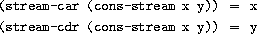
我们已经对赋值作为一种建模工具有了很好的理解,也对赋值所带来的复杂问题有了深刻认识。现在是时候问一问,我们是否能以不同的方式来处理问题,从而避免其中的一些问题。在本节中,我们将探索一种基于称为流的数据结构的状态建模的替代方法。正如我们将看到的,流可以缓解状态建模的某些复杂性。
让我们退一步,回顾一下这种复杂性从何而来。在试图对现实世界现象建模时,我们做出了一些看似合理的决定:我们用带有局部变量的计算对象来模拟具有局部状态的现实世界对象。我们将现实世界中的时间变化与计算机中的时间变化等同起来。我们通过对模型对象的局部变量进行赋值,在计算机中实现了模型对象状态的时间变化。
是否有另一种方法?我们能否避免将计算机中的时间与建模世界中的时间等同起来?为了对变化世界中的现象建模,我们是否必须让模型随时间变化?从数学函数的角度来思考这个问题。我们可以将量 x 的时变行为描述为时间 x(t) 的函数。如果我们专注于 x 的每一个瞬间,我们会认为它是一个变化的量。然而,如果我们专注于值的整个时间历史,我们就不强调变化——函数本身并不改变。52
如果时间以离散步长度量,那么我们可以将时间函数建模为一个(可能无穷的)序列。在本节中,我们将看到如何用表示被建模系统时间历史的序列来建模变化。为此,我们引入称为流的新数据结构。从抽象的角度来看,流就是一个序列。然而,我们会发现,将流直接实现为列表(如第 2.2.1 节所示)并不能完全展现流处理的能力。作为替代,我们引入了延迟求值技术,它使我们能够将非常大(甚至无穷)的序列表示为流。
流处理使我们能够在不使用赋值或可变数据的情况下对具有状态的系统建模。这具有重要的理论和实践意义,因为我们可以构建避免引入赋值所固有缺陷的模型。另一方面,流框架也带来了自身的困难,哪种建模技术能产生更模块化、更易维护的系统仍然是一个悬而未决的问题。
正如我们在第 2.2.3 节中看到的, 序列可以作为组合程序模块的标准接口。我们制定了用于操作序列的强大抽象,例如 map、filter 和 accumulate,它们以既简洁又优雅的方式捕获了各种各样的操作。
不幸的是,如果我们将序列表示为列表,这种优雅是以计算所需的时间和空间方面的严重低效为代价的。当我们将对序列的操作表示为列表的变换时,我们的程序必须在过程的每一步构造和复制(可能很大的)数据结构。
为了理解为什么确实如此,让我们比较两个程序,它们计算一个区间内所有素数的和。第一个程序以标准的迭代风格编写:53
(define (sum-primes a b)
(define (iter count accum)
(cond ((> count b) accum)
((prime? count) (iter (+ count 1) (+ count accum)))
(else (iter (+ count 1) accum))))
(iter a 0))
第二个程序使用第 2.2.3 节的序列操作执行相同的计算:
(define (sum-primes a b)
(accumulate +
0
(filter prime? (enumerate-interval a b))))
在执行计算时,第一个程序只需要存储正在累加的和。相比之下,第二个程序中的过滤器在 enumerate-interval 构造出区间内数字的完整列表之前无法进行任何测试。过滤器生成另一个列表,该列表又被传递给 accumulate,然后才被折叠成求和。第一个程序不需要这样的大型中间存储,我们可以将其视为增量式地枚举区间,每生成一个素数就将其加到总和中。
如果使用序列范式计算 10,000 到 1,000,000 区间内的第二个素数,通过求值表达式,使用列表的低效就会变得非常明显:
(car (cdr (filter prime?
(enumerate-interval 10000 1000000))))
这个表达式确实找到了第二个素数,但计算开销大得惊人。我们构造了一个近百万个整数的列表,通过测试每个元素的素性来过滤这个列表,然后忽略几乎所有的结果。在更传统的编程风格中,我们会将枚举和过滤交错进行,在找到第二个素数时停止。
流是一个巧妙的想法,它允许我们使用序列操作而不必承担将序列作为列表操作的成本。使用流,我们可以两全其美:我们可以优雅地将程序表述为序列操作,同时获得增量计算的效率。基本思路是安排只部分地构造流,并将部分构造的结果传递给消费流的程序。如果消费者试图访问流中尚未构造的部分,流将自动构造出足够多的自身来产生所需的部分,从而保持整个流存在的假象。换句话说,虽然我们将编写程序时好像是在处理完整的序列,但我们设计的流实现会自动且透明地将流的构造与其使用交错进行。
从表面上看,流只是列表,但操作它们的程序使用了不同的名字。有一个构造器 cons-stream 和两个选择器 stream-car 和 stream-cdr,它们满足约束条件
有一个可区分的对象 the-empty-stream,它不能是任何 cons-stream 操作的结果,并且可以通过谓词 stream-null? 来识别。54 因此,我们可以像制造和使用列表一样,制造和使用流来表示按序列排列的聚合数据。特别地,我们可以构建第 2 章中列表操作的流类比,例如 list-ref、map 和 for-each:55
(define (stream-ref s n)
(if (= n 0)
(stream-car s)
(stream-ref (stream-cdr s) (- n 1))))
(define (stream-map proc s)
(if (stream-null? s)
the-empty-stream
(cons-stream (proc (stream-car s))
(stream-map proc (stream-cdr s)))))
(define (stream-for-each proc s)
(if (stream-null? s)
'done
(begin (proc (stream-car s))
(stream-for-each proc (stream-cdr s)))))
Stream-for-each 对于查看流很有用:
(define (display-stream s)
(stream-for-each display-line s))
(define (display-line x)
(newline)
(display x))
为了自动且透明地将流的构造与其使用交错进行,我们将安排流的 cdr 在通过 stream-cdr 过程访问时才被求值,而不是在通过 cons-stream 构造流时就被求值。这种实现选择让人想起我们在第 2.1.2 节中对有理数的讨论,在那里我们看到可以选择实现有理数的方式,使得分子和分母的约分可以在构造时或选择时执行。这两种有理数实现产生相同的数据抽象,但选择会影响效率。流和普通列表之间也存在类似的关系。作为数据抽象,流与列表相同。区别在于元素被求值的时间。对于普通列表,car 和 cdr 都在构造时被求值。对于流,cdr 在选择时被求值。
我们对流的实现将基于一种称为 delay 的特殊形式。求值 (delay <exp>) 并不会求值表达式 <exp>,而是返回一个所谓的延迟对象,我们可以将其视为在未来某个时间求值 <exp> 的"承诺"。作为 delay 的伴侣,有一个称为 force 的过程,它接受一个延迟对象作为参数并执行求值——实际上就是强制 delay 兑现其承诺。我们将在下面看到如何实现 delay 和 force,但首先让我们使用它们来构造流。
(cons-stream <a> <b>)
等价于
(cons <a> (delay <b>))
这意味着我们将使用对偶来构造流。然而,我们不会将流剩余部分的值放入对偶的 cdr 中,而是放入一个承诺:如果被请求,就计算剩余部分。Stream-car 和 stream-cdr 现在可以定义为过程:
(define (stream-car stream) (car stream))
(define (stream-cdr stream) (force (cdr stream)))
Stream-car 选择对偶的 car;stream-cdr 选择对偶的 cdr 并对其中找到的延迟表达式求值,以获得流的其余部分。56
为了了解这个实作的行为,让我们分析上面看到的"惊人"素数计算,用流来重新表述:
(stream-car
(stream-cdr
(stream-filter prime?
