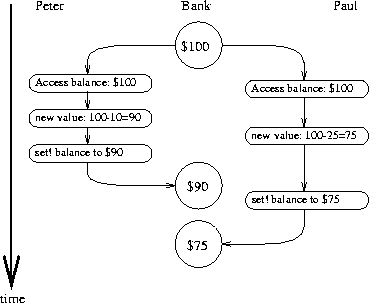
$90 $65,要么是
$100 $75 $65。在银行系统的计算机实现中,这种变化的余额序列可以通过对变量 balance 的连续赋值来建模。
$90 $65,要么是
$100 $75 $65。在银行系统的计算机实现中,这种变化的余额序列可以通过对变量 balance 的连续赋值来建模。我们已经看到了具有局部状态的计算对象作为建模工具的强大能力。然而,正如第 3.1.3 节所警告的,这种能力是有代价的:失去了引用透明性,引发了关于同一性和变化的复杂问题,并且需要放弃求值的替换模型,转而采用更复杂的环境模型。
隐藏在状态、同一性和变化复杂性之下的核心问题是,通过引入赋值,我们被迫将 时间纳入我们的计算模型。在引入赋值之前,我们所有的程序都是“永恒的”, 即任何有值的表达式总是具有相同的值。相比之下,回忆一下在 第 3.1.1 节开头引入的从银行账户中取款 并返回结果余额的例子:
(withdraw 25)
75
(withdraw 25)
50
这里对同一个表达式的连续求值得到了不同的值。这种行为源于赋值语句的执行(在此例中是对变量 balance 的赋值)刻画了值发生变化的时间时刻。求值一个表达式的结果不仅取决于表达式本身,还取决于求值发生在这类时刻之前还是之后。用具有局部状态的计算对象构建模型,迫使我们面对时间作为编程中一个基本概念的事实。
我们可以进一步结构化计算模型,以匹配我们对物理世界的感知。世界中的对象并不是一个一个顺序变化的。相反,我们感知它们并发地行动——同时发生。因此,将系统建模为并发执行的计算过程的集合通常是自然的。正如我们可以通过以具有独立局部状态的对象来组织模型从而使程序模块化一样,将计算模型划分为独立且并发演化的部分也常常是合适的。即使程序要在顺序计算机上执行,按照并发执行的方式编写程序的实践也迫使程序员避免不必要的时间约束,从而使程序更加模块化。
除了使程序更模块化之外,并发计算还可以提供相比顺序计算的速度优势。顺序计算机一次只执行一个操作,因此执行任务所需的时间与执行的操作总数成正比。34 然而,如果可以将问题分解为相对独立且只需要很少通信的多个部分,那么可能可以将这些部分分配给不同的计算处理器,从而产生与可用处理器数量成正比的加速优势。
不幸的是,赋值引入的复杂性在并发存在时变得更加成问题。并发执行的事实——无论是由于世界并行运作还是由于我们的计算机并行运作——都使得我们对时间的理解增加了额外的复杂性。
表面上,时间似乎很简单。它是强加在事件上的一种排序。35
对于任意事件 A 和 B,要么 A 发生在 B 之前,A 和 B
同时发生,要么 A 发生在 B 之后。例如,回到银行账户的例子,假设 Peter
取出 $10 而 Paul 从一个初始余额为 $100 的 联合账户中取出 $25,账户中剩下 $65。根据两次取款的顺序,账户中的余额序列要么是 $100 $90 $65,要么是
$100 $75 $65。在银行系统的计算机实现中,这种变化的余额序列可以通过对变量 balance 的连续赋值来建模。
然而,在复杂情况下,这种观点可能是有问题的。假设 Peter 和 Paul,以及其他人,通过遍布世界的银行机器网络访问同一个银行账户。账户中实际的余额序列将关键性地依赖于访问的详细时间和机器间通信的细节。
事件顺序的这种不确定性可能在并发系统设计中带来严重问题。例如,假设 Peter 和 Paul 的取款被实现为两个独立的进程,共享一个公共变量 balance,每个进程由第 3.1.1 节给出的过程指定:
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
如果两个进程独立运行,那么 Peter 可能会检查余额并尝试取出一笔合法金额。然而,Paul 可能在 Peter 检查余额和完成取款之间的时间内取出一些资金,从而使 Peter 的检查失效。
情况可能更糟。考虑表达式
(set! balance (- balance amount))
作为每个取款过程的一部分执行。这包括三个步骤:(1) 访问 balance 变量的值;(2) 计算新的余额;(3) 将 balance 设置为这个新值。如果 Peter 和 Paul 的取款并发地执行这个语句,那么这两次取款可能会交错访问 balance 和设置新值的顺序。
