。
能够可视化所考虑行动的后果对于成为专家程序员至关重要,就像在任何综合性、创造性的活动中一样。例如,在成为专家摄影师的过程中,一个人必须学会如何观察一个场景,并知道在每个可能的曝光和显影条件选择下,每个区域在照片上会有多暗。只有在那之后,人们才能反向推理,规划构图、光照、曝光和显影以获得期望的效果。编程也是如此,我们在其中规划过程要采取的行动过程,并通过程序控制过程。要成为专家,我们必须学会可视化各种类型过程所产生的计算过程。只有在我们发展了这样的技能之后,我们才能学会可靠地构造出展示所期望行为的程序。
过程是计算过程的局部演化模式。它指定了过程的每个阶段如何建立在前一阶段之上。我们希望能够对过程(其局部演化已由过程指定)的总体或全局行为做出陈述。一般来说这非常困难,但至少我们可以尝试描述一些典型的过程演化模式。
在本节中,我们将考察由简单过程生成的过程的一些常见"形状"。我们还将研究这些过程消耗时间和空间等重要计算资源的速率。 我们将考虑的过程非常简单。它们的作用类似于摄影中的测试图样:作为过度简化的原型模式,而非本身具有实用价值的实例。
|
|
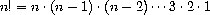
有许多计算阶乘的方法。一种方法是利用这样的观察:对于任何正整数 n,n! 等于 n 乘以 (n - 1)!:
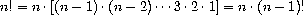
因此,我们可以通过计算 (n - 1)! 并将结果乘以 n 来计算 n!。如果我们加上 1! 等于 1 的约定,这个观察直接转化为一个过程:
(define (factorial n)
(if (= n 1)
1
(* n (factorial (- n 1)))))
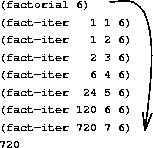
我们可以使用第 1.1.5 节的代换模型来观察这个计算 6! 的过程的实际运行,如图 1.3 所示。
现在让我们换一个角度来考察阶乘计算。我们可以通过指定先 1 乘以 2,然后将结果乘以 3,再乘以 4,依此类推直到达到 n 来描述计算 n! 的规则。 更形式化地说,我们维护一个累积乘积和一个从 1 计数到 n 的计数器。我们可以这样描述计算:计数器和乘积按照以下规则同时从一步变化到下一步
product  counter · product
counter · product
counter counter + 1
并规定当计数器超过 n 时,n! 就是乘积的值。
|
同样,我们可以将我们的描述重新表述为计算阶乘的过程:29
(define (factorial n)
(fact-iter 1 1 n))
(define (fact-iter product counter max-count)
(if (> counter max-count)
product
(fact-iter (* counter product)
(+ counter 1)
max-count)))
同样,我们可以用代换模型来可视化计算 6! 的过程,如图 1.4 所示。
计算 6! 的过程,如图 1.4 所示。
比较这两个过程。从一个角度看,它们似乎几乎没有区别。两者都在相同域上计算相同的数学函数,每个都需要与 n 成比例的步数来计算 n!。实际上,两个过程甚至执行相同的乘法序列,得到相同的部分乘积序列。另一方面,当我们考虑两个过程的 "形状"时,我们发现它们的演化方式完全不同。
考虑第一个过程。代换模型揭示了一个先展开后收缩的形状,由图 1.3 中的箭头指示。展开发生在过程建立一列 延迟操作(在此例中是乘法链)时。收缩发生在操作实际执行时。这种以延迟操作链为特征的过程称为 递归过程。执行这个过程需要解释器跟踪稍后要执行的操作。在计算 n! 时,延迟乘法链的长度,以及因此跟踪它所需的信息量,随 n 线性增长(与 n 成正比),就像步数一样。这样的过程称为 线性递归过程。
相比之下,第二个过程不增长也不收缩。在每一步,对于任何 n,我们需要跟踪的只是变量 product、counter 和 max-count 的当前值。我们称此为 迭代过程。一般来说,迭代过程是其状态可以由固定数量的 状态变量 总结的过程,加上描述状态变量如何在过程从状态到状态移动时更新的固定规则,以及(可选的)指定过程应终止条件的结束测试。在计算 n! 时,所需步数随 n 线性增长。这样的过程称为 线性迭代过程。
这两个过程之间的对比可以从另一个角度看到。在迭代情况下,程序变量在任何点都提供了过程状态的完整描述。如果我们在步骤之间停止计算,要恢复计算所需做的只是向解释器提供三个程序变量的值。递归过程则不然。在这种情况下,存在一些额外的"隐藏"信息,由解释器维护且不包含在程序变量中,这些信息指示过程在处理延迟操作链时"所处的位置"。链越长,必须维护的信息就越多。30
在对比迭代和递归时,我们必须注意不要混淆 递归过程的概念和递归计算过程的概念。当我们描述一个过程是递归时,我们指的是过程定义引用(直接或间接)过程本身的语法事实。但当我们描述一个过程遵循例如线性递归的模式时,我们指的是过程如何演化,而不是过程如何编写的语法。我们称像 fact-iter 这样的递归过程产生一个迭代过程,这可能看起来令人困惑。然而,该计算过程确实是迭代的:其状态完全由三个状态变量捕获,解释器只需跟踪三个变量即可执行该过程。
过程与计算过程之间的区别可能令人困惑的一个原因是,大多数常见语言(包括 Ada、Pascal 和 C)的实现是以这样一种方式设计的:任何递归过程的解释都会消耗随过程调用次数增长的内存,即使所描述的过程原则上是迭代的。因此,这些语言只能求助于专门的 "循环构造"如 do、repeat、until、for 和 while 来描述迭代过程。我们将在第 5 章考察的 Scheme 实现没有这个缺陷。它将在恒定空间中执行迭代过程,即使迭代过程是由递归过程描述的。具有这种属性的实现称为 尾递归的。有了尾递归实现,迭代可以使用普通的过程调用机制来表达,这样特殊的迭代构造只作为 语法糖才有用。31
练习 1.9. 以下两个过程中的每一个都定义了一种用过程 inc(将参数加 1)和 dec(将参数减 1)来求两个正整数和的方法。
(define (+ a b)
(if (= a 0)
b
(inc (+ (dec a) b))))
(define (+ a b)
(if (= a 0)
b
(+ (dec a) (inc b))))
使用代换模型,说明每个过程在求值 (+ 4 5) 时生成的过程。这些过程是迭代的还是递归的?