(stream-enumerate-interval 10000 1000000))))
我们将看到它确实高效地工作。
我们首先用参数 10,000 和 1,000,000 调用 stream-enumerate-interval。Stream-enumerate-interval 是 enumerate-interval(第 2.2.3 节)的流类比:
(define (stream-enumerate-interval low high)
(if (> low high)
the-empty-stream
(cons-stream
low
(stream-enumerate-interval (+ low 1) high))))
因此 stream-enumerate-interval 通过 cons-stream 返回的结果是57
(cons 10000
(delay (stream-enumerate-interval 10001 1000000)))
也就是说,stream-enumerate-interval 返回一个表示为对偶的流,其 car 是 10,000,其 cdr 是一个承诺:如果被请求,就枚举更多的区间。现在使用 filter 过程的流类比(第 2.2.3 节)对该流进行素数过滤:
(define (stream-filter pred stream)
(cond ((stream-null? stream) the-empty-stream)
((pred (stream-car stream))
(cons-stream (stream-car stream)
(stream-filter pred
(stream-cdr stream))))
(else (stream-filter pred (stream-cdr stream)))))
Stream-filter 测试流的 stream-car(对偶的 car,即 10,000)。由于这不是素数,stream-filter 检查其输入流的 stream-cdr。对 stream-cdr 的调用强制对延迟的 stream-enumerate-interval 进行求值,现在返回
(cons 10001
(delay (stream-enumerate-interval 10002 1000000)))
Stream-filter 现在查看这个流的 stream-car,即 10,001,发现它也不是素数,于是强制另一个 stream-cdr,依此类推,直到 stream-enumerate-interval 产生素数 10,007,此时 stream-filter 根据其定义返回
(cons-stream (stream-car stream)
(stream-filter pred (stream-cdr stream)))
在这种情况下就是
(cons 10007
(delay
(stream-filter
prime?
(cons 10008
(delay
(stream-enumerate-interval 10009
1000000))))))
这个结果现在被传递给原始表达式中的 stream-cdr。这强制了延迟的 stream-filter,而它又继续强制延迟的 stream-enumerate-interval,直到找到下一个素数,即 10,009。最终,传递给原始表达式中 stream-car 的结果是
(cons 10009
(delay
(stream-filter
prime?
(cons 10010
(delay
(stream-enumerate-interval 10011
1000000))))))
Stream-car 返回 10,009,计算完成。只有找到第二个素数所需数量的整数被测试了素性,区间也只枚举到足以供给素数过滤器的程度。
一般来说,我们可以将延迟求值视为"需求驱动"编程,其中流过程中的每个阶段仅被激活到足以满足下一阶段的程度。我们所做的是将计算中事件的实际顺序与过程的表现结构分离。我们编写过程时仿佛流"同时"存在,而实际上计算是增量执行的,就像传统编程风格一样。
尽管 delay 和 force 看起来像是神秘的操作,但它们的实现实际上相当直接。Delay 必须打包一个表达式,以便以后按需求值,我们可以简单地将该表达式视为过程体来实现这一点。Delay 可以是一个特殊形式,使得
(delay <exp>)
是以下形式的语法糖
(lambda () <exp>)
Force 简单地调用由 delay 产生的(无参数的)过程,因此我们可以将 force 实现为一个过程:
(define (force delayed-object)
(delayed-object))
这个实现足以让 delay 和 force 按预期工作,但我们可以加入一个重要的优化。在许多应用中,我们最终会多次强制同一个延迟对象。这可能导致涉及流的递归程序出现严重的低效。(参见练习 3.57。)解决方案是构建延迟对象,使得第一次被强制时,它们存储计算出的值。后续的强制将简单地返回存储的值,而不重复计算。换句话说,我们将 delay 实现为一个特殊的记忆化过程,类似于练习 3.27 中描述的那样。实现这一点的一种方法是使用以下过程,它接受一个(无参数的)过程作为参数,并返回该过程的记忆化版本。第一次运行记忆化过程时,它保存计算结果。在后续求值时,它简单地返回结果。
(define (memo-proc proc)
(let ((already-run? false) (result false))
(lambda ()
(if (not already-run?)