图 3.29 中的时序图描绘了一种事件顺序,其中 balance 从 100 开始,Peter 取出 10,Paul 取出 25,但 balance 的最终值是 75。如图所示,这种异常的原因是 Paul 将 balance 赋值为 75 时,假设要减去的 balance 值是 100。然而,当 Peter 将 balance 改为 90 时,这个假设就失效了。这对银行系统来说是一个灾难性的失败,因为系统中的总金额没有守恒。交易之前,总金额是 $100。之后,Peter 有 $10,Paul 有 $25,而银行有 $75。36
这里展示的普遍现象是,多个进程可能共享一个公共状态变量。使问题复杂化的是,可能有多个进程同时试图操作共享状态。对于银行账户的例子,在每个事务期间,每个客户应该能够表现得好像其他客户不存在一样。当一个客户以依赖于余额的方式更改余额时,他必须能够假设在更改的时刻之前,余额仍然是他所认为的值。
上述例子代表了可能潜入并发程序中的微妙错误。这种复杂性的根源在于对不同进程间共享的变量的赋值。我们已经知道,在编写使用 set! 的程序时必须小心,因为计算的结果取决于赋值发生的顺序。37 对于并发进程,我们必须特别小心赋值,因为我们可能无法控制不同进程进行赋值的顺序。如果多个这样的更改可能并发进行(就像两个存款人访问联合账户一样),我们需要某种方式来确保系统行为正确。例如,在从联合银行账户取款的情况下,我们必须确保资金守恒。为了使并发程序行为正确,我们可能需要对并发执行施加一些限制。
对并发的一种可能限制是规定,任何更改共享状态变量的两个操作不能同时发生。这是一个极其严格的要求。对于分布式银行,它将要求系统设计者确保一次只能进行一个事务。这将既低效又过于保守。图 3.30 展示了 Peter 和 Paul 共享一个银行账户,而 Paul 还有一个私人账户。该图说明了从共享账户的两次取款(一次由 Peter,一次由 Paul)以及对 Paul 私人账户的一次存款。38 从共享账户的两次取款不能并发(因为两者都访问和更新同一个账户),并且 Paul 的存款和取款不能并发(因为两者都访问和更新 Paul 钱包中的金额)。但是允许 Paul 向他的私人账户存款与 Peter 从共享账户取款并发进行应该没有问题。
|
一个较不严格的并发限制是确保并发系统产生与进程按某种顺序顺序执行相同的结果。这个要求有两个重要方面。首先,它不要求进程实际上顺序运行,只要求产生与它们顺序运行时相同的结果。对于图 3.30 中的例子,银行账户系统的设计者可以安全地允许 Paul 的存款和 Peter 的取款并发进行,因为最终结果将与这两个操作顺序发生相同。其次,并发程序可能产生不止一个可能的"正确"结果,因为我们只要求结果与某种顺序执行相同。例如,假设 Peter 和 Paul 的联合账户初始有 $100,Peter 存入 $40 而 Paul 同时取出了账户中一半的钱。那么顺序执行可能导致账户余额为 $70 或 $90(见练习 3.38)。39
对于并发程序的正确执行还有更弱的要求。用于模拟 扩散(例如物体中的热流)的程序可能由大量进程组成,每个进程代表一个小的空间体积,并并发更新它们的值。每个进程重复地将其值更改为其自身值和邻居值的平均值。这个算法收敛到正确答案,与操作执行的顺序无关;不需要对共享值的并发使用施加任何限制。
练习 3.38. 假设 Peter、Paul 和 Mary 共享一个初始余额为 $100 的联合银行账户。并发地,Peter 存入 $10,Paul 取出 $20,而 Mary 取出账户中一半的钱,通过执行以下命令:
| Peter: | (set! balance (+ balance 10)) |
| Paul: | (set! balance (- balance 20)) |
| Mary: | (set! balance (- balance (/ balance 2))) |
a. 列出这三个事务完成后 balance 所有可能的不同值,假设银行系统强制三个进程按某种顺序顺序运行。
