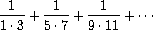
我们已经看到,过程实际上是对数的复合操作进行描述的抽象,与具体的数无关。例如,当我们
我们不是在谈论某个特定数的立方,而是关于获得任意数立方的方法。当然,不定义这个过程我们也能应付,总是编写这样的表达式
(* 3 3 3)
(* x x x)
(* y y y)
并且从不显式提及 cube。这将使我们处于严重不利地位,迫使我们总是在恰好是语言原语的特定操作(这里是指乘法)层次上工作,而不是在更高层次的操作上进行。我们的程序能够计算立方,但我们的语言将缺乏表达"求立方"这个概念的能 力。我们对强大编程语言的要求之一,就是能够通过为常见模式分配名称来构建抽象,然后直接在抽象层面上工作。过程提供了这种能力。这就是为什么所有除了最原始的编程语言之外都包含定义过程的机制。
然而,即使是在数值处理中,如果我们局限于参数必须为数的过程,我们在创建抽象方面的能力将受到严重限制。通常,相同的编程模式会与多个不同的过程一起使用。为了将这样的模式表达为概念,我们需要构造可以接受过程作为参数或返回过程作为值的过程。操作过程的过程称为 高阶过程。本节展示高阶过程如何作为强大的抽象机制,极大地增加我们语言的表达能力。
(define (sum-integers a b)
(if (> a b)
0
(+ a (sum-integers (+ a 1) b))))
第二个计算给定范围内整数的立方和:
(define (sum-cubes a b)
(if (> a b)
0
(+ (cube a) (sum-cubes (+ a 1) b))))
第三个计算级数中一项序列的和
该级数收敛于  /8(非常慢):49
/8(非常慢):49
(define (pi-sum a b)
(if (> a b)
0
(+ (/ 1.0 (* a (+ a 2))) (pi-sum (+ a 4) b))))
这三个过程显然共享一个共同的底层模式。它们在很大程度上是相同的,仅在过程名称、用于计算要添加项的函数 a,以及提供下一个 a 值的函数上有所不同。我们可以通过填充同一模板中的槽来生成每个过程:
(define (<name> a b)
(if (> a b)
0
(+ (<term> a)
(<name> (<next> a) b))))
这种共同模式的存在强烈表明有一个有用的抽象等待被揭示。事实上,数学家很久以前就确定了级数求和的抽象,并发明了\"sigma 记号\",例如
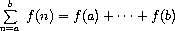
来表达这个概念。sigma 记号的力量在于它允许数学家处理求和概念本身,而不仅仅是特定的和——例如,制定关于和的、独立于所求和的具体级数的一般结果。
类似地,作为程序设计者,我们希望我们的语言足够强大,能够编写表达求和概念本身的过程,而不仅仅是计算特定和的过程。我们可以很容易地在我们的过程语言中做到这一点,通过取上面展示的通用模板并将"槽"转换为形式参数:
(define (sum term a next b)
(if (> a b)
0
(+ (term a)
(sum term (next a) next b))))
注意 sum 以其下界和上界 a 和 b 以及过程 term 和 next 为参数。我们可以像使用任何过程一样使用 sum。例如,我们可以用它(连同将参数加 1 的 inc 过程)来定义 sum-cubes:
(define (inc n) (+ n 1))
(define (sum-cubes a b)
(sum cube a inc b))
使用这个,我们可以计算从 1 到 10 的整数的立方和:
(sum-cubes 1 10)
3025
借助于一个计算项的单位过程,我们可以基于 sum 定义 sum-integers:
(define (identity x) x)
(define (sum-integers a b)
(sum identity a inc b))
然后我们可以计算从 1 到 10 的整数之和:
(sum-integers 1 10)
55
我们也可以用同样的方式定义 pi-sum:50
(define (pi-sum a b)
(define (pi-term x)
(/ 1.0 (* x (+ x 2))))
(define (pi-next x)
(+ x 4))
(sum pi-term a pi-next b))
使用这些过程,我们可以计算 的近似值:
(* 8 (pi-sum 1 1000))
3.139592655589783
一旦有了 sum,我们就可以将其作为构建块来制定更多的概念。例如,函数 f 在区间 a 和 b 之间的定积分可以使用以下公式进行数值近似:
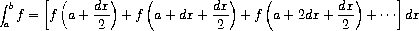
对于小的 dx 值。我们可以直接将其表示为一个过程:
(define (integral f a b dx)
(define (add-dx x) (+ x dx))
(* (sum f (+ a (/ dx 2.0)) add-dx b)
dx))
(integral cube 0 1 0.01)
.24998750000000042
(integral cube 0 1 0.001)
.249999875000001
(cube 在 0 和 1 之间的积分精确值为 1/4。)
练习 1.29. 辛普森法则是一种比上述方法更精确的数值积分方法。 使用辛普森法则, 函数 f 在 a 和 b 之间的积分近似为
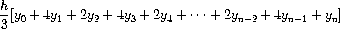
其中 h = (b - a)/n,n 为某个偶数整数,yk = f(a + kh)。 (增大 n 可提高近似的精度。) 定义一个以 f、a、b 和 n 为参数并返回使用辛普森法则计算的积分值的过程。使用你的过程计算 cube 在 0 和 1 之间的积分(n = 100 和 n = 1000),并将结果与上面展示的 integral 过程的结果进行比较。
练习 1.30. 上面的 sum 过程生成一个线性递归。该过程可以重写为迭代执行求和。通过填写以下定义中缺失的表达式来展示如何做到这一点:
(define (sum term a next b)
(define (iter a result)
(if <??>
<??>
(iter <??> <??>)))
(iter <??> <??>))
练习 1.31.