(begin (set! result (proc))
(set! already-run? true)
result)
result))))
然后定义 Delay,使得 (delay <exp>) 等价于
(memo-proc (lambda () <exp>))
而 force 如前所述定义。58
练习 3.50. 完成以下定义,该定义将 stream-map 推广为允许接受多个参数的过程,类似于第 2.2.3 节中的 map,参见脚注 12。
(define (stream-map proc . argstreams)
(if (<??> (car argstreams))
the-empty-stream
(<??>
(apply proc (map <??> argstreams))
(apply stream-map
(cons proc (map <??> argstreams))))))
练习 3.51. 为了更仔细地观察延迟求值,我们将使用以下过程,该过程在打印其参数后简单地返回它:
(define (show x)
(display-line x)
x)
解释器在求值以下序列中的每个表达式时会打印什么?59
(define x (stream-map show (stream-enumerate-interval 0 10)))
(stream-ref x 5)
(stream-ref x 7)
(define sum 0)
(define (accum x)
(set! sum (+ x sum))
sum)
(define seq (stream-map accum (stream-enumerate-interval 1 20)))
(define y (stream-filter even? seq))
(define z (stream-filter (lambda (x) (= (remainder x 5) 0))
seq))
(stream-ref y 7)
(display-stream z)
在以上每个表达式求值之后,sum 的值是什么?求值 stream-ref 和 display-stream 表达式时打印的输出是什么?如果我们简单地将 (delay <exp>) 实现为 (lambda () <exp>) 而不使用 memo-proc 提供的优化,这些响应会不同吗?请解释。
我们已经看到如何支持将流作为完整实体来操作的假象,尽管实际上我们只计算我们需要访问的那部分流。我们可以利用这种技术高效地将序列表示为流,即使序列非常长。更引人注目的是,我们可以使用流来表示无穷长的序列。例如,考虑以下正整数流的定义:
(define (integers-starting-from n)
(cons-stream n (integers-starting-from (+ n 1))))
(define integers (integers-starting-from 1))
这是有道理的,因为 integers 将是一个对偶,其 car 为 1,其 cdr 是一个产生从 2 开始的整数的承诺。这是一个无穷长的流,但在任何给定时间,我们只能检查它的有限部分。因此,我们的程序永远不会知道整个无穷流并不在那里。
使用 integers,我们可以定义其他无穷流,例如不能被 7 整除的整数流:
(define (divisible? x y) (= (remainder x y) 0))
(define no-sevens
(stream-filter (lambda (x) (not (divisible? x 7)))
integers))
然后我们可以通过访问这个流的元素来找到不能被 7 整除的整数:
(stream-ref no-sevens 100)
117
与 integers 类似,我们可以定义无穷的斐波那契数流:
(define (fibgen a b)
(cons-stream a (fibgen b (+ a b))))
(define fibs (fibgen 0 1))
Fibs 是一个对偶,其 car 是 0,其 cdr 是一个求值 (fibgen 1 1) 的承诺。当我们求值这个延迟的 (fibgen 1 1) 时,它将产生一个对偶,其 car 是 1,其 cdr 是一个求值 (fibgen 1 2) 的承诺,依此类推。
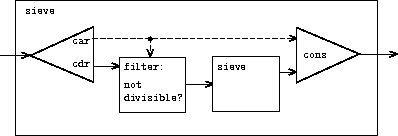
为了看一个更令人兴奋的无穷流,我们可以推广 no-sevens 示例,使用一种称为 埃拉托斯特尼筛法 的方法来构造无穷的素数流。60 我们从 2 开始的整数开始,2 是第一个素数。为了得到其余的素数,我们首先从剩下的整数中过滤掉 2 的倍数。这留下一个从 3 开始的流,3 是下一个素数。现在我们从这个流的剩余部分过滤掉 3 的倍数。这留下一个从 5 开始的流,5 是下一个素数,依此类推。换句话说,我们通过一个筛选过程来构造素数,描述如下:要筛选一个流 S,形成一个流,其第一个元素是 S 的第一个元素,其余部分通过从 S 的剩余部分中过滤掉第一个元素的所有倍数并对结果进行筛选而获得。这个过程很容易用流操作来描述:
(define (sieve stream)
(cons-stream
(stream-car stream)
(sieve (stream-filter
(lambda (x)
(not (divisible? x (stream-car stream))))
(stream-cdr stream)))))
(define primes (sieve (integers-starting-from 2)))
现在要找到特定的素数,我们只需要请求它:
(stream-ref primes 50)
233
思考由 sieve 建立的信号处理系统是很有趣的,如图 3.31 中的 "Henderson 图"所示。61 输入流进入一个"unconser",它将流的第一个元素与流的其余部分分开。第一个元素用于构造一个可整除性过滤器,其余部分通过该过滤器,过滤器的输出被送入另一个筛子盒子。然后将原始的第一个元素 cons 到内部筛子的输出上,形成输出流。因此,不仅流是无穷的,信号处理器也是无穷的,因为筛子内部包含了一个筛子。
|
上面的 integers 和 fibs 流是通过指定"生成"过程来定义的,这些过程显式地逐个计算流元素。另一种指定流的方式是利用延迟求值来隐式定义流。例如,以下表达式将流 ones 定义为一个无穷的 1 流:
(define ones (cons-stream 1 ones))
这很像递归过程的定义:ones 是一个对偶,其 car 是 1,其 cdr 是一个求值 ones 的承诺。求值 cdr 再次给我们一个 1 和一个求值 ones 的承诺,依此类推。
我们可以通过使用诸如 add-streams 之类的操作来操作流,从而做更有趣的事情,add-streams 产生两个给定流的逐元素和:62
(define (add-streams s1 s2)
(stream-map + s1 s2))
现在我们可以如下定义整数流:
(define integers (cons-stream 1 (add-streams ones integers)))
这将 integers 定义为一个流,其第一个元素是 1,其余部分是 ones 和 integers 的和。因此,integers 的第二个元素是 1 加上 integers 的第一个元素,即 2;integers 的第三个元素是 1 加上 integers 的第二个元素,即 3;依此类推。这个定义之所以有效,是因为在任何时候,integers 流已经生成了足够多的部分,以至于我们可以将其反馈回定义中,以产生下一个整数。
我们可以用同样的风格定义斐波那契数:
(define fibs
(cons-stream 0
(cons-stream 1
(add-streams (stream-cdr fibs)
fibs))))
这个定义表明 fibs 是一个以 0 和 1 开始的流,流的其余部分可以通过将 fibs 与自身平移一位后相加来生成:
| 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | ... = (stream-cdr fibs) | ||
| 0 | 1 | 1 | 2 | 3 | 5 | 8 | 13 | ... = fibs | ||
| 0 | 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 | ... = fibs |
Scale-stream 是制定此类流定义时的另一个有用过程。它将流中的每个项乘以一个给定的常数:
(define (scale-stream stream factor)
(stream-map (lambda (x) (* x factor)) stream))
例如,
(define double (cons-stream 1 (scale-stream double 2)))
产生 2 的幂的流:1, 2, 4, 8, 16, 32, ....