练习 1.10. 下面的过程计算一个称为阿克曼函数的数学函数。
(define (A x y)
(cond ((= y 0) 0)
((= x 0) (* 2 y))
((= y 1) 2)
(else (A (- x 1)
(A x (- y 1))))))
以下表达式的值是什么?
(A 1 10)
(A 2 4)
(A 3 3)
考虑以下过程,其中 A 是上面定义的过程:
(define (f n) (A 0 n))
(define (g n) (A 1 n))
(define (h n) (A 2 n))
(define (k n) (* 5 n n))
给出由过程 f、g 和 h 对正整数 n 计算的函数的简洁数学定义。例如,(k n) 计算 5n2。
另一种常见的计算模式称为树形递归。作为例子,考虑计算斐波那契数序列,其中每个数是前两个数之和:
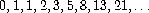
一般来说,斐波那契数可由以下规则定义:
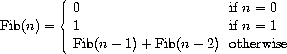
我们可以立即将这个定义翻译成计算斐波那契数的递归过程:
(define (fib n)
(cond ((= n 0) 0)
((= n 1) 1)
(else (+ (fib (- n 1))
(fib (- n 2))))))
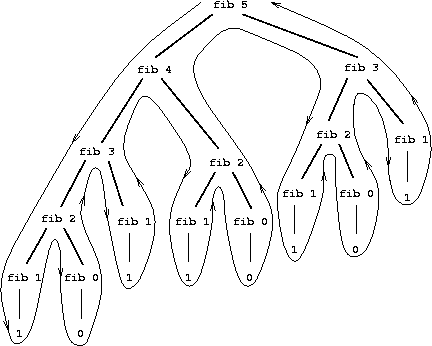
|
考虑这个计算模式。为了计算 (fib 5),我们计算 (fib 4) 和 (fib 3)。为了计算 (fib 4),我们计算 (fib 3) 和 (fib 2)。一般来说,演化出的过程看起来像一棵树,如图 1.5 所示。 注意分支在每一层都分成两叉(底部除外);这反映了 fib 过程每次被调用时都会调用自身两次的事实。
这个过程作为典型的树形递归具有启发性,但它是计算斐波那契数的一种可怕方法,因为它做了太多冗余计算。 注意在图 1.5 中,(fib 3) 的整个计算——几乎一半的工作——被重复了。事实上,不难证明该过程计算 (fib 1) 或 (fib 0) 的次数(一般来说,上面树中的叶子数)正好是 Fib(n + 1)。 要了解这有多糟糕,可以证明Fib(n) 的值 随 n 指数增长。更精确地说
(见练习 1.13),Fib(n) 是最接近
整数 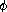 n /
n /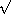 5,其中
5,其中
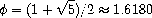
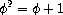
因此,该过程使用的步数随输入指数增长。另一方面,所需空间仅随输入线性增长,因为在计算的任何时刻我们只需跟踪树中哪些节点在我们上方。 随输入增长。另一方面,所需空间仅 一般来说,树形递归过程所需的步数与树中的节点数成正比,而所需的空间与树的最大深度成正比。 一般来说,树形递归过程所需的步数与树中的节点数成正比,而所需的空间与树的最大深度成正比。
我们也可以设计一个迭代过程来计算斐波那契数。其思想是使用一对整数 a 和 b,初始化为 Fib(1) = 1 和 Fib(0) = 0,然后反复应用同步变换
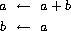
不难证明,在应用这个变换 n 次后,a 和 b 将分别等于 Fib(n + 1) 和 Fib(n)。因此,我们可以使用以下过程迭代地计算斐波那契数:
(define (fib n)
(fib-iter 1 0 n))
(define (fib-iter a b count)
(if (= count 0)
b
(fib-iter (+ a b) a (- count 1))))
这第二种计算 Fib(n) 的方法是线性迭代。两种方法所需步数的差异——一个关于 n 线性增长,一个与 Fib(n) 本身一样快——即使对于小输入也是巨大的。
我们不应该由此得出结论认为树形递归过程是无用的。当我们考虑对层次结构数据而非数字进行操作的过程时,我们会发现树形递归是一种自然且强大的工具。32 但即使在数值运算中,树形递归过程也有助于我们理解和设计程序。例如,尽管第一个 fib 过程比第二个低效得多,但它更直接,几乎只是将斐波那契数列的定义翻译成 Lisp 而已。而设计迭代算法则需要注意到计算可以被重新表述为具有三个状态变量的迭代。
只需一点聪明才智就能想出迭代的 Fibonacci 算法。相反,考虑以下问题: Fibonacci 算法。相反,考虑以下问题:有多少种不同的方式可以用 50 美分、25 美分、10 美分、5 美分和 1 美分硬币兑换 1 美元?更一般地,我们能编写一个过程来计算兑换任意给定金额的方式数吗?