a. sum 过程只是大量类似抽象中最简单的一个,这些抽象可以被捕获为高阶过程。51 编写一个类似的过程 product,它返回一个函数在给定范围内各点的值的乘积。展示如何基于 product 定义 factorial。并使用 product 通过以下公式计算 的近似值
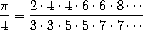
b. 如果你的 product 过程生成递归过程,请编写一个生成迭代过程的过程。如果它生成迭代过程,请编写一个生成递归过程的过程。
练习 1.32. a. 证明 sum 以及product (练习 1.31)都是更一般概念的 称为 accumulate 的一般概念,它将一组 terms, using some general accumulation function:
(accumulate combiner null-value term a next b)
Accumulate 接受与 sum 和 product 相同的项和范围说明作为参数,再加上一个 combiner 过程(两个参数),它指定当前项如何与前几项的累加结果合并,以及一个 null-value,指定当项用尽时使用的基值。编写 accumulate,并展示 sum 和 product 如何都可以定义为对 accumulate 的简单调用。
b. 如果你的 accumulate 过程生成递归过程,则写一个生成迭代过程的过程。如果它生成迭代过程,则写一个生成递归过程的过程。
练习 1.33. 你可以通过引入过滤器的概念得到 accumulate (exercise 1.32) 通过引入一个……的概念 a filter on the terms to be combined. 也就是说,只合并那些从范围内满足指定条件的值导出的项。 The resulting filtered-accumulate abstraction takes the same arguments as accumulate, together with an additional 一个单参数谓词来指定过滤器。 编写 filtered-accumulate as a procedure. Show how to express the 以下内容,使用 filtered-accumulate:
a. 区间 a 到 b 中所有质数的平方和(假设你已经写好了 prime? 谓词)
b. 所有小于 n 且与 n 互质的正整数的乘积(即所有 i < n 的正整数,使得 GCD(i,n) = 1)。
In using sum as in section 1.3.1, 必须定义像……这样琐碎的过程似乎非常笨拙 pi-term 以及pi-next just so we can use them as arguments to our higher-order procedure. Rather than define pi-next 以及pi-term, it would be more convenient 我们希望能够直接指定"返回其输入加 4 的过程"和"返回其输入乘以输入加 2 的倒数"。我们可以通过引入创建过程的特殊形式 lambda 来实现这一点。 使用 lambda 我们可以将我们的需求描述为
(lambda (x) (+ x 4))
以及
(lambda (x) (/ 1.0 (* x (+ x 2))))
这样我们的 pi-sum 过程可以不用定义任何辅助过程来表达为
(define (pi-sum a b)
(sum (lambda (x) (/ 1.0 (* x (+ x 2))))
a
(lambda (x) (+ x 4))
b))
再次使用 lambda,我们可以编写 integral 过程而不必定义辅助过程 add-dx:
(define (integral f a b dx)
(* (sum f
(+ a (/ dx 2.0))
(lambda (x) (+ x dx))
b)
dx))
一般来说,lambda 用于创建过程的方式与 define 相同,只是不为过程指定名称:
(lambda (<formal-parameters>) <body>)
得到的过程与使用 define 创建的过程完全一样。唯一的区别是它没有与环境中的任何名称关联。事实上,
(define (plus4 x) (+ x 4))
等价于
(define plus4 (lambda (x) (+ x 4)))
我们可以如下阅读 lambda 表达式:
(lambda (x) (+ x 4))
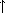
the procedure of an argument x that adds x 和 4
像任何以过程为值的表达式一样,lambda 表达式可以用作组合式中的运算符,例如
((lambda (x y z) (+ x y (square z))) 1 2 3)
12
或者更一般地,在我们通常使用过程名的任何上下文中。53