素数流的另一种定义可以通过从整数开始并测试素性来过滤它们而得到。我们需要第一个素数 2 来开始:
(define primes
(cons-stream
2
(stream-filter prime? (integers-starting-from 3))))
这个定义并不像看起来那么简单,因为我们将通过检查一个数 n 是否能被一个小于等于 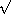 n 的素数(而不仅仅是任何整数)整除来测试 n 是否为素数:
n 的素数(而不仅仅是任何整数)整除来测试 n 是否为素数:
(define (prime? n)
(define (iter ps)
(cond ((> (square (stream-car ps)) n) true)
((divisible? n (stream-car ps)) false)
(else (iter (stream-cdr ps)))))
(iter primes))
这是一个递归定义,因为 primes 是根据 prime? 谓词定义的,而该谓词本身又使用了 primes 流。这个过程之所以有效,是因为在任何时候,primes 流已经生成了足够多的部分来测试我们需要检查的下一个数的素性。也就是说,对于我们测试素性的每个 n,要么 n 不是素数(在这种情况下,已经生成了一个能整除它的素数),要么 n 是素数(在这种情况下,已经生成了一个小于 n 但大于 n 的素数)。63
练习 3.53. 不运行程序,描述由以下定义所定义的流的元素
(define s (cons-stream 1 (add-streams s s)))
练习 3.54. 定义一个过程 mul-streams,类似于 add-streams,它产生两个输入流的逐元素乘积。将其与 integers 流一起使用,完成以下流的定义,该流的第 n 个元素(从 0 开始计数)是 n + 1 的阶乘:
(define factorials (cons-stream 1 (mul-streams <??> <??>)))
练习 3.55. 定义一个过程 partial-sums,它接受一个流 S 作为参数,并返回一个流,其元素为 S0, S0 + S1, S0 + S1 + S2, ...。例如,(partial-sums integers) 应该产生流 1, 3, 6, 10, 15, ...。
练习 3.56. 一个由 R. Hamming 首次提出的著名问题是,按升序无重复地枚举所有素因子不超过 2、3 或 5 的正整数。一种显而易见的方法是依次测试每个整数,看它是否有除 2、3 和 5 以外的因子。但这非常低效,因为随着整数变大,满足要求的整数越来越少。作为替代,让我们称所需的数流为 S,并注意关于它的以下事实。
现在我们所要做的就是将这些来源的元素组合起来。 为此,我们定义一个过程 merge,它将两个有序流合并为一个有序结果流,并消除重复:
(define (merge s1 s2)
(cond ((stream-null? s1) s2)
((stream-null? s2) s1)
(else
(let ((s1car (stream-car s1))
(s2car (stream-car s2)))
(cond ((< s1car s2car)
(cons-stream s1car (merge (stream-cdr s1) s2)))
((> s1car s2car)
(cons-stream s2car (merge s1 (stream-cdr s2))))
(else
(cons-stream s1car
(merge (stream-cdr s1)
(stream-cdr s2)))))))))
然后所需的流可以使用 merge 构造,如下所示:
(define S (cons-stream 1 (merge <??> <??>)))
填写上面标记为 <??> 的位置中缺失的表达式。
练习 3.57. 当我们使用基于 add-streams 过程的 fibs 定义计算第 n 个斐波那契数时,执行了多少次加法?证明如果我们将 (delay <exp>) 简单地实现为 (lambda () <exp>),而不使用第 3.5.1 节中描述的 memo-proc 过程提供的优化,那么加法次数将呈指数级增长。64
(define (expand num den radix)
(cons-stream
(quotient (* num radix) den)
(expand (remainder (* num radix) den) den radix)))
(Quotient 是一个返回两个整数之整数商的原始过程。) (expand 1 7 10) 产生的连续元素是什么?(expand 3 8 10) 产生什么?