b. 如果系统允许进程交错,可能产生哪些其他值?画出像图 3.29 那样的时序图来解释这些值是如何产生的。
我们已经看到,处理并发进程的困难根源于需要考虑不同进程中事件顺序的交错。例如,假设我们有两个进程,一个有有序事件 (a,b,c),另一个有有序事件 (x,y,z)。如果这两个进程并发运行,对其执行如何交错没有限制,那么有 20 种不同可能的事件顺序与两个进程各自的顺序一致:
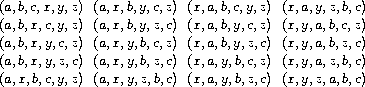
作为设计这个系统的程序员,我们必须考虑这 20 种顺序的每种效果,并检查每种行为是否可接受。随着进程和事件数量的增加,这种方法迅速变得难以处理。
设计并发系统的一个更实用的方法是设计通用机制,允许我们约束并发进程的交错,从而确保程序行为正确。为此已经开发了许多机制。在本节中,我们将描述其中一种——串行化器。
串行化实现了以下思想:进程将并发执行,但某些过程集合不能并发执行。更准确地说,串行化创建了特殊的过程集合,使得每个串行化集合中一次只允许执行一个过程。如果集合中的某个过程正在执行,那么尝试执行该集合中任何过程的进程将被强制等待,直到第一个执行完成。
我们可以使用串行化来控制对共享变量的访问。例如,如果我们想基于某个变量的先前值来更新它,我们将对该变量先前值的访问和新值的赋值放在同一个过程中。然后,通过使用同一个串行化器串行化所有这些过程,我们确保没有其他对该变量赋值的过程可以与这个过程并发运行。这保证了在访问和相应赋值之间,变量的值不会被改变。
为了使上述机制更具体,假设我们扩展了 Scheme,使其包含一个称为 parallel-execute 的过程:
(parallel-execute <p1> <p2> ... <pk>)
每个 <p> 必须是一个无参数的过程。Parallel-execute 为每个 <p> 创建一个独立的进程,该进程应用 <p>(无参数)。这些进程都并发运行。40
作为一个使用示例,考虑
(define x 10)
(parallel-execute (lambda () (set! x (* x x)))
(lambda () (set! x (+ x 1))))
这创建了两个并发进程——P1 将 x 设置为 x 乘以 x,而 P2 将 x 加 1。执行完成后,x 将具有五种可能值之一,取决于 P1 和 P2 事件的交错:
| 101: | P1 将 x 设为 100,然后 P2 将 x 增加到 101。 |
| 121: | P2 将 x 增加到 11,然后 P1 将 x 设置为 x 乘以 x。 |
| 110: | P2 在 P1 两次访问 x 的值以求值 (* x x) 之间将 x 从 10 改为 11。 |
| 11: | P2 访问 x,然后 P1 将 x 设为 100,然后 P2 设置 x。 |
| 100: | P1 访问 x(两次),然后 P2 将 x 设为 11,然后 P1 设置 x。 |
我们可以通过使用由串行化器创建的串行化过程来约束并发。串行化器由 make-serializer 构造,其实现如下所示。串行化器接受一个过程作为参数,并返回一个行为类似于原始过程的串行化过程。对给定串行化器的所有调用都返回同一集合中的串行化过程。
因此,与上面的例子相比,执行
(define x 10)
(define s (make-serializer))
(parallel-execute (s (lambda () (set! x (* x x))))
(s (lambda () (set! x (+ x 1)))))
只能为 x 产生两个可能的值:101 或 121。其他可能性被消除了,因为 P1 和 P2 的执行不能交错。
这是来自第 3.1.1 节的一个 make-account 过程的版本,其中存款和取款已被串行化:
(define (make-account balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(let ((protected (make-serializer)))
(define (dispatch m)
(cond ((eq? m 'withdraw) (protected withdraw))