这个问题有一个简单的递归过程解法。假设我们将可用的硬币类型按某种顺序排列。那么以下关系成立:
用 n 种硬币兑换金额 a 的方式数等于
要理解这是正确的,观察到兑换方式可以分为两组:不使用第一种硬币的和使用第一种硬币的。因此,兑换某个金额的总方式数等于不使用第一种硬币兑换该金额的方式数,加上假设我们使用第一种硬币的方式数。但后者等于在使用了一枚第一种硬币后,兑换剩余金额的方式数。
因此,我们可以递归地将兑换给定金额的问题归约为用更少种类硬币兑换更小金额的问题。仔细考虑这个归约规则,并确信如果我们指定以下退化情形,我们可以用它来描述一个算法:33
我们可以轻松地将这个描述翻译成一个递归过程:
(define (count-change amount)
(cc amount 5))
(define (cc amount kinds-of-coins)
(cond ((= amount 0) 1)
((or (< amount 0) (= kinds-of-coins 0)) 0)
(else (+ (cc amount
(- kinds-of-coins 1))
(cc (- amount
(first-denomination kinds-of-coins))
kinds-of-coins)))))
(define (first-denomination kinds-of-coins)
(cond ((= kinds-of-coins 1) 1)
((= kinds-of-coins 2) 5)
((= kinds-of-coins 3) 10)
((= kinds-of-coins 4) 25)
((= kinds-of-coins 5) 50)))
(first-denomination 过程以可用硬币种类数为输入,返回第一种硬币的面额。这里我们认为硬币是按从大到小排列的,但任何顺序都可以。)我们现在可以回答关于兑换一美元的原始问题了:
(count-change 100)
292
Count-change 生成一个树形递归过程,与我们第一个 fib 实现中的冗余类似。(计算那 292 需要相当长的时间。)另一方面,如何设计更好的算法来计算结果并不明显,我们把这个难题留作挑战。树形递归过程可能效率很低但通常容易指定和理解,这一观察使人们提出可以通过设计"智能编译器"两全其美,将树形递归过程转化为计算相同结果的更高效过程。34
练习 1.11. A function f is defined by the rule that f(n) = n if n<3 and f(n) = f(n - 1) + 2f(n - 2) + 3f(n - 3) if n> 3. Write a procedure that 编写一个通过递归过程计算 f 的过程。编写一个通过迭代过程计算 f 的过程。 computes f by means of an iterative process.
练习 1.12. The following pattern of numbers is called Pascal's triangle.
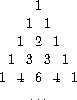
The numbers at the edge of the triangle are all 1, and each number inside the triangle is the sum of the two numbers above it.35 编写一个通过递归过程计算杨辉三角元素的过程。 of a recursive process.
练习 1.13. Prove that Fib(n) is the closest integer to n/5,
where = (1 + 5)/2. Hint: Let 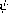 = (1 - 5)/2. Use
提示:使用归纳法和斐波那契数的定义(见第 1.2.2 节)证明 Fib(n) = (n - n)/5,其中 = (1 - 5)/2。
section 1.2.2) to prove that Fib(n) = (n
- n)/5.
= (1 - 5)/2. Use
提示:使用归纳法和斐波那契数的定义(见第 1.2.2 节)证明 Fib(n) = (n - n)/5,其中 = (1 - 5)/2。
section 1.2.2) to prove that Fib(n) = (n
- n)/5.
前面的示例说明,过程消耗计算资源的速率可能有很大差异。描述这种差异的一种便捷方式是使用 增长的阶 的概念,来获得输入变大时过程所需 资源的粗略度量。
令 n 为度量问题规模的参数,R(n) 为过程对规模 n 的问题所需资源的量。 In our previous examples we took n to be the number possibilities. For instance, if our goal is to compute an approximation to the square root of a number, we might take n to be 所需的精度位数。对于矩阵乘法,我们可以将 n 取为矩阵的行数。一般来说,问题有许多属性,我们会期望根据它们来分析给定的过程。类似地,R(n) 可以衡量使用的内部存储寄存器数量、执行的基本机器操作数量等。在每次只执行固定数量操作的计算机中,所需时间与执行的基本机器操作数量成正比。
我们称 R(n) 具有增长的阶 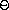 (f(n)),记作
R(n) = (f(n)) (pronounced ``theta of f(n)''), if there are
与 n 无关的正常数 k1 和 k2,使得
(f(n)),记作
R(n) = (f(n)) (pronounced ``theta of f(n)''), if there are
与 n 无关的正常数 k1 和 k2,使得
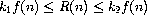
对于任何足够大的 n 值成立。(换句话说,对于大的 n,值 R(n) 被夹在 k1f(n) 和 k2f(n) 之间。)
例如,对于第 1.2.1 节中描述的阶乘的线性递归过程,
factorial described in section 1.2.1 the
步数与输入 n 成正比。因此,
该过程所需的步数增长为 (n)。我们还看到
所需空间增长为 (n)。对于 iterative
迭代阶乘,步数仍然是 (n),但空间为
(1)——即常数。36 The tree-recursive Fibonacci computation requires
树形递归的斐波那契计算需要 (n) 步和空间 (n),其中 是第
第 1.2.2 节中描述的黄金比例。
增长的阶只提供了对过程行为的粗略描述。例如,需要 n2 步、需要 1000n2 步和需要 3n2 + 10n + 17 步的过程都具有 (n2) 的增长阶。另一方面,增长的阶提供了一个有用的指示,告诉我们随着问题规模的改变,过程的行为可能如何变化。对于 (n)(线性)过程,将规模加倍会使资源使用量大约翻倍。对于 指数过程,问题规模的每次增加都会将资源利用率乘以一个常数因子。在第 1.2 节的剩余部分,我们将考察两种增长阶为 对数级的算法,使得问题规模加倍时资源需求只增加一个常量。
练习 1.14. Draw the tree illustrating the process generated by the count-change procedure of section 1.2.2 in making 兑换 11 美分。这个过程使用的空间和步数的增长阶是多少? 当要兑换的金额增加时,这个过程使用的步数的增长阶是多少? increases?
练习 1.15. The sine of an angle (specified in
(以弧度指定)可以利用近似 sin x ≈ x(如果 x 足够小)和三角恒等式
sin x 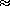 x
如果 x 足够小,以及三角恒等式
x
如果 x 足够小,以及三角恒等式
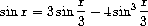
来减小 sin 的参数的大小。 (For (就本练习而言,如果角度大小不超过 0.1 弧度,则认为该角度"足够小"。)这些思想体现在以下过程中: 小",如果其大小不超过 0.1 弧度。)这些
(define (cube x) (* x x x))
(define (p x) (- (* 3 x) (* 4 (cube x))))
(define (sine angle)
(if (not (> (abs angle) 0.1))
angle
(p (sine (/ angle 3.0)))))
a. How many times is the procedure p applied when (sine 12.15) is evaluated?
b. 当求值 (sine a) 时,sine 过程生成的过程在空间和步数方面的增长阶(作为 a 的函数)是多少? function of a) used by the process generated by the sine procedure when (sine a) is evaluated?