练习 3.59. 在第 2.5.3 节中,我们看到了如何实现一个将多项式表示为项列表的多项式算术系统。类似地,我们可以处理幂级数,例如
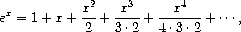
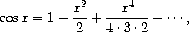
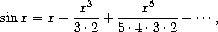
表示为无穷流。 我们将把级数 a0 + a1 x + a2 x2 + a3 x3 + ··· 表示为一个流,其元素是系数 a0, a1, a2, a3, ...。
a. 级数 a0 + a1 x + a2 x2 + a3 x3 + ··· 的积分为级数
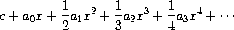
其中 c 为任意常数。 定义一个过程 integrate-series,它接受表示幂级数的流 a0, a1, a2, ... 作为输入,并返回该级数积分的非 常数项系数的流 a0, (1/2)a1, (1/3)a2, ...。 (由于结果没有常数项,它不代表幂级数;当我们使用 integrate-series 时,我们会 cons 上适当的常数。)
b. 函数 x  ex 是它自己的导数。这意味着 ex 和 ex 的积分是同一个级数,除了常数项 e0 = 1。
因此,我们可以生成 ex 的级数如下
ex 是它自己的导数。这意味着 ex 和 ex 的积分是同一个级数,除了常数项 e0 = 1。
因此,我们可以生成 ex 的级数如下
(define exp-series
(cons-stream 1 (integrate-series exp-series)))
展示如何从正弦的导数是余弦,余弦的导数是负正弦这一事实出发,生成正弦和余弦的级数:
(define cosine-series
(cons-stream 1 <??>))
(define sine-series
(cons-stream 0 <??>))
练习 3.60. 在如练习 3.59 所示的将幂级数表示为系数流的情况下,级数加法由 add-streams 实现。完成以下用于级数乘法的过程的定义:
(define (mul-series s1 s2)
(cons-stream <??> (add-streams <??> <??>)))
你可以通过验证 sin2 x + cos2 x = 1 来测试你的过程,使用练习 3.59 中的级数。
练习 3.61. 设 S 是一个常数项为 1 的幂级数(练习 3.59)。假设我们想找到幂级数 1/S,即满足 S · X = 1 的级数 X。将 S 写为 S = 1 + SR,其中 SR 是 S 在常数项之后的部分。然后我们可以如下求解 X:
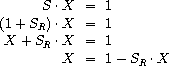
换句话说,X 是一个常数项为 1 的幂级数,其高阶项由 SR 乘以 X 的负值给出。 使用这个想法编写一个过程 invert-unit-series,它计算常数项为 1 的幂级数 S 的 1/S。 你需要使用练习 3.60 中的 mul-series。
练习 3.62. 使用练习 3.60 和 3.61 的结果定义一个过程 div-series,用于对两个幂级数进行除法。Div-series 应该适用于任意两个级数,前提是分母级数以非零常数项开头。(如果分母的常数项为零,则 div-series 应该报错。) 展示如何使用 div-series 结合练习 3.59 的结果生成 正切函数的幂级数。
具有延迟求值的流可以成为一种强大的建模工具,提供了局部状态和赋值的许多好处。 此外,它们避免了将赋值引入编程语言所带来的一些理论上的纠缠。
流方法可以给人启发,因为它允许我们构建具有不同模块边界的系统,与围绕状态变量赋值组织的系统不同。例如,我们可以将整个时间序列(或信号)作为关注的焦点,而不是各个时刻状态变量的值。这使得组合和比较来自不同时刻的状态组成部分变得很方便。
在第 1.2.1 节中,我们介绍了迭代过程,它通过更新状态变量来进行。我们现在知道,我们可以将状态表示为值的"无时间"流,而不是一组要被更新的变量。让我们采用这种视角重新审视第 1.1.7 节中的平方根过程。回忆一下,其思想是通过反复应用改进猜测的过程来生成对 x 的平方根的越来越好的猜测序列:
(define (sqrt-improve guess x)
(average guess (/ x guess)))
在我们最初的 sqrt 过程中,我们让这些猜测成为一个状态变量的连续值。相反,我们可以生成无穷的猜测流,从初始猜测 1 开始:65
(define (sqrt-stream x)
(define guesses
(cons-stream 1.0
(stream-map (lambda (guess)
(sqrt-improve guess x))
guesses)))
guesses)
(display-stream (sqrt-stream 2))
1.
1.5
1.4166666666666665
1.4142156862745097
1.4142135623746899
...
我们可以生成越来越多的流项以获得越来越好的猜测。如果我们愿意,我们可以编写一个过程,不断生成项直到答案足够好为止。(参见练习 3.64。)
另一个我们可以用同样方式处理的迭代是生成  的近似值,基于我们在第 1.3.1 节中看到的交错级数:
的近似值,基于我们在第 1.3.1 节中看到的交错级数:
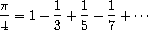
我们首先生成该级数的各项的流(奇整数的倒数,符号交替)。然后我们取越来越多项的和的流(使用练习 3.55 的 partial-sums 过程)并将结果乘以 4:
(define (pi-summands n)
(cons-stream (/ 1.0 n)
(stream-map - (pi-summands (+ n 2)))))
(define pi-stream
(scale-stream (partial-sums (pi-summands 1)) 4))
(display-stream pi-stream)
4.
2.666666666666667
3.466666666666667
2.8952380952380956
3.3396825396825403
2.9760461760461765
3.2837384837384844
3.017071817071818
...
这给了我们一个越来越好的 近似值流,虽然这些近似值收敛得相当慢。该序列的八个项将 的值界定在 3.284 和 3.017 之间。
到目前为止,我们对状态流方法的使用与更新状态变量没有太大区别。但是流给了我们机会去做一些有趣的技巧。例如,我们可以使用序列加速器来转换一个流,它将一个近似值序列转换为一个新的收敛到相同值但更快的序列。
这样一种加速器归功于十八世纪的瑞士数学家莱昂哈德·欧拉,它适用于交错级数(符号交替的项组成的级数)的部分和序列。在欧拉技术中,如果 Sn 是原始和序列的第 n 项,那么加速后的序列的项为
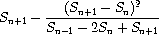
因此,如果原始序列表示为一个值流,则变换后的序列由以下给出
(define (euler-transform s)
(let ((s0 (stream-ref s 0)) ; Sn-1
(s1 (stream-ref s 1)) ; Sn
(s2 (stream-ref s 2))) ; Sn+1
(cons-stream (- s2 (/ (square (- s2 s1))
(+ s0 (* -2 s1) s2)))
(euler-transform (stream-cdr s)))))
我们可以用我们的 近似值序列来演示欧拉加速:
(display-stream (euler-transform pi-stream))
3.166666666666667
3.1333333333333337
3.1452380952380956
3.13968253968254
3.1427128427128435
3.1408813408813416
3.142071817071818
3.1412548236077655
...
更好的是,我们可以加速已加速的序列,然后递归地加速它,依此类推。也就是说,我们创建一个流的流(一种我们称之为表列的结构),其中每个流都是前一个流的变换:
(define (make-tableau transform s)
(cons-stream s
(make-tableau transform
(transform s))))
该表列的形式为

最后,我们通过取表列中每一行的第一项来形成一个序列:
(define (accelerated-sequence transform s)
(stream-map stream-car
(make-tableau transform s)))
我们可以演示这种对 序列的"超级加速":
(display-stream (accelerated-sequence euler-transform
pi-stream))
4.