((eq? m 'deposit) (protected deposit))
((eq? m 'balance) balance)
(else (error "Unknown request -- MAKE-ACCOUNT"
m))))
dispatch))
使用这个实现,两个进程不能同时从单个账户取款或存款。这消除了图 3.29 中所示错误的根源,即 Peter 在 Paul 访问余额以计算新值和 Paul 实际执行赋值之间更改了账户余额。另一方面,每个账户都有自己的串行化器,因此不同账户的存款和取款可以并发进行。
练习 3.39. 如果我们将执行串行化如下,上面并行执行中的五种可能性中哪些仍然存在:
(define x 10)
(define s (make-serializer))
(parallel-execute (lambda () (set! x ((s (lambda () (* x x))))))
(s (lambda () (set! x (+ x 1)))))
练习 3.40. 给出执行以下代码可能产生的 x 的所有可能值
(define x 10)
(parallel-execute (lambda () (set! x (* x x)))
(lambda () (set! x (* x x x))))
如果我们改用串行化过程,这些可能性中哪些仍然存在:
(define x 10)
(define s (make-serializer))
(parallel-execute (s (lambda () (set! x (* x x))))
(s (lambda () (set! x (* x x x)))))
练习 3.41. Ben Bitdiddle 担心最好按如下方式实现银行账户(其中被注释的行已更改):
(define (make-account balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
;; continued on next page
(let ((protected (make-serializer)))
(define (dispatch m)
(cond ((eq? m 'withdraw) (protected withdraw))
((eq? m 'deposit) (protected deposit))
((eq? m 'balance)
((protected (lambda () balance)))) ; serialized
(else (error "Unknown request -- MAKE-ACCOUNT"
m))))
dispatch))
因为允许对银行余额的非串行化访问可能导致异常行为。你同意吗?是否存在任何场景能证明 Ben 的担忧?
练习 3.42. Ben Bitdiddle 建议,为响应每个 withdraw 和 deposit 消息创建一个新的串行化过程是浪费时间。他说可以改变 make-account,将对 protected 的调用放在 dispatch 过程之外。也就是说,账户每次被请求取款过程时,都会返回相同的串行化过程(在创建账户时创建的)。
(define (make-account balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(let ((protected (make-serializer)))
(let ((protected-withdraw (protected withdraw))
(protected-deposit (protected deposit)))
(define (dispatch m)
(cond ((eq? m 'withdraw) protected-withdraw)
((eq? m 'deposit) protected-deposit)
((eq? m 'balance) balance)
(else (error "Unknown request -- MAKE-ACCOUNT"
m))))
dispatch)))
这是一个安全的更改吗?特别地,这两个版本的 make-account 在允许的并发性方面是否有任何区别?