lambda 的另一个用途是创建局部变量。我们经常在过程中需要除了被绑定为形式参数之外的局部变量。 例如,假设我们希望计算函数
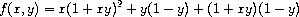
我们也可以将其表达为
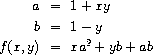
在编写计算 f 的过程中,我们希望在局部变量中不仅包括 x 和 y,还包括中间量如 a 和 b 的名称。 实现这一点的一种方法是使用辅助过程来绑定局部变量:
(define (f x y)
(define (f-helper a b)
(+ (* x (square a))
(* y b)
(* a b)))
(f-helper (+ 1 (* x y))
(- 1 y)))
当然,我们可以使用 lambda 表达式来指定一个匿名过程来绑定我们的局部变量。f 的体就变成了对该过程的一次调用:
(define (f x y)
((lambda (a b)
(+ (* x (square a))
(* y b)
(* a b)))
(+ 1 (* x y))
(- 1 y)))
这种构造非常有用,因此有一种称为 let 的特殊形式使其使用更方便。使用 let,f 过程可以写为
(define (f x y)
(let ((a (+ 1 (* x y)))
(b (- 1 y)))
(+ (* x (square a))
(* y b)
(* a b))))
(let ((<var1> <exp1>)
(<var2> <exp2>)

(<varn> <expn>))
<body>)
可以理解为
| 令 | <var1> 的值为 <exp1> and |
| <var2> 的值为 <exp2> and | |
| |
| <varn> 的值为 <expn> | |
| 在 | <body> |
let 表达式的第一部分是名称-表达式对的列表。当 let 被求值时,每个名称都与相应表达式的值相关联。let 的体在这些名字被绑定为局部变量的情况下求值。其实现方式是:let 表达式被解释为以下形式的另一种语法
((lambda (<var1> ...<varn>)
<body>)
<exp1>
<expn>)
为了提供局部变量,解释器中不需要引入新的机制。let 表达式只是底层 lambda 应用的语法糖。
从这个等价关系我们可以看出 由 let 表达式指定的变量的作用域是 let 的体。 这意味着:
(+ (let ((x 3))
(+ x (* x 10)))
x)
的值为 38。这里,let 体中的 x 是 3,所以 let 表达式的值是 33。另一方面,作为最外层 + 的第二个参数的 x 仍然是 5。
(let ((x 3)
(y (+ x 2)))
(* x y))
的值为 12,因为在 let 体内部,x 为 3 而 y 为 4(即外部 x 加 2)。
有时我们可以使用内部定义来获得与 let 相同的效果。例如,我们可以将上面的过程 f 定义为
(define (f x y)
(define a (+ 1 (* x y)))
(define b (- 1 y))
(+ (* x (square a))
(* y b)
(* a b)))
We prefer, however, to use let in situations like this 以及to use internal define only for internal procedures.54
(define (f g)
(g 2))
于是我们有
(f square)
4
(f (lambda (z) (* z (+ z 1))))
6
如果我们(反常地)要求解释器求值组合式 (f f) 会发生什么?请解释。
我们在第 1.1.4 节中引入了复合过程,作为抽象数值操作模式以使它们独立于所涉及的具体数字的机制。通过高阶过程,例如第 1.3.1 节的 integral 过程,我们开始看到一种更强大的抽象:过程被用来表达计算的一般方法,而与所涉及的特定函数无关。在本节中,我们将讨论两个更复杂的例子——求函数的零点和不动点的通用方法——并展示这些方法如何直接表达为过程。
半区间法是一种简单但强大的求解方程 f(x) = 0 根的技术,其中 f 是连续函数。其思想是,给定点 a 和 b 使得 f(a) < 0 < f(b),那么 f 在 a 和 b 之间至少有一个零点。 To locate a zero, 令 x be the average of a 以及b
并计算 f(x)。如果 f(x) > 0,则 f 在 a 和 x 之间必有零点。如果 f(x) < 0,则 f 在 x 和 b 之间必有零点。这样继续下去,我们可以确定 f 必须有零点的越来越小的区间。 当区间足够小时,过程停止。由于不确定区间在过程的每一步减少一半,所需步数增长为 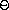 (log(L/T)),其中 L 是原始区间的长度,T 是误差容限(即我们认为"足够小"的区间大小)。