考虑计算给定数的指数的问题。我们希望有一个过程,它以底数 b 和正整数指数 n 为参数,计算 bn。 One way to do this 一种方法是通过递归定义
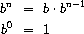
它很容易转化为过程
(define (expt b n)
(if (= n 0)
1
(* b (expt b (- n 1)))))
这是一个线性递归过程,需要 (n) 步和 (n) 空间。就像阶乘一样,我们可以容易地构造一个等价的线性迭代:
和 (n) 空间。就像阶乘一样,我们可以容易地
构造一个等价的线性迭代:
(define (expt b n)
(expt-iter b n 1))
(define (expt-iter b counter product)
(if (= counter 0)
product
(expt-iter b
(- counter 1)
(* b product))))
这个版本需要 (n) 步和 (1) 空间。
我们可以通过使用逐次平方用更少的步数计算指数。例如,与其将 b8 计算为
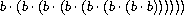
我们可以用三次乘法来计算它:
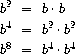
这种方法对于 2 的幂的指数很有效。如果使用以下规则,我们也可以在一般情况下利用逐次平方来计算指数:

我们可以将此方法表达为一个过程:
(define (fast-expt b n)
(cond ((= n 0) 1)
((even? n) (square (fast-expt b (/ n 2))))
(else (* b (fast-expt b (- n 1))))))
其中测试整数是否为偶数的谓词是根据基本过程 remainder 定义的:
(define (even? n)
(= (remainder n 2) 0))
fast-expt 演化出的过程在空间和步数上都随 n 对数增长。为了理解这一点,注意使用 fast-expt 计算 b2n 只需要比计算 bn 多一次乘法。因此,我们可以计算的指数大小(近似地)每增加一次乘法就翻倍。因此,指数 n 所需的乘法次数大约以 2 为底的 n 的对数的速度增长。该过程具有 (log n) 的增长阶。37
(log n) 增长和 (n) 增长之间的差异随着 n 变大而变得惊人。例如,fast-expt 对于 n = 1000 只需要 14 次乘法。38 也可以使用逐次平方的思想来设计一个具有对数步数的迭代算法来计算指数(见练习 1.16),尽管与迭代算法常见的情况一样,这不如递归算法那样直接。39
练习 1.16. 设计一个过程,它演化出一个使用逐次平方并具有对数步数的迭代求幂过程,就像 fast-expt 一样。(提示:利用 (bn/2)2 = (b2)n/2 这一观察,在指数 n 和底数 b 之外,保持一个额外的状态变量 a,并定义状态变换,使得乘积 a bn 在状态之间保持不变。在过程开始时 a 取为 1,答案由过程结束时 a 的值给出。一般来说,定义从状态到状态保持不变的不变量技术是思考迭代算法设计的强大方式。)
练习 1.17. 本节中的求幂算法基于通过重复乘法执行求幂。类似地,可以通过重复加法执行整数乘法。以下乘法过程(假设我们的语言只能加不能乘)类似于 expt 过程:
(define (* a b)
(if (= b 0)
0
(+ a (* a (- b 1)))))
该算法所需步数与 b 成线性关系。现在假设除了加法之外,我们还有 double(将整数加倍)和 halve(将偶整数除以 2)操作。 使用这些,设计一个类似于 fast-expt 的乘法过程,该过程使用加法和 double 操作,且具有对数步数。
练习 1.18. 利用练习 1.16 和 1.17 的结果,设计一个过程,它生成一个使用加法、加倍和减半并具有对数步数的迭代过程来乘法两个整数。40
练习 1.19.
有一种巧妙的算法可以在对数步数内计算斐波那契数。回想第 1.2.2 节中 fib-iter 过程的状态变量 a 和 b 的变换:a a + b 且 b a。称此变换为 T,注意从 1 和 0 开始反复应用 T n 次,产生对 Fib(n + 1) 和 Fib(n)。换句话说,斐波那契数是通过从对 (1,0) 开始应用 Tn(即变换 T 的 n 次幂)产生的。现在考虑 T 是变换族 Tpq 中 p = 0 和 q = 1 的特例,其中 Tpq 根据 a bq + aq + ap 和 b bp + aq 变换对 (a,b)。证明如果我们应用两次这样的变换 Tpq,效果等同于使用同一形式的单次变换 Tp'q',并用 p 和 q 计算 p' 和 q'。这给出了平方这些变换的显式方法,因此我们可以使用逐次平方来计算 Tn,就像在 fast-expt 过程中一样。将所有这些放在一起完成以下过程,它以对数步数运行:41
(define (fib n)
(fib-iter 1 0 0 1 n))
(define (fib-iter a b p q count)
(cond ((= count 0) b)
((even? count)
(fib-iter a
b
<??> ; compute p'
<??> ; compute q'
(/ count 2)))
(else (fib-iter (+ (* b q) (* a q) (* a p))
(+ (* b p) (* a q))
p
q
(- count 1)))))
两个整数 a 和 b 的最大公约数 (GCD) 定义为能够同时整除 a 和 b 且没有余数的最大整数。例如,16 和 28 的 GCD 是 4。在第 2 章中,当我们研究如何实现有理数算术时,我们需要能够计算 GCD 以便将有理数化为最简形式。(要将有理数化为最简形式,我们必须将分子和分母同时除以它们的 GCD。例如,16/28 化简为 4/7。)求两个整数 GCD 的一种方法是分解它们并寻找公因子,但有一种著名的算法效率更高。
该算法的思想基于这样的观察:如果 r 是 a 除以 b 的余数,那么 a 和 b 的公因子与 b 和 r 的公因子完全相同。因此,我们可以使用方程
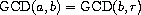
来将计算 GCD 的问题逐步归约为计算越来越小的整数对的 GCD。例如,
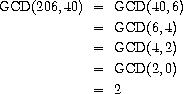
将 GCD(206,40) 归约为 GCD(2,0),即 2。 可以证明,从任意两个正整数开始,反复进行归约最终总会产生第二个数为 0 的对。此时 GCD 就是该对中的另一个数。这种计算 GCD 的方法称为欧几里得算法。42
将欧几里得算法表达为一个过程很容易:
(define (gcd a b)
(if (= b 0)
a
(gcd b (remainder a b))))
这生成一个迭代过程,其步数随所涉及数的对数增长。
欧几里得算法所需步数的对数增长与斐波那契数之间有一个有趣的联系:
Lamé 定理:如果欧几里得算法需要 k 步来计算某对数的 GCD,那么该对中较小的数必须大于或等于第 k 个斐波那契数。43
我们可以用这个定理来得到欧几里得算法的增长阶估计。令 n 为过程两个输入中较小的那个。如果过程需要 k 步,那么必须有 n > Fib(k) k/5。因此步数 k 以 n 的对数(以 为底)增长。因此,增长阶为 (log n)。
练习 1.20. 过程生成的计算过程当然取决于解释器使用的规则。作为一个例子,考虑上面给出的迭代 gcd 过程。假设我们使用第 1.1.5 节讨论的正则序求值来解释这个过程。(if 的正则序求值规则在练习 1.5 中描述。)使用代换方法(对于正则序),说明求值 (gcd 206 40) 时生成的过程,并指出实际执行的 remainder 操作。在 (gcd 206 40) 的正则序求值中实际执行了多少次 remainder 操作?在应用序求值中呢?