3.166666666666667
3.142105263157895
3.141599357319005
3.1415927140337785
3.1415926539752927
3.1415926535911765
3.141592653589778
...
结果令人印象深刻。取序列的八个项就得到了 的 14 位小数的正确值。如果我们只使用原始的 序列,我们需要计算大约 1013 个项(即,将级数展开到足够远,使得单个项小于 10-13)才能获得如此高的精度!
我们本可以不使用流来实现这些加速技术。但流的表述方式特别优雅和方便,因为整个状态序列作为一个数据结构可供我们使用,可以用统一的一组操作来操纵。
练习 3.63. Louis Reasoner 问道,为什么 sqrt-stream 过程没有按以下更直接的方式编写,而不使用局部变量 guesses:
(define (sqrt-stream x)
(cons-stream 1.0
(stream-map (lambda (guess)
(sqrt-improve guess x))
(sqrt-stream x))))
Alyssa P. Hacker 回答说,这个版本的效率要低得多,因为它执行了冗余计算。解释 Alyssa 的回答。如果我们的 delay 实现只使用 (lambda () <exp>) 而不使用 memo-proc(第 3.5.1 节)提供的优化,这两个版本在效率上仍然不同吗?
练习 3.64. 编写一个过程 stream-limit,它接受一个流和一个数(容差)作为参数。它应该检查流,直到找到两个连续的元素,它们的绝对差值小于容差,并返回这两个元素中的第二个。使用这个,我们可以通过以下方式计算达到给定容差的平方根:
(define (sqrt x tolerance)
(stream-limit (sqrt-stream x) tolerance))
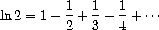
以与上面计算 相同的方式,计算 2 的自然对数的三个近似值序列。这些序列收敛的速度有多快?
在第 2.2.3 节中,我们看到了序列范式如何处理传统的嵌套循环,作为定义在对偶序列上的过程。如果我们将这种技术推广到无穷流,那么我们可以编写不容易表示为循环的程序,因为"循环"必须遍历一个无穷集合。
例如,假设我们想推广第 2.2.3 节中的 prime-sum-pairs 过程,以产生所有满足 i < j 且 i + j 为素数的整数对 (i,j) 的流。如果 int-pairs 是所有满足 i < j 的整数对 (i,j) 的序列,那么我们所需的流就是66
(stream-filter (lambda (pair)
(prime? (+ (car pair) (cadr pair))))
int-pairs)
那么,我们的问题就是产生流 int-pairs。更一般地,假设我们有两个流 S = (Si) 和 T = (Tj),并想象一个无穷的矩形数组
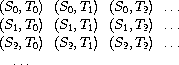
我们希望生成一个流,包含数组中所有位于对角线上或对角线以上的对偶,即对偶
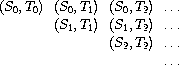
(如果我们将 S 和 T 都设为整数流,那么这就是我们想要的流 int-pairs。)
将通用的对偶流称为 (pairs S T),并认为它由三部分组成:对偶 (S0,T0)、第一行中其余的对偶以及剩下的对偶:67
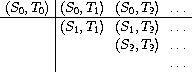
观察这个分解中的第三部分(不在第一行中的对偶)是(递归地)由 (stream-cdr S) 和 (stream-cdr T) 形成的对偶。还要注意第二部分(第一行的其余部分)是
(stream-map (lambda (x) (list (stream-car s) x))
(stream-cdr t))
因此我们可以如下形成我们的对偶流:
(define (pairs s t)
(cons-stream
(list (stream-car s) (stream-car t))
(<combine-in-some-way>
(stream-map (lambda (x) (list (stream-car s) x))
(stream-cdr t))
(pairs (stream-cdr s) (stream-cdr t)))))
为了完成这个过程,我们必须选择某种方式来组合这两个内部流。一种想法是使用第 2.2.1 节中 append 过程的流类比:
(define (stream-append s1 s2)
(if (stream-null? s1)
s2
(cons-stream (stream-car s1)
(stream-append (stream-cdr s1) s2))))
然而,这不适用于无穷流,因为它在合入第二个流之前,先取第一个流中的所有元素。特别地,如果我们尝试使用以下代码生成所有正整数对
(pairs integers integers)
那么我们的结果流将首先试图遍历所有第一个整数为 1 的对偶,因此永远不会产生第一个整数为其他任何值的对偶。
为了处理无穷流,我们需要设计一种组合顺序,确保如果我们让程序运行足够长时间,每个元素最终都会被访问到。实现这一点的一种优雅方式是使用以下 interleave 过程:68
(define (interleave s1 s2)
(if (stream-null? s1)
s2
(cons-stream (stream-car s1)
(interleave s2 (stream-cdr s1)))))
由于 interleave 交替地从两个流中取元素,第二个流中的每个元素最终都会进入交错后的流中,即使第一个流是无穷的。
因此,我们可以如下生成所需的对偶流
(define (pairs s t)
(cons-stream
(list (stream-car s) (stream-car t))
(interleave
(stream-map (lambda (x) (list (stream-car s) x))
(stream-cdr t))
(pairs (stream-cdr s) (stream-cdr t)))))