以下是一个实现该策略的过程:
(log(L/T)),其中 L 是原始区间的长度,T 是误差容限(即我们认为"足够小"的区间大小)。
以下是一个实现该策略的过程:
(define (search f neg-point pos-point)
(let ((midpoint (average neg-point pos-point)))
(if (close-enough? neg-point pos-point)
midpoint
(let ((test-value (f midpoint)))
(cond ((positive? test-value)
(search f neg-point midpoint))
((negative? test-value)
(search f midpoint pos-point))
(else midpoint))))))
我们假设初始给定函数 f 以及其值为负和正的点。我们首先计算两个给定点的中点。接下来检查给定区间是否足够小,如果是,则直接返回中点作为答案。否则,我们计算 f 在中点处的值作为测试值。如果测试值为正,我们继续使用从原负点到中点的区间。如果测试值为负,我们继续使用从中点到正点的区间。最后,测试值可能为 0,此时中点本身就是我们要找的根。
为了测试端点是否"足够接近",我们可以使用类似于第 1.1.7 节中用于计算平方根的过程:55
(define (close-enough? x y)
(< (abs (- x y)) 0.001))
直接使用 search 很不方便,因为我们可能不小心给它 f 的值不具有所需符号的点,在这种情况下我们会得到错误的答案。相反,我们将通过以下过程使用 search,它检查哪个端点具有负函数值、哪个具有正值,并相应地调用 search 过程。如果函数在两个给定点上具有相同的符号,则半区间法无法使用,此时过程发出错误信号。56
(define (half-interval-method f a b)
(let ((a-value (f a))
(b-value (f b)))
(cond ((and (negative? a-value) (positive? b-value))
(search f a b))
((and (negative? b-value) (positive? a-value))
(search f b a))
(else
(error "Values are not of opposite sign" a b)))))
以下示例使用半区间法将 近似为 sin x = 0 在 2 和 4 之间的根:
(half-interval-method sin 2.0 4.0)
3.14111328125
另一个例子是使用半区间法寻找方程 x3 - 2x - 3 = 0 在 1 和 2 之间的根:
(half-interval-method (lambda (x) (- (* x x x) (* 2 x) 3))
1.0
2.0)
1.89306640625
如果数 x 满足方程 f(x) = x,则 x 称为函数 f 的不动点。对于某些函数 f,我们可以通过从一个初始猜测开始并反复应用 f 来找到不动点,
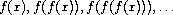
直到值不再有太大变化。利用这一思想,我们可以设计一个过程 fixed-point,它以函数和初始猜测为输入,生成该函数不动点的近似值。我们反复应用该函数,直到找到两个连续值,它们的差小于某个预先设定的容限:
(define tolerance 0.00001)
(define (fixed-point f first-guess)
(define (close-enough? v1 v2)
(< (abs (- v1 v2)) tolerance))
(define (try guess)
(let ((next (f guess)))
(if (close-enough? guess next)
next
(try next))))
(try first-guess))
例如,我们可以用这种方法近似余弦函数的不动点,从初始近似值 1 开始:57
(fixed-point cos 1.0)
.7390822985224023
类似地,我们可以找到方程 y = sin y + cos y:
(fixed-point (lambda (y) (+ (sin y) (cos y)))
1.0)
1.2587315962971173
The fixed-point process is reminiscent of the process we used for
finding square roots in section 1.1.7. Both are based on the
idea of repeatedly improving a guess until the result satisfies some
criterion. In fact, we can readily formulate the square-root