本节描述两种检查整数 n 素性的方法,一种具有 (n) 的增长阶,另一种是增长阶为 (log n) 的"概率"算法。本节末尾的练习建议了基于这些算法的编程项目。
integer n, one with order of growth (n), and a
``probabilistic'' algorithm with order of growth (log n). The
exercises at the end of this section suggest programming
projects based on these algorithms.
自古以来,数学家们一直对素数问题着迷,许多人致力于研究确定数字是否为素数的方法。测试一个数是否为素数的一种方法就是找出该数的除数。以下程序找出给定数 n 的大于 1 的最小整数除数。它通过从 2 开始的连续整数测试 n 的可除性,以一种直接的方式完成这一任务。
(define (smallest-divisor n)
(find-divisor n 2))
(define (find-divisor n test-divisor)
(cond ((> (square test-divisor) n) n)
((divides? test-divisor n) test-divisor)
(else (find-divisor n (+ test-divisor 1)))))
(define (divides? a b)
(= (remainder b a) 0))
我们可以如下测试一个数是否为素数:n 是素数当且仅当 n 是自身的最小除数。
(define (prime? n)
(= n (smallest-divisor n)))
The end test for find-divisor is based on the fact that if n
不是素数,则它必有一个小于或等于 n 的除数。这意味着算法只需测试 1 到 n 之间的除数。因此,将 n 识别为素数所需的步数具有 (n) 的增长阶。
n.44 This
means that the algorithm need only test divisors between 1 and
n. Consequently, the number of steps required to identify
n as prime will have order of growth (n).
(log n) 素数检验基于数论中一个称为费马小定理的结果。45
费马小定理:如果 n 是素数且 a 是任何小于 n 的正整数,那么 a 的 n 次方模 n 同余于 a。
(如果两个数除以 n 时有相同的余数,则称它们模 n 同余。数 a 除以 n 的余数也称为 a 模 n 的余数,或简称为 a 模 n。)
如果 n 不是素数,那么一般来说,大多数 a < n 的数字不满足上述关系。这就产生了以下测试素性的算法:给定一个数 n,选取一个 随机数 a < n,计算 an 模 n 的余数。如果结果不等于 a,那么 n 肯定不是素数。如果等于 a,那么 n 很有可能是素数。现在选取另一个随机数 a 并用相同的方法测试。如果它也满足该方程,那么我们就更有信心 n 是素数。通过尝试越来越多的 a 值,我们可以增加对结果的信心。这个算法称为 Fermat 检验。
为了实现 Fermat 检验,我们需要一个计算一个数的指数模另一个数的过程:
(define (expmod base exp m)
(cond ((= exp 0) 1)
((even? exp)
(remainder (square (expmod base (/ exp 2) m))
m))
(else
(remainder (* base (expmod base (- exp 1) m))
m))))
This is very similar to the fast-expt procedure of 它使用逐次平方,所以步数随指数对数增长。 that the number of steps grows logarithmically with the exponent.46
Fermat 检验通过随机选择 1 到 n - 1 之间的数 a,检查 a 的 n 次方模 n 的余数是否等于 a 来执行。随机数 random 过程由 Scheme 实现提供;它返回一个小于其整数输入的非负整数。因此,要获得 1 到 n - 1 之间的随机数,我们调用 (random (- n 1)) 并在结果上加 1。 between 1 and n - 1 inclusive and checking whether the remainder modulo n of the nth power of a is equal to a. The random number a is chosen using the procedure random, which we assume is included as a primitive in Scheme. Random returns a nonnegative integer less than its integer input. Hence, to obtain a random number between 1 and n - 1, we call random with an input of n - 1 and add 1 to the result:
(define (fermat-test n)
(define (try-it a)
(= (expmod a n n) a))
(try-it (+ 1 (random (- n 1)))))
以下过程运行指定次数的检验,由参数指定。如果每次检验都成功则其值为真,否则为假。
(define (fast-prime? n times)
(cond ((= times 0) true)
((fermat-test n) (fast-prime? n (- times 1)))
(else false)))
Fermat 检验在性质上不同于大多数熟悉的算法,在那些算法中计算出的答案是保证正确的。这里,得到的答案只是可能正确。更精确地说,如果 n 未能通过 Fermat 检验,我们可以确定 n 不是素数。但 n 通过检验的事实,虽然是一个极强的指示,仍然不能保证 n 是素数。我们想说的是,对于任何数 n,如果我们执行足够多次检验并发现 n 始终通过,那么我们的素数检验中错误的概率可以做到任意小。