练习 3.66. 检查流 (pairs integers integers)。你能对对偶被放入流的顺序给出一些一般性的评论吗?例如,大约有多少个对偶排在 (1,100) 之前?(99,100) 之前?(100,100) 之前?(如果你能在此给出精确的数学陈述,那就更好了。但如果你发现自己陷入困境,也可以自由给出更定性的回答。)
练习 3.67. 修改 pairs 过程,使得 (pairs integers integers) 产生所有整数对 (i,j) 的流(没有 i < j 的条件)。提示:你需要混入一个额外的流。
练习 3.68. Louis Reasoner 认为从三部分构建对偶流不必要地复杂。他没有将对偶 (S0,T0) 与第一行中其余对偶分开,而是提议直接处理整个第一行,如下所示:
(define (pairs s t)
(interleave
(stream-map (lambda (x) (list (stream-car s) x))
t)
(pairs (stream-cdr s) (stream-cdr t))))
这能行吗?考虑如果我们使用 Louis 的 pairs 定义来求值 (pairs integers integers) 会发生什么。
练习 3.69. 编写一个过程 triples,它接受三个无穷流 S, T 和 U,并产生满足 i < j < k 的三元组 (Si,Tj,Uk) 的流。使用 triples 生成所有正整数毕达哥拉斯三元组的流,即满足 i < j 且 i2 + j2 = k2 的三元组 (i,j,k)。
练习 3.70. 如果能生成对偶以某种有用的顺序出现(而不是来自特设交错过程产生的顺序)的流,那就太好了。我们可以使用类似于练习 3.56 中 merge 过程的技术,如果我们定义一种方式来表示一对整数"小于"另一对。一种方法是定义一个"加权函数" W(i,j),并规定如果 W(i1,j1) < W(i2,j2),则 (i1,j1) 小于 (i2,j2)。编写一个过程 merge-weighted,它类似于 merge,不同之处在于 merge-weighted 接受一个额外的参数 weight,该参数是计算对偶权重的过程,用于确定元素在生成合并流中出现的顺序。69 使用这个,将 pairs 推广到一个过程 weighted-pairs,它接受两个流以及一个计算加权函数的过程,并按权重顺序生成对偶流。使用你的过程生成
a. 所有满足 i < j 的正整数对 (i,j) 的流,按和 i + j 排序
b. 所有满足 i < j 的正整数对 (i,j) 的流,其中 i 和 j 都不能被 2、3 或 5 整除,并且对偶按以下和排序:2 i + 3 j + 5 i j。
练习 3.71. 可以用不止一种方式表示为两个立方数之和的数有时被称为拉马努金数,以纪念数学家 Srinivasa Ramanujan。70有序对偶流为计算这些数的问题提供了一个优雅的解决方案。要找到一个可以用两种不同方式表示为两个立方数之和的数,我们只需要生成按 i3 + j3 加权的整数对 (i,j) 的流(见练习 3.70),然后在流中搜索具有相同权重的两个连续对偶。编写一个过程来生成拉马努金数。第一个这样的数是 1,729。接下来的五个是什么?
练习 3.72. 以类似于练习 3.71 的方式,生成一个流,包含所有可以用三种不同方式表示为两个平方数之和的数(并展示它们如何这样表示)。
我们开始讨论流时,将其描述为信号处理系统中"信号"的计算模拟。事实上,我们可以以一种非常直接的方式使用流来建模信号处理系统,将信号在连续时间间隔上的值表示为流的连续元素。例如,我们可以实现一个积分器或累加器,对于输入流 x = (xi)、初始值 C 和小的增量 dt,它累加和
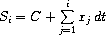
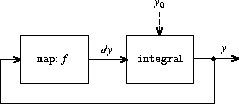
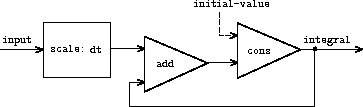
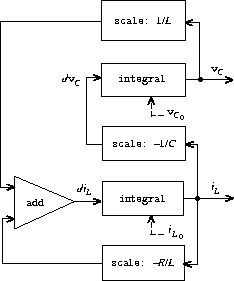
并返回值 S = (Si) 的流。下面的 integral 过程让人想起整数流的"隐式风格"定义(第 3.5.2 节):
(define (integral integrand initial-value dt)
(define int
(cons-stream initial-value
(add-streams (scale-stream integrand dt)
int)))
int)
|
图 3.32 是一个对应于 integral 过程的信号处理系统的图示。输入流被 dt 缩放后通过一个加法器,其输出被传递回同一个加法器。int 定义中的自引用反映在图中连接加法器输出到其中一个输入的反馈回路上。
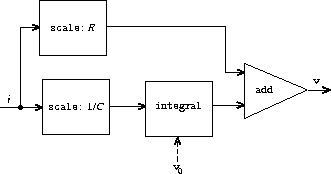
我们可以使用流来表示一系列时间上的电流或电压值,从而对电路进行建模。例如,假设我们有一个由电阻为 R 的电阻器和电容为 C 的电容器串联组成的 RC 电路。电路对注入电流 i 的电压响应 v 由图 3.33 中的公式确定,其结构由附带的信号流图显示。
编写一个过程 RC 来建模这个电路。RC 应该接受 R、C 和 dt 的值作为输入,并返回一个过程,该过程接受代表电流 i 的流和电容器电压 v0 的初始值作为输入,并产生电压 v 的流作为输出。例如,你应该能够通过求值 (define RC1 (RC 5 1 0.5)),使用 RC 来建模一个 R = 5 欧姆、C = 1 法拉、时间步长 0.5 秒的 RC 电路。这将 RC1 定义为一个过程,它接受代表电流时间序列的流和电容器的初始电压,并产生输出电压的流。
练习 3.74. Alyssa P. Hacker 正在设计一个系统来处理来自物理传感器的信号。她希望产生的一个重要特征是描述输入信号的过零的信号。也就是说,当输入信号从负变为正时,结果信号应为 +1;当输入信号从正变为负时,结果信号应为 -1;否则为 0。(假设 0 输入的符号为正。)例如,一个典型的输入信号及其相关的过零信号将是
...1 2 1.5 1 0.5 -0.1 -2 -3 -2 -0.5 0.2 3 4 ...... 0 0 0 0 0 -1 0 0 0 0 1 0 0 ...