串行化器提供了一种强大的抽象,有助于隔离并发程序的复杂性,以便能够仔细且(希望是)正确地处理它们。然而,虽然当只有一个共享资源(如单个银行账户)时使用串行化器相对直接,但当有多个共享资源时,并发编程可能变得极其困难。
为了说明可能出现的困难之一,假设我们希望交换两个银行账户中的余额。我们访问每个账户以查找余额,计算余额之间的差额,从一个账户中取出这个差额,并将其存入另一个账户。我们可以如下实现:41
(define (exchange account1 account2)
(let ((difference (- (account1 'balance)
(account2 'balance))))
((account1 'withdraw) difference)
((account2 'deposit) difference)))
当只有一个进程尝试进行交换时,这个过程工作良好。然而,假设 Peter 和 Paul 都可以访问账户 a1、a2 和 a3,并且 Peter 交换 a1 和 a2,而 Paul 同时交换 a1 和 a3。即使单个账户的存款和取款已串行化(如本节上面所示的 make-account 过程),exchange 仍然可能产生不正确的结果。例如,Peter 可能计算了 a1 和 a2 之间的余额差,但随后 Paul 可能在 Peter 完成交换之前更改了 a1 的余额。42 为了正确行为,我们必须安排 exchange 过程在整个交换期间锁定对账户的任何其他并发访问。
实现这一点的一种方法是使用两个账户的串行化器来串行化整个 exchange 过程。为此,我们将安排对账户串行化器的访问。请注意,我们故意通过暴露串行化器来破坏银行账户对象的模块性。下面的 make-account 版本与第 3.1.1 节给出的原始版本相同,不同之处在于提供了一个串行化器来保护余额变量,并且串行化器通过消息传递导出:
(define (make-account-and-serializer balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(let ((balance-serializer (make-serializer)))
(define (dispatch m)
(cond ((eq? m 'withdraw) withdraw)
((eq? m 'deposit) deposit)
((eq? m 'balance) balance)
((eq? m 'serializer) balance-serializer)
(else (error "Unknown request -- MAKE-ACCOUNT"
m))))
dispatch))
我们可以使用它来进行串行化的存款和取款。然而,与我们之前串行化的账户不同,现在每个银行账户对象的使用者都有责任显式管理串行化,例如如下所示:43
(define (deposit account amount)
(let ((s (account 'serializer))
(d (account 'deposit)))
((s d) amount)))
以这种方式导出串行化器给了我们足够的灵活性来实现串行化的交换程序。我们只需使用两个账户的串行化器来串行化原始的 exchange 过程:
(define (serialized-exchange account1 account2)
(let ((serializer1 (account1 'serializer))
(serializer2 (account2 'serializer)))
((serializer1 (serializer2 exchange))
account1
account2)))
练习 3.43. 假设三个账户的余额初始为 $10、$20 和 $30,并且有多个进程运行,交换这些账户中的余额。论证如果进程顺序运行,经过任意次数的并发交换后,账户余额应为 $10、$20 和 $30 的某种排列。画出像图 3.29 那样的时序图,展示如果使用本节中第一个版本的账户交换程序实现交换,这个条件如何被违反。另一方面,论证即使使用这个 exchange 程序,账户中的余额总和也会被保留。画一个时序图来展示如果我们不对单个账户上的事务进行串行化,这个条件甚至也会被违反。
练习 3.44. 考虑将一笔金额从一个账户转移到另一个账户的问题。Ben Bitdiddle 声称,即使有多个人同时在多个账户之间转账,使用任何串行化存款和取款事务的账户机制(例如,上文文本中的 make-account 版本),也可以通过以下过程完成:
(define (transfer from-account to-account amount)
((from-account 'withdraw) amount)
((to-account 'deposit) amount))
Louis Reasoner 声称这里有问题,我们需要使用更复杂的方法,比如处理交换问题所需的方法。Louis 对吗?如果不是,转账问题和交换问题之间的本质区别是什么?(你应该假设 from-account 中的余额至少为 amount。)
练习 3.45. Louis Reasoner 认为我们的银行账户系统不必要地复杂且容易出错,因为存款和取款没有自动串行化。他建议 make-account-and-serializer 应该在(而不是替代)像 make-account 那样用它来串行化账户和存款之外,还导出串行化器(供诸如 serialized-exchange 这样的过程使用)。他建议如下重新定义账户:
(define (make-account-and-serializer balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(let ((balance-serializer (make-serializer)))
(define (dispatch m)
(cond ((eq? m 'withdraw) (balance-serializer withdraw))
((eq? m 'deposit) (balance-serializer deposit))
((eq? m 'balance) balance)
((eq? m 'serializer) balance-serializer)
(else (error "Unknown request -- MAKE-ACCOUNT"
m))))
dispatch))
然后存款像原始的 make-account 一样处理:
(define (deposit account amount)
((account 'deposit) amount))
解释 Louis 的推理有什么问题。特别地,考虑当调用 serialized-exchange 时会发生什么。
We implement serializers in terms of a more primitive synchronization mechanism called a mutex. A mutex is an object that supports two operations -- the mutex can be acquired, and the mutex can be released. Once a mutex has been acquired, no other acquire operations on that mutex may proceed until the mutex is released.44 In our implementation, each serializer has an associated mutex. Given a procedure p, the serializer returns a procedure that acquires the mutex, runs p, and then releases the mutex. This ensures that only one of the procedures produced by the serializer can be running at once, which is precisely the serialization property that we need to guarantee.