computation as a fixed-point search. Computing the square root of
some number x requires finding a y such that y2 = x. Putting
this equation into the equivalent form y = x/y, we recognize that we
are looking for a fixed point of the function58 y  x/y, 以及we
can therefore try to compute square roots as
x/y, 以及we
can therefore try to compute square roots as
(define (sqrt x)
(fixed-point (lambda (y) (/ x y))
1.0))
不幸的是,这种不动点搜索并不收敛。考虑初始猜测 y1。下一个猜测是 y2 = x/y1,再下一个猜测是 y3 = x/y2 = x/(x/y1) = y1。这导致一个无限循环,两个猜测 y1 和 y2 不断重复,在答案周围振荡。
控制这种振荡的一种方法是阻止猜测变化太大。由于答案总是在猜测 y 和 x/y 之间,我们可以通过将 y 与 x/y 平均来产生一个新的猜测,使其不像 x/y 那样远离 y,于是 y 之后的下一个猜测为 (1/2)(y + x/y) 而不是 x/y。
产生这样一系列猜测的过程就是寻找 y (1/2)(y + x/y) 的不动点的过程:
(define (sqrt x)
(fixed-point (lambda (y) (average y (/ x y)))
1.0))
(注意 y = (1/2)(y + x/y) 是方程 y = x/y 的一个简单变换;要推导它,只需在方程两边加上 y 再除以 2。)
经过这一修改,平方根过程就能工作了。事实上,如果展开这些定义,我们可以看到这里生成的平方根近似序列与第 1.1.7 节中原始平方根过程生成的序列完全相同。这种对解的逐次近似进行平均的方法,我们称之为平均阻尼,通常有助于不动点搜索的收敛。
练习 1.35. 证明黄金比例 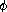 (第 1.2.2 节)是变换 x → 1 + 1/x 的不动点,并利用这一事实通过 fixed-point 过程计算 。
(第 1.2.2 节)是变换 x → 1 + 1/x 的不动点,并利用这一事实通过 fixed-point 过程计算 。
练习 1.36. 修改 fixed-point,使其打印出所生成的逼近序列(使用练习 1.22 中展示的 newline 和 display 基本过程)。然后通过寻找 x log(1000)/log(x) 的不动点来求解 xx = 1000。(使用 Scheme 的基本过程 log,它计算自然对数。)比较使用平均阻尼和不使用平均阻尼时所需的步数。(注意你不能用猜测 1 开始 fixed-point,因为这会导致除以 log(1) = 0。)
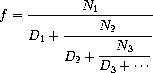
例如,可以证明当所有 Ni 和 Di 都等于 1 时,无限连分数展开产生 1/,其中 是黄金比例(在第 1.2.2 节中描述)。
近似无限连分数的一种方法是在给定项数后截断展开。这种截断——所谓的 k 项有限连分数——具有如下形式
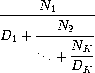
假设 n 和 d 是单参数过程(参数为项索引 i),返回连分数第 i 项的 Ni 和 Di。定义一个过程 cont-frac 使得求值 (cont-frac n d k) 计算 k 项有限连分数的值。通过使用
(cont-frac (lambda (i) 1.0)
(lambda (i) 1.0)
k)
对于 k 的连续值。你需要将 k 设到多大才能得到精确到小数点后 4 位的近似值?
b. 如果你的 cont-frac 过程生成递归过程,则写一个生成迭代过程的过程。如果它生成迭代过程,则写一个生成递归过程的过程。
练习 1.38. 1737 年,瑞士数学家 Leonhard Euler 发表了一篇论文 De Fractionibus Continuis(论连分数),其中包含了一个 连分数 展开式 e - 2,其中 e 是自然对数的底数。 在这个分数中,所有的Ni 都是 1,而 Di 依次为 1, 2, 1, 1, 4, 1, 1, 6, 1, 1, 8, ...。请编写一个程序,使用 练习 1.37 中的 cont-frac 过程,基于 Euler 的展开式来近似 e。
练习 1.39. 由德国数学家 J.H. Lambert 于 1770 年发表的正切函数的连分数表示为:
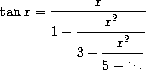