不幸的是,这个断言并不完全正确。确实存在欺骗 Fermat 检验的数:n 不是素数,但对所有整数 a < n 都具有 an 模 n 同余于 a 的性质。这样的数极其罕见,因此 Fermat 检验在实践中相当可靠。47 存在不能被欺骗的 Fermat 检验变体。在这些检验中,与 Fermat 方法一样,通过选择随机整数 a < n 并检查依赖于 n 和 a 的某种条件来测试整数 n 的素性。 (See exercise 1.28 for an example of such a test.) 另一方面,与 Fermat 检验相反,可以证明对于任何 n,除非 n 是素数,否则大多数整数 a < n 不满足该条件。因此,如果 n 通过了对某个随机选择的 a 的检验,那么 n 是素数的可能性大于一半。如果 n 通过了两个随机选择的 a 的检验,那么 n 是素数的可能性大于 3/4。通过使用越来越多随机选择的 a 值运行检验,我们可以使错误的概率任意小。
存在可以证明错误概率任意小的检验,这激发了人们对这类算法的兴趣,它们现在被称为概率算法。这一领域有大量的研究活动,概率算法已被成功地应用于许多领域。48
练习 1.21. 使用 smallest-divisor 过程找出以下各数的最小除数:199、1999、19999。
练习 1.22. 大多数 Lisp 实现包含一个称为 runtime 的原语,它返回一个指定系统已运行时间的整数(例如,以微秒为单位)。以下 timed-prime-test 过程,当用整数 n 调用时,打印 n 并检查 n 是否为素数。如果 n 是素数,该过程打印三个星号后跟执行测试所用的时间。
(define (timed-prime-test n)
(newline)
(display n)
(start-prime-test n (runtime)))
(define (start-prime-test n start-time)
(if (prime? n)
(report-prime (- (runtime) start-time))))
(define (report-prime elapsed-time)
(display " *** ")
(display elapsed-time))
使用这个过程,编写一个过程 search-for-primes,检查指定范围内连续奇数的素性。使用你的过程找出大于 1000、大于 10,000、大于 100,000、大于 1,000,000 的三个最小素数。注意测试每个素数所需的时间。由于测试算法具有 (n) 的增长阶,你应该期望测试 10,000 附近的素数所需的时间大约是在 1000 附近测试素数的 10 倍。你的计时数据证实了这一点吗?100,000 和 1,000,000 的数据在多大程度上支持 n 的预测?你的结果与你的机器上程序运行时间与计算所需步数成比例的观点一致吗?
练习 1.23. 本节开头展示的 smallest-divisor 过程做了很多不必要的测试:在检查了数是否能被 2 整除之后,就没有必要再检查它是否能被任何更大的偶数整除了。这表明用于 test-divisor 的值不应该是 2、3、4、5、6……而应该是 2、3、5、7、9……。为了实现这一改变,定义一个过程 next,如果输入等于 2 则返回 3,否则返回输入加 2。修改 smallest-divisor 过程,使用 (next test-divisor) 而不是 (+ test-divisor 1)。使用包含此修改版 smallest-divisor 的 timed-prime-test,对练习 1.22 中找到的 12 个素数中的每一个运行测试。由于此修改将测试步数减半,你应该期望它运行速度大约快一倍。这个期望被证实了吗?如果没有,两种算法速度的观测比率是多少,你如何解释它与 2 不同的原因?
练习 1.24. 修改练习 1.22 中的 timed-prime-test 过程,使用 fast-prime?(Fermat 方法),并测试你在该练习中找到的 12 个素数中的每一个。由于 Fermat 检验具有 (log n) 的增长阶,你期望测试 1,000,000 附近的素数所需的时间与测试 1000 附近的素数所需的时间相比如何?你的数据证实了这一点吗?你能解释你发现的任何差异吗?
练习 1.25. Alyssa P. Hacker 抱怨我们在编写 expmod 时做了很多额外工作。毕竟,她说,既然我们已经知道如何计算指数,我们完全可以简单地写
(define (expmod base exp m)
(remainder (fast-expt base exp) m))
她正确吗?这个过程对我们的快速素数测试器同样有效吗?请解释。
练习 1.26. Louis Reasoner 在做练习 1.24 时遇到了很大困难。他的 fast-prime? 测试似乎比他的 prime? 测试运行得更慢。Louis 叫他的朋友 Eva Lu Ator 过来帮忙。当他们检查 Louis 的代码时,发现他重写了 expmod 过程,使用了显式乘法而不是调用 square:
(define (expmod base exp m)
(cond ((= exp 0) 1)
((even? exp)
(remainder (* (expmod base (/ exp 2) m)
(expmod base (/ exp 2) m))
m))
(else
(remainder (* base (expmod base (- exp 1) m))
m))))
"我不明白这有什么区别,"Louis 说。"我明白,"Eva 说。"像那样编写过程,你已经把 (log n) 的过程变成了 (n) 的过程。"
请解释。
练习 1.27. 证明脚注 47 中列出的 Carmichael 数确实能欺骗 Fermat 检验。也就是说,编写一个过程,它接受整数 n 并测试对于每个 a < n 是否 an 模 n 同余于 a,然后在给定的 Carmichael 数上测试你的过程。
练习 1.28. 一种不会被欺骗的 Fermat 检验变体称为 Miller-Rabin 检验(Miller 1976; Rabin 1980)。它从 费马小定理的另一种形式出发,该形式指出如果 n 是素数且 a 是任何小于 n 的正整数,那么 a 的 (n - 1) 次方模 n 同余于 1。为了通过 Miller-Rabin 检验测试数 n 的素性,我们选取一个随机数 a < n,使用 expmod 过程计算 a 的 (n - 1) 次方模 n。然而,每当我们在 expmod 中执行平方步骤时,我们检查是否发现了"1 模 n 的非平凡平方根",即一个不等于 1 或 n - 1 但其平方等于 1 模 n 的数。可以证明,如果存在这样的 1 的非平凡平方根,那么 n 不是素数。还可以证明,如果 n 是奇数且不是素数,那么对于至少一半的 a < n,以这种方式计算 an-1 将揭示 1 模 n 的非平凡平方根。(这就是 Miller-Rabin 检验不会被欺骗的原因。)修改 expmod 过程,使其在发现 1 的非平凡平方根时发出信号,并用它来实现一个类似于 fermat-test 的 Miller-Rabin 检验过程。通过测试各种已知素数和合数来检查你的过程。 Hint: One convenient way to make expmod signal is to have it return 0.