(define (make-serializer)
(let ((mutex (make-mutex)))
(lambda (p)
(define (serialized-p . args)
(mutex 'acquire)
(let ((val (apply p args)))
(mutex 'release)
val))
serialized-p)))
互斥体是一个可变对象(这里我们使用一个单元素列表,我们将其称为单元),它可以保存 true 或 false 值。当值为 false 时,互斥体可供获取。当值为 true 时,互斥体不可用,任何试图获取该互斥体的进程必须等待。
Our mutex constructor make-mutex begins by initializing the cell contents to false. To acquire the mutex, we test the cell. If the mutex is available, we set the cell contents to true and proceed. Otherwise, we wait in a loop, attempting to acquire over and over again, until we find that the mutex is available.45 To release the mutex, we set the cell contents to false.
(define (make-mutex)
(let ((cell (list false)))
(define (the-mutex m)
(cond ((eq? m 'acquire)
(if (test-and-set! cell)
(the-mutex 'acquire))) ; retry
((eq? m 'release) (clear! cell))))
the-mutex))
(define (clear! cell)
(set-car! cell false))
Test-and-set! 测试单元并返回测试的结果。此外,如果测试结果为 false,则在返回 false 之前,test-and-set! 将单元内容设置为 true。我们可以将这种行为表示为以下过程:
(define (test-and-set! cell)
(if (car cell)
true
(begin (set-car! cell true)
false)))
然而,这个 test-and-set! 的实现不够充分。这里有一个关键的微妙之处,即并发控制进入系统的关键点:test-and-set! 操作必须原子地执行。也就是说,我们必须保证,一旦一个进程测试了单元并发现其为 false,在任何其他进程能够测试该单元之前,单元内容将被设置为 true。如果我们不做出这个保证,那么互斥体就可能以类似于图 3.29 中的银行账户故障的方式失败(见练习 3.46)。
Test-and-set! 的实际实现取决于我们系统运行并发进程的细节。例如,我们可能在一个顺序处理器上使用时间片机制来执行并发进程,该机制循环执行各个进程,允许每个进程运行一小段时间,然后中断它并转到下一个进程。在这种情况下,test-and-set! 可以通过在测试和设置期间禁用时间片来工作。46 或者,多处理计算机提供了直接在硬件中支持原子操作的指令。47
练习 3.46. 假设我们使用文本中所示的普通过程来实现 test-and-set!,而不试图使操作原子化。画出像图 3.29 那样的时序图来演示互斥体实现如何因允许两个进程同时获取互斥体而失败。
练习 3.47. 信号量(大小为 n)是互斥体的一种推广。与互斥体一样,信号量支持获取和释放操作,但它更通用,因为最多可以有 n 个进程并发获取它。其他试图获取信号量的进程必须等待释放操作。给出信号量的实现
a. 基于互斥体
b. 基于原子 test-and-set! 操作。
现在我们已经看到了如何实现串行化器,我们可以看到账户交换仍然存在问题,即使使用上面的 serialized-exchange 过程也是如此。想象一下,Peter 试图交换 a1 和 a2,而 Paul 同时试图交换 a2 和 a1。假设 Peter 的进程到达它已进入保护 a1 的串行化过程的点,而紧接着,Paul 的进程进入保护 a2 的串行化过程。现在 Peter 无法继续(进入保护 a2 的串行化过程),直到 Paul 退出保护 a2 的串行化过程。类似地,Paul 无法继续,直到 Peter 退出保护 a1 的串行化过程。每个进程都永远停滞,等待另一个进程。这种情况称为死锁。在提供对多个共享资源的并发访问的系统中,死锁始终是一个危险。
在这种情况下避免死锁的一种方法是给每个账户一个唯一的标识号,并重写 serialized-exchange,使得进程总是首先尝试进入保护编号最小账户的过程。虽然这种方法对于交换问题效果很好,但还有其他情况需要更复杂的死锁避免技术,或者根本无法避免死锁(见练习 3.48 和 3.49)。48