其中 x 以弧度为单位。 定义一个过程 (tan-cf x k),它基于 Lambert 公式计算正切函数的近似值。 K 指定要计算的项数,如 练习 1.37 中一样。
以上示例展示了将过程作为参数传递的能力如何显著增强我们编程语言的表达能力。 我们可以通过创建返回值本身就是过程的过程来获得更大的表达能力。
我们可以通过再次考察第 1.3.3 节末尾描述的不动点示例来说明这个思想。 我们制定了一个新版本的平方根过程作为不动点搜索,从观察到 √x 是函数 y → x/y 的不动点开始。 然后我们使用平均阻尼使近似收敛。 平均阻尼本身就是一个有用的通用技术。也就是说,给定一个函数 f,我们考虑在 x 处的值等于 x 和 f(x) 平均值的函数。
我们可以通过以下过程来表达平均阻尼的思想:
(define (average-damp f)
(lambda (x) (average x (f x))))
Average-damp 是一个过程,它以过程 f 作为参数,并返回一个过程(由 lambda 产生)作为值,该过程应用于数 x 时,产生 x 和 (f x) 的平均值。例如,将 average-damp 应用于 square 过程会产生一个过程,其在某个数 x 处的值是 x 和 x2 的平均值。将 这个结果过程应用于 10 会返回 10 和 100 的平均值,即 55:59
((average-damp square) 10)
55
使用 average-damp,我们可以将平方根过程重新表述如下:
(define (sqrt x)
(fixed-point (average-damp (lambda (y) (/ x y)))
1.0))
注意这个公式如何明确了方法中的三个思想:
不动点搜索、平均阻尼以及函数
y x/y。将这个平方根方法
与第 1.1.7 节给出的原始版本进行比较是有启发性的。请记住,这些过程表达了
相同的过程,并注意当我们用这些抽象来表达过程时,思想变得多么清晰。一般来说,将
过程表述为程序有多种方式。有经验的
程序员知道如何选择特别清晰的过程表述,
以及如何将过程中有用的元素暴露为可以在其他应用中重用的独立实体。
作为重用的一个简单例子,注意 x 的立方根是
函数 y x/y2 的不动点,因此我们可以立即将
平方根过程推广为求立方根
的过程:60
(define (cube-root x)
(fixed-point (average-damp (lambda (y) (/ x (square y))))
1.0))
我们在第 1.1.7 节首次介绍平方根过程时,提到这是牛顿法的一个特例。
如果 x g(x) 是一个可微函数,那么方程 g(x) = 0 的解是函数 x f(x) 的不动点,其中
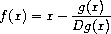
且 Dg(x) 是 g 在 x 处的导数。牛顿法 就是使用我们上面看到的不动点方法, 通过寻找函数 f 的不动点来近似方程的 解。61 对许多函数 g 以及 x 的足够好的初始猜测, 牛顿法会非常快速地收敛到 g(x) = 0 的解。62
为了将牛顿法实现为一个过程,我们必须首先表达导数的概念。注意"导数"和平均阻尼一样,是将一个函数变换为另一个函数的东西。 例如,函数 x → x3 的导数是函数 x → 3x2。一般来说,如果 g 是一个函数且 dx 是一个小数,那么 g 的导数 Dg 是一个函数,其在任何数 x 处的值由下式给出(在 dx 小的极限下)
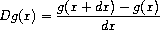
因此,我们可以将导数的思想(取 dx 为,比如说,0.00001)表达为以下过程
(define (deriv g)
(lambda (x)
(/ (- (g (+ x dx)) (g x))
dx)))
以及定义
(define dx 0.00001)
像 average-damp 一样,deriv 是一个以过程为参数并返回过程作为值的过程。 例如,要近似 x → x3 在 5 处的导数(精确值为 75),我们可以求值
(define (cube x) (* x x x))
((deriv cube) 5)
75.00014999664018
借助 deriv,我们可以将牛顿法表达为不动点过程:
(define (newton-transform g)
(lambda (x)
(- x (/ (g x) ((deriv g) x)))))
(define (newtons-method g guess)
(fixed-point (newton-transform g) guess))
newton-transform 过程表达了本节开始处的公式,newtons-method 很容易基于此定义 基于此。它以计算我们想要找零点的函数的过程和一个初始猜测为参数。例如,为了求 x 的平方根,我们可以使用牛顿法求函数 y → y2 - x 的零点,从初始猜测 1 开始。63这提供了平方根过程的另一种形式:
(define (sqrt x)