29 在实际程序中,我们可能会使用上一节介绍的块结构来隐藏 fact-iter 的定义:
(define (factorial n)
(define (iter product counter)
(if (> counter n)
product
(iter (* counter product)
(+ counter 1))))
(iter 1 1))
我们在这里避免这样做是为了尽量减少一次要考虑的事情的数量。
30 当我们在第 5 章讨论寄存器计算机上过程的实现时,我们将看到任何迭代过程都可以"在硬件上"实现为具有固定寄存器组且没有辅助存储器的机器。相反,实现递归过程需要一台使用称为栈的辅助数据结构的机器。
31 尾递归长期以来一直被称为编译器优化技巧。 Carl Hewitt (1977) 为尾递归提供了连贯的语义基础,他用我们将在第 3 章讨论的“消息传递”计算模型解释了它。 受此启发,Gerald Jay Sussman 和 Guy Lewis Steele Jr.(见 Steele 1975)为 Scheme 构建了一个尾递归解释器。Steele 后来展示了尾递归是编译过程调用的自然方式的结果(Steele 1977)。Scheme 的 IEEE 标准要求 Scheme 实现是尾递归的。
32 在第 1.1.3 节中暗示了一个例子:解释器本身使用树形递归过程来求值表达式。
33 例如,详细演算归约规则如何应用于用便士和镍币兑换 10 美分的问题。
34 处理冗余计算的一种方法是安排事情,使我们在计算值时自动构建一个值表。每次要求将过程应用于某个参数时,我们首先查看该值是否已存储在表中,如果是,则避免执行冗余计算。这种策略称为 制表或记忆化,可以用直接的方式实现。 制表有时可用于将需要指数步数的过程(如 count-change)转化为空间和时间需求随输入线性增长的过程。 See exercise 3.27.
35 杨辉三角的元素称为二项式系数,因为第 n 行由 (x + y)n 展开式中各项的系数组成。 This pattern for computing the coefficients 出现在 Blaise Pascal 1653 年的概率论开创性著作算术三角论中。根据Knuth (1973),相同的模式出现在中国数学家朱世杰 1303 年出版的四元玉鉴中,以及 12 世纪波斯诗人和数学家 Omar Khayyam 的作品中,还有 12 世纪印度数学家 Bhaskara Acharya 的作品中。 Knuth (1973), the same pattern appears in the Szu-yuen Yü-chien (``The Precious Mirror of the Four Elements''), published by the Chinese mathematician Chu Shih-chieh in 1303, in the works of the twelfth-century Persian poet and mathematician Omar Khayyam, and in the works of the twelfth-century Hindu mathematician Bháscara Áchárya.
36 这些陈述掩盖了很多过度简化的问题。 例如,如果我们把过程步数计为“机器操作”,我们就在假设执行一次乘法所需的机器操作数与要乘的数的大小无关,如果数足够大,这是不正确的。 对空间的估计也类似。就像过程的设计和描述一样,过程的分析可以在不同抽象层次上进行。
37 更精确地说,所需乘法次数等于以 2 为底的 n 的对数减 1 加上 n 的二进制表示中 1 的个数。 这个总数总是小于以 2 为底的 n 的对数的两倍。 阶的记号定义中的任意常数 k1 和 k2 意味着,对于对数过程,对数的底数并不重要,因此所有这样的过程都被描述为 (log n)。
38 你可能想知道为什么有人会关心将数字提高到 1000 次幂。参见第 1.2.6 节。
39 这个迭代算法很古老。它出现在Acharya Pingala 所著的 Chandah-sutra 中,写于公元前 200 年之前。有关此方法和其他求幂方法的全面讨论和分析,请参见 Knuth 1981 年第 4.6.3 节。
40 这个有时被称为"俄罗斯农夫乘法"的算法很古老。它的使用示例出现在Rhind 纸草书中,这是现存最古老的数学文献之一,大约写于公元前 1700 年(由一位名叫 A'h-mose 的埃及抄写员从更古老的文献中抄写)。
41 这个练习由 Joe Stoy 根据 Kaldewaij 1990 中的一个示例向我们建议。
42 欧几里得算法之所以得名,是因为它出现在欧几里得的几何原本(第 7 卷,约公元前 300 年)中。 根据 Knuth (1973),它可以被认为是已知最古老的非平凡算法。 古埃及乘法方法(练习 1.18)当然更古老,但正如 Knuth 所解释的,欧几里得算法是已知最古老的以通用算法形式呈现的算法,而非一组说明性示例。
43 这个定理由 Gabriel Lame 在 1845 年证明,他是一位法国数学家和工程师,主要以其对数学物理的贡献而闻名。 To prove the theorem, we consider pairs
(ak ,bk), where ak> bk, for which Euclid's Algorithm
在 k 步内终止。证明基于以下主张:如果 (ak+1, bk+1) → (ak, bk) → (ak-1, bk-1) 是归约过程中的三个连续对,那么必须有 bk+1 > bk + bk-1。
(ak+1, bk+1)  (ak, bk)
(ak-1, bk-1) are three successive pairs in the
要验证这一主张,考虑归约步骤定义为应用变换 ak-1 = bk,bk-1 = ak 除以 bk 的余数。
applying the transformation ak-1 = bk, bk-1 =
第二个方程意味着 ak = qbk + bk-1,其中 q 是某个正整数。由于 q 至少为 1,我们有 ak = qbk + bk-1 > bk + bk-1。但上一步归约中我们有 bk+1 = ak。因此 bk+1 = ak > bk + bk-1。这验证了该主张。
positive integer q. And since q must be at least 1 we have ak
= qbk + bk-1 > bk + bk-1. But in the previous
reduction step we have bk+1 = ak. Therefore, bk+1 =
ak> bk + bk-1. This verifies the claim. Now we can
现在我们可以通过对 k(算法终止所需的步数)的归纳来证明该定理。对于 k = 1 结论成立,因为这只需要 b 至少与 Fib(1) = 1 一样大。现在假设结论对于所有小于或等于 k 的整数成立,并证明对于 k + 1 成立。
algorithm requires to terminate. The result is true for k = 1, since
this merely requires that b be at least as large as
Fib(1) = 1. Now, assume that the result is true for all integers less
than or equal to k and establish the result for k + 1. Let
(ak+1, bk+1) (ak, bk)
(ak-1, bk-1) be successive pairs in the
根据归纳假设,我们有 bk-1 > Fib(k - 1) 和 bk > Fib(k)。因此,应用我们刚刚证明的主张并结合斐波那契数的定义,得到 bk+1 > bk + bk-1 > Fib(k) + Fib(k - 1) = Fib(k + 1),这就完成了 Lame 定理的证明。
Fib(k - 1) and bk> Fib(k). Thus, applying the claim we just
proved together with the definition of the Fibonacci numbers gives
bk+1 > bk + bk-1> Fib(k) + Fib(k - 1) = Fib(k + 1), which
completes the proof of Lamé's Theorem.