练习 3.48. 详细解释为什么上述死锁避免方法(即,账户被编号,每个进程尝试先获取编号较小的账户)在交换问题中避免了死锁。重写 serialized-exchange 以融入这个想法。(你还需要修改 make-account,使得每个账户创建时带有一个编号,可以通过发送适当消息来访问该编号。)
练习 3.49. 给出一个上述死锁避免机制不起作用的场景。(提示:在交换问题中,每个进程事先知道它需要访问哪些账户。考虑一种情况,其中进程必须先访问某些共享资源,然后才能知道它还需要哪些额外的共享资源。)
我们已经看到了编程并发系统需要控制不同进程访问共享状态时事件的顺序,并且我们已经看到了如何通过明智地使用串行化器来实现这种控制。但并发的问题比这更深层,因为从基本观点来看,"共享状态"的含义并不总是清晰的。
诸如 test-and-set! 之类的机制要求进程在任意时间检查一个全局共享标志。这在现代高速处理器中实现起来既困难又低效,因为由于流水线和缓存内存等优化技术,内存的内容可能并非在每一时刻都处于一致状态。因此,在当代多处理系统中,串行化器范式正被新的并发控制方法所取代。49
共享状态的问题方面也出现在大型分布式系统中。例如,想象一个分布式银行系统,其中各个分行维护银行余额的本地值,并定期与其它分行维护的值进行比较。在这样的系统中,除了刚同步之后,"账户余额"的值是不确定的。如果 Peter 向他和 Paul 共同持有的账户中存钱,我们什么时候应该说账户余额已经改变——是当本地分行的余额改变时,还是直到同步之后?如果 Paul 从不同的分行访问该账户,我们应该对银行系统施加哪些合理的约束,使得行为是"正确"的?对于正确性唯一重要的可能是 Peter 和 Paul 各自观察到的行为,以及同步后立即的账户"状态"。关于"真实"账户余额或同步之间事件顺序的问题可能是不相关或无意义的。50
The basic phenomenon here is that synchronizing different processes, establishing shared state, or imposing an order on events requires communication among the processes. In essence, any notion of time in concurrency control must be intimately tied to communication.51 It is intriguing that a similar connection between time and communication also arises in the Theory of Relativity, where the speed of light (the fastest signal that can be used to synchronize events) is a fundamental constant relating time and space. The complexities we encounter in dealing with time and state in our computational models may in fact mirror a fundamental complexity of the physical universe.
34 大多数实际处理器实际上一次执行几个操作,遵循一种称为流水线的策略。虽然这种技术极大地提高了硬件利用率,但它仅用于加速顺序指令流的执行,同时保持顺序程序的行为。
35 引用剑桥某建筑墙上的涂鸦:"时间是一种发明出来防止所有事情同时发生的装置。"
36 这个系统的一个更严重的失败可能发生在两个 set! 操作试图同时更改余额时,在这种情况下,内存中实际出现的数据最终可能是两个进程正在写入的信息的随机组合。大多数计算机在原始内存写操作上有互锁机制,以防止这种同时访问。然而,即使这种看似简单的保护,在多处理计算机的设计中也带来了实现挑战,其中需要复杂的缓存一致性协议来确保各个处理器维护一致的内存内容视图,尽管数据可能在各个处理器之间被复制("缓存")以加快内存访问速度。
37 第 3.1.3 节中的阶乘程序说明了单个顺序进程的这种情况。
38 这些列显示了每次取款 (W) 和存款 (D) 前后 Peter 的钱包、联合账户(在 Bank1 中)、Paul 的钱包和 Paul 的私人账户(在 Bank2 中)的内容。Peter 从 Bank1 取出 $10;Paul 在 Bank2 存入 $5,然后从 Bank1 取出 $25。
39 表达这个想法的一种更形式化的方式是,并发程序本质上是非确定性的。也就是说,它们不是由单值函数描述的,而是由其结果是可能值集合的函数描述的。在第 4.3 节中,我们将学习一种用于表达非确定性计算的语言。
40 Parallel-execute 不是标准 Scheme 的一部分,但它可以在 MIT Scheme 中实现。在我们的实现中,新的并发进程也与原始 Scheme 进程并发运行。另外,在我们的实现中,parallel-execute 返回的值是一个特殊的控制对象,可用于停止新创建的进程。
41 我们通过利用 deposit 消息接受负金额的事实简化了 exchange。(这是我们银行系统中的一个严重 bug!)