(newtons-method (lambda (y) (- (square y) x))
1.0))
我们已经看到了将平方根计算表达为更通用方法实例的两种方式:一次作为不动点搜索,一次使用牛顿法。 由于牛顿法本身也是作为不动点过程表达的,我们实际上看到了将平方根作为不动点计算的两种方式。 每种方法都从一个函数开始,寻找该函数的某个变换的不动点。我们可以将这个通用思想本身表达为一个过程:
(define (fixed-point-of-transform g transform guess)
(fixed-point (transform g) guess))
这个非常通用的过程接受一个计算某个函数的过程 g、一个变换 g 的过程以及一个初始猜测作为参数。返回的结果是变换后的函数的不动点。
使用这个抽象,我们可以将本节中的第一个平方根计算(寻找平均阻尼版本的 y → x/y 的不动点)重新表述为这个通用方法的一个实例:
(define (sqrt x)
(fixed-point-of-transform (lambda (y) (/ x y))
average-damp
1.0))
类似地,我们可以将本节中的第二个平方根计算(牛顿法的一个实例,求 y y2 - x 的牛顿变换的不动点)表达为
(define (sqrt x)
(fixed-point-of-transform (lambda (y) (- (square y) x))
newton-transform
1.0))
我们在第 1.3 节开始时观察到,复合过程是一个关键的抽象机制,因为它们允许我们将计算的通用方法表达为编程语言中的显式元素。 现在我们看到了高阶过程如何允许我们操作这些通用方法来创建进一步的抽象。
作为程序员,我们应该敏锐地发现识别程序中底层抽象的机会,并在它们的基础上构建和泛化它们,以创建更强大的抽象。 这并不是说应该总是以尽可能抽象的方式编写程序;专家程序员知道如何选择适合其任务的抽象级别。 但能够以这些抽象的方式思考是很重要的,这样我们就能准备好在新的语境中应用它们。 高阶过程的意义在于它们使我们能够将这些抽象明确地表示为编程语言中的元素,从而使它们可以像其他计算元素一样被处理。
一般来说,编程语言对计算元素的操作方式施加了限制。受到最少限制的元素被称为具有一等状态。 一等元素的一些"权利和特权"包括:64
Lisp 与其他常见编程语言不同,赋予过程完全的一等状态。这给高效实现带来了挑战,但由此带来的表达能力提升是巨大的。66
练习 1.40. 定义一个过程 cubic,使之能与 newtons-method 过程一起用于以下形式的表达式
(newtons-method (cubic a b c) 1)
来近似三次式 x3 + ax2 + bx + c 的零点。
练习 1.41. 定义一个过程 double,它接受一个单参数过程作为参数,并返回一个将原过程应用两次的过程。例如,如果 inc 是一个给其参数加 1 的过程,那么 (double inc) 应该是一个加 2 的过程。以下表达式返回什么值?
(((double (double double)) inc) 5)
练习 1.42. 令 f 和 g 是两个单参数函数。 f 在 g 之后的复合被定义为函数 x f(g(x))。定义一个实现复合的过程 compose。例如,如果 inc 是一个给其参数加 1 的过程,
((compose square inc) 6)
49
练习 1.43. 如果 f 是一个数值函数且 n 是一个正整数,那么我们可以构造 f 的 n 次重复应用,其定义为在 x 处的值为 f(f(...(f(x))...)) 的函数。例如,如果 f 是函数 x → x + 1,那么 f 的第 n 次重复应用是函数 x → x + n。如果 f 是平方运算,那么 f 的第 n 次重复应用是将参数提高到 2n 次幂的函数。编写一个过程,以计算 f 的过程和正整数 n 为输入,返回计算 f 的第 n 次重复应用的过程。该过程应能被如下使用:
((repeated square 2) 5)
625
提示:你可能会发现使用练习 1.42 中的 compose 很方便。
练习 1.44. 平滑函数的思想是信号处理中的一个重要概念。如果 f 是一个函数且 dx 是某个很小的数,那么 f 的平滑版本是在点 x 处的值为 f(x - dx)、f(x) 和 f(x + dx) 的平均值。编写一个过程 smooth,它接受一个计算 f 的过程并返回一个计算平滑后 f 的过程。有时反复平滑一个函数(即平滑平滑后的函数,依此类推)来得到 n 重平滑函数是有价值的。展示如何使用 smooth 和练习 1.43 中的 repeated 来生成任意给定函数的 n 重平滑函数。