(ak, bk)
(ak-1, bk-1) are three successive pairs in the
要验证这一主张,考虑归约步骤定义为应用变换 ak-1 = bk,bk-1 = ak 除以 bk 的余数。
applying the transformation ak-1 = bk, bk-1 =
第二个方程意味着 ak = qbk + bk-1,其中 q 是某个正整数。由于 q 至少为 1,我们有 ak = qbk + bk-1 > bk + bk-1。但上一步归约中我们有 bk+1 = ak。因此 bk+1 = ak > bk + bk-1。这验证了该主张。
positive integer q. And since q must be at least 1 we have ak
= qbk + bk-1 > bk + bk-1. But in the previous
reduction step we have bk+1 = ak. Therefore, bk+1 =
ak> bk + bk-1. This verifies the claim. Now we can
现在我们可以通过对 k(算法终止所需的步数)的归纳来证明该定理。对于 k = 1 结论成立,因为这只需要 b 至少与 Fib(1) = 1 一样大。现在假设结论对于所有小于或等于 k 的整数成立,并证明对于 k + 1 成立。
algorithm requires to terminate. The result is true for k = 1, since
this merely requires that b be at least as large as
Fib(1) = 1. Now, assume that the result is true for all integers less
than or equal to k and establish the result for k + 1. Let
(ak+1, bk+1) (ak, bk)
(ak-1, bk-1) be successive pairs in the
根据归纳假设,我们有 bk-1 > Fib(k - 1) 和 bk > Fib(k)。因此,应用我们刚刚证明的主张并结合斐波那契数的定义,得到 bk+1 > bk + bk-1 > Fib(k) + Fib(k - 1) = Fib(k + 1),这就完成了 Lame 定理的证明。
Fib(k - 1) and bk> Fib(k). Thus, applying the claim we just
proved together with the definition of the Fibonacci numbers gives
bk+1 > bk + bk-1> Fib(k) + Fib(k - 1) = Fib(k + 1), which
completes the proof of Lamé's Theorem.
44 如果 d 是 n 的除数,那么 n/d 也是。但 d 和 n/d 不能都大于 n。
45 Pierre de Fermat (1601-1665) 被认为是现代数论的创始人。 他获得了许多重要的数论结果,但他通常只宣布结果而不提供证明。 费马小定理是在他 1640 年写的一封信中陈述的。第一个发表的证明由 Euler 在 1736 年给出(莱布尼茨未发表的手稿中发现了更早的相同证明)。 费马最著名的结果——称为费马大定理——是他在 1637 年在其所著的算术(由三世纪希腊数学家Diophantus 所著)的副本上草草写下的,并附注:"我发现了一个确实了不起的证明,但此处空白太小写不下。" 寻找费马大定理的证明成为数论中最著名的挑战之一。完整的解答最终由普林斯顿大学的 Andrew Wiles 在 1995 年给出。
46 在指数 e 大于 1 的情况下的归约步骤基于这样的事实:对于任何整数 x、y 和 m,我们可以通过分别计算 x 模 m 和 y 模 m 的余数,将它们相乘,然后取结果模 m 的余数来找到 x 乘以 y 模 m 的余数。 例如,在 e 为偶数的情况下,我们计算 be/2 模 m 的余数,将其平方,然后取模 m 的余数。 这种技术很有用,因为它意味着我们可以在不必处理比 m 大得多的数的情况下执行计算。 (Compare exercise 1.25.)
47 欺骗Fermat 检验的数称为Carmichael 数,除了知道它们极其罕见外,人们对它们知之甚少。 在 100,000,000 以下有 255 个 Carmichael 数。最小的几个是 561、1105、1729、2465、2821 和 6601。 在随机选择非常大的数测试素性时,偶然遇到一个欺骗 Fermat 检验的值的概率小于宇宙辐射导致计算机在执行"正确"算法时出错的概率。 认为一种算法因第一个原因而不够好、但第二个原因却不被认为是不足,这说明了数学与工程之间的区别。
48 概率素数检验最引人注目的应用之一是在密码学领域。 尽管现在对任意 200 位数进行因式分解在计算上是不可行的,但用 Fermat 检验可以在几秒钟内检查这样一个数的素性。 这一事实构成了Rivest、Shamir 和 Adleman (1977) 提出的构建"不可破解密码"技术的基础。 由此产生的 RSA 算法已成为增强电子通信安全性的广泛使用的技术。 由于这一进展和相关发展,对素数的研究——曾被视为仅为其自身而研究的"纯"数学主题的典范——现在被发现对密码学、电子资金转账和信息检索有着重要的实际应用。