42 如果账户余额初始为 $10、$20 和 $30,那么经过任意次数的并发交换后,余额仍然应该是 $10、$20 和 $30 的某种排列。对单个账户的存款进行串行化不足以保证这一点。见练习 3.43。
43 练习 3.45 研究了为什么存款和取款不再由账户自动串行化。
44 术语"mutex"是互斥的缩写。安排一种允许并发进程安全共享资源的机制的通用问题称为互斥问题。我们的互斥体是信号量机制的一个简单变体(见练习 3.47),信号量是在"THE"多道程序系统中引入的,该系统由埃因霍温理工大学开发,并以该校名的荷兰语首字母命名(Dijkstra 1968a)。获取和释放操作最初称为 P 和 V,来自荷兰语单词 passeren(通过)和 vrijgeven(释放),指的是铁路系统中使用的信号量。Dijkstra 的经典阐述(1968b)是最早清晰呈现并发控制问题的著作之一,并展示了如何使用信号量来处理各种并发问题。
45 在大多数分时操作系统中,被互斥体阻塞的进程不会像上面那样浪费"忙等"时间。相反,系统在第一个进程等待时会调度另一个进程运行,当互斥体变为可用时,被阻塞的进程会被唤醒。
46 在使用时间片模型的单处理器 MIT Scheme 中,test-and-set! 可以实现如下:
(define (test-and-set! cell)
(without-interrupts
(lambda ()
(if (car cell)
true
(begin (set-car! cell true)
false)))))
Without-interrupts 在其过程参数被执行期间禁用时间片中断。
47 这类指令有许多变体——包括 test-and-set、test-and-clear、swap、compare-and-exchange、load-reserve 和 store-conditional——它们的设计必须与机器的处理器-内存接口仔细匹配。这里出现的一个问题是,如果两个进程通过使用这样的指令几乎同时尝试获取同一资源,会发生什么。这需要某种机制来决定哪个进程获得控制权。这种机制称为仲裁器。仲裁器通常归结为某种硬件设备。不幸的是,可以证明,除非允许仲裁器花费任意长的时间来做出决定,否则不可能物理构造一个 100% 时间都工作的公平仲裁器。这里的基本现象最初由 14 世纪的法国哲学家让·布里丹在他的亚里士多德《论天》的评论中观察到。布里丹认为,一只完全理性的狗被放在两个同样有吸引力的食物来源之间会饿死,因为它无法决定先去哪一个。
48 通过编号共享资源并按顺序获取来避免死锁的通用技术归功于 Havender(1968)。无法避免死锁的情况需要死锁恢复方法,这需要进程"退出"死锁状态并重试。死锁恢复机制广泛应用于数据库管理系统中,Gray 和 Reuter(1993)详细讨论了这一主题。
49 串行化的一种替代方案称为屏障同步。程序员允许并发进程随意执行,但建立某些同步点("屏障"),在所有进程都到达屏障之前,任何进程都不能通过。现代处理器提供了允许程序员在需要一致性的地方建立同步点的机器指令。例如,PowerPCTM 为此目的包含了两条指令:SYNC 和 EIEIO(强制执行输入/输出的顺序)。
50 这看起来可能是一个奇怪的观点,但确实有系统以这种方式工作。例如,信用卡账户的国际收费通常按国家清算,不同国家产生的费用会定期对账。因此,账户余额在不同国家可能不同。
51 对于分布式系统,Lamport(1978)提出了这一观点,他展示了如何使用通信来建立"全局时钟",这些时钟可用于在分布式系统中建立事件的顺序。