练习 1.45. 我们在第 1.3.3 节中看到,试图通过天真地寻找 y → x/y 的不动点来计算平方根不会收敛,这可以通过平均阻尼来修复。 相同的方法也适用于求立方根,将其视为经过平均阻尼的 y → x/y2 的不动点。不幸的是,这个过程对四次方根无效——一次平均阻尼不足以使对 y → x/y3 的不动点搜索收敛。另一方面,如果我们做两次平均阻尼(即使用对 y → x/y3 平均阻尼再取平均阻尼),不动点搜索确实收敛。做一些实验来确定需要多少次平均阻尼才能将 n 次方根计算作为基于对 y → x/yn-1 进行反复平均阻尼的不动点搜索。用这个来实现一个简单的过程,使用 fixed-point、average-damp 和练习 1.43 中的 repeated 过程来计算 n 次方根。 假设你需要的任何算术运算都可用作基本过程。
练习 1.46. 本章描述的几个数值方法是一种称为迭代改进的极其通用的计算策略的实例。 迭代改进的思想是,要计算某物,我们从答案的初始猜测开始,测试猜测是否足够好,否则改进猜测并使用改进后的猜测作为新猜测继续该过程。 编写一个过程 iterative-improve,它以两个过程为参数:判断猜测是否足够好的方法和改进猜测的方法。Iterative-improve 应返回一个以猜测为参数并持续改进猜测直到足够好的过程。 使用 iterative-improve 重写第 1.1.7 节的 sqrt 过程和第 1.3.3 节的 fixed-point 过程。
49 这个级数,通常写成等价形式 (/4) = 1 - (1/3) + (1/5) - (1/7) + ···,由莱布尼茨提出。我们将在第 3.5.3 节看到如何将其用作一些奇特数值技巧的基础。
50 注意我们使用了块结构(第 1.1.8 节)将 pi-next 和 pi-term 的定义嵌入到 pi-sum 中,因为这些过程不太可能用于任何其他目的。我们将在第 1.3.2 节看到如何完全去掉它们。
51 练习 1.31-1.33 的目的是展示通过使用适当的抽象来整合许多看似不同的操作所获得的表达能力。然而,尽管累加和过滤很优雅,但在目前阶段我们的使用受到一些限制,因为我们还没有数据结构来提供适合这些抽象的组合方式。我们将在 2.2.3 节回到这些思想,在那里我们将展示如何使用序列作为组合过滤器和累加器的接口来构建更加强大的抽象。我们将会看到,在那里这些方法真正展现出它们的威力,成为一种强大而优雅的程序设计方法。
52 这个公式是由 17 世纪英国数学家 John Wallis 发现的。
53 如果使用比 lambda 更明显的名称(如 make-procedure),对于学习 Lisp 的人来说会更清晰、不那么令人生畏。但这个惯例已经根深蒂固。该记号来自 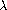 演算,
由数理逻辑学家 Alonzo Church (1941) 引入的数学形式系统。Church 发展 λ 演算的目的是为研究函数和函数应用的概念提供严格的基础。λ 演算已经成为研究程序设计语言语义的数学基本工具。
演算,
由数理逻辑学家 Alonzo Church (1941) 引入的数学形式系统。Church 发展 λ 演算的目的是为研究函数和函数应用的概念提供严格的基础。λ 演算已经成为研究程序设计语言语义的数学基本工具。
54 要充分理解内部定义以确保程序确实按我们的意图执行,需要一个比我们在本章中介绍的求值模型更精细的模型。不过,这些微妙之处不会出现在过程的内部定义中。我们将在 4.1.6 节回到这个问题,在我们更深入地了解求值之后。
55 我们使用 0.001 作为一个有代表性的"小"数来表示计算中可接受误差的容限。实际计算中适当的容限取决于要解决的问题以及计算机和算法的局限性。这通常是一个非常微妙的考量,需要数值分析师或其他某种"魔法师"的帮助。
56 这可以使用 error 来实现,它接受若干项作为参数,这些项被打印为错误信息。
57 在枯燥的讲座上试试这个:把你的计算器设为弧度模式,然后反复按 cos 按钮直到得到不动点。
58
(读作"映射到")是数学家写 lambda 的方式。
y x/y 的意思是 (lambda(y) (/ x y)),即在 y 处的值为 x/y 的函数。
59 注意这是一个运算符本身也是组合式的组合式。练习 1.4 已经展示了形成这种组合的能力,但那只是一个玩具示例。这里我们开始看到对这类组合式的真正需求——当应用一个作为高阶过程返回值得到的过程时。
60 参见练习 1.45 以了解更多推广。
61 微积分基础教材通常根据近似序列 xn+1 = xn - g(xn)/Dg(xn) 来描述牛顿法。有了讨论过程并利用不动点思想的语言,简化了方法的描述。
62 牛顿法并不总是收敛到一个答案,但可以证明在有利情况下每次迭代使解的近似值的精确位数翻倍。在这种情况下,牛顿法会收敛得比二分法快得多。
63 对于求平方根,牛顿法从任何起点出发都能迅速收敛到正确的解。
64 编程语言元素的一等状态的概念归功于英国计算机科学家 Christopher Strachey(1916-1975)。
65 我们将在第二章引入数据结构之后看到这方面的例子。
66 一等过程的主要实现代价是:允许将过程作为值返回要求为过程的自由变量保留存储空间,即使该过程不在执行中。在我们将于 4.1 节研究的 Scheme 实现中,这些变量存储在过程的环境中。