在 Alyssa 的系统中,来自传感器的信号被表示为流 sense-data,而流 zero-crossings 是相应的过零流。Alyssa 首先编写了一个过程 sign-change-detector,它接受两个值作为参数,并比较这些值的符号以产生适当的 0、1 或 -1。然后她如下构造她的过零流:
(define (make-zero-crossings input-stream last-value)
(cons-stream
(sign-change-detector (stream-car input-stream) last-value)
(make-zero-crossings (stream-cdr input-stream)
(stream-car input-stream))))
(define zero-crossings (make-zero-crossings sense-data 0))
Alyssa 的上司 Eva Lu Ator 走过来说,这个程序大致等价于以下使用练习 3.50 中通用版本 stream-map 的程序:
(define zero-crossings
(stream-map sign-change-detector sense-data <expression>))
通过提供所指示的 <expression> 来完成程序。
练习 3.75. 不幸的是,练习 3.74 中 Alyssa 的过零检测器被证明是不够的,因为来自传感器的含噪信号会导致虚假的过零。硬件专家 Lem E. Tweakit 建议 Alyssa 在提取过零之前对信号进行平滑处理以滤除噪声。Alyssa 接受了他的建议,并决定从通过对每个感知数据值与前一个值取平均而构建的信号中提取过零。她向她的助理 Louis Reasoner 解释了这个问题,他尝试实现这个想法,修改了 Alyssa 的程序如下:
(define (make-zero-crossings input-stream last-value)
(let ((avpt (/ (+ (stream-car input-stream) last-value) 2)))
(cons-stream (sign-change-detector avpt last-value)
(make-zero-crossings (stream-cdr input-stream)
avpt))))
这并没有正确实现 Alyssa 的计划。找出 Louis 引入的错误,并在不改变程序结构的情况下修复它。(提示:你需要增加 make-zero-crossings 的参数数量。)
练习 3.76. Eva Lu Ator 对 Louis 在练习 3.75 中的方法提出了批评。他编写的程序不是模块化的,因为它将平滑操作与过零提取混合在一起。例如,如果 Alyssa 找到更好的方法来调节她的输入信号,提取器不应该需要修改。帮助 Louis 编写一个过程 smooth,它以流作为输入,并产生一个流,其中每个元素是两个连续输入流元素的平均值。然后使用 smooth 作为一个组件,以更模块化的风格实现过零检测器。
前一节末尾的 integral 过程展示了我们如何使用流来建模包含反馈回路的信号处理系统。图 3.32 中所示的加法器的反馈回路是通过 integral 的内部流 int 根据自身定义这一事实来建模的:
(define int
(cons-stream initial-value
(add-streams (scale-stream integrand dt)
int)))
解释器处理这种隐式定义的能力依赖于被合并到 cons-stream 中的 delay。没有这个 delay,解释器无法在求值 cons-stream 的两个参数之前构造 int,而这要求 int 已经被定义。一般来说,delay 对于使用流建模包含回路的信号处理系统至关重要。没有 delay,我们的模型必须被表述为任何信号处理组件的输入在输出产生之前被完全求值。这将禁止回路的存在。
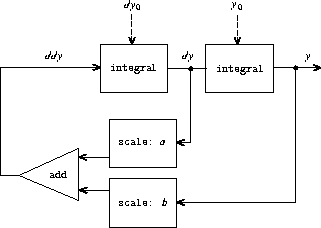
不幸的是,具有回路的系统的流模型可能需要使用超出 cons-stream 提供的"隐藏"delay 之外的 delay。例如,图 3.34 展示了一个求解微分方程 dy/dt = f(y) 的信号处理系统,其中 f 是一个给定函数。该图显示了一个映射组件,它将 f 应用于其输入信号,并以与实际用于求解此类方程的模拟计算机电路非常相似的方式连接到一个积分器的反馈回路中。
假设我们得到了 y 的初始值 y0,我们可以尝试使用以下过程来建模这个系统
(define (solve f y0 dt)
(define y (integral dy y0 dt))
(define dy (stream-map f y))
y)
这个过程中 solve 的第一行调用 integral 要求输入 dy 已经被定义,而这要到 solve 的第二行才发生,因此该过程不起作用。
另一方面,我们的定义意图是有意义的,因为我们原则上可以在不知道 dy 的情况下开始生成 y 流。事实上,integral 和许多其他流操作具有类似于 cons-stream 的特性,即我们可以仅凭参数的部分信息就能生成部分答案。对于 integral,输出流的第一个元素是指定的 initial-value。因此,我们可以在不求值被积函数 dy 的情况下生成输出流的第一个元素。一旦我们知道 y 的第一个元素,solve 第二行中的 stream-map 就可以开始工作,生成 dy 的第一个元素,这将产生 y 的下一个元素,以此类推。
为了利用这个想法,我们将重新定义 integral,使其期望被积函数流是一个延迟参数。Integral 将仅在需要生成超过输出流第一个元素时才 force 被积函数被求值:
(define (integral delayed-integrand initial-value dt)
(define int
(cons-stream initial-value
(let ((integrand (force delayed-integrand)))
(add-streams (scale-stream integrand dt)
int))))
int)
现在我们可以通过在 y 的定义中延迟 dy 的求值来实现我们的 solve 过程:71
(define (solve f y0 dt)
(define y (integral (delay dy) y0 dt))
(define dy (stream-map f y))
y)
一般来说,integral 的每个调用者现在都必须 delay 被积函数参数。我们可以通过计算微分方程 dy/dt = y 在初始条件 y(0) = 1 下的解在 y = 1 处的值来近似 e  2.718,从而证明 solve 过程有效:
2.718,从而证明 solve 过程有效:
(stream-ref (solve (lambda (y) y) 1 0.001) 1000)
2.716924
练习 3.77. 上面使用的 integral 过程类似于第 3.5.2 节中无穷整数流的"隐式"定义。或者,我们可以给出一个更像 integers-starting-from(也在第 3.5.2 节中)的 integral 定义:
(define (integral integrand initial-value dt)
(cons-stream initial-value
(if (stream-null? integrand)
the-empty-stream
(integral (stream-cdr integrand)
(+ (* dt (stream-car integrand))
initial-value)
dt))))
当在带有回路的系统中使用时,这个过程与我们的原始 integral 版本有相同的问题。修改该过程,使其期望 integrand 作为一个延迟参数,从而可以在上面展示的 solve 过程中使用。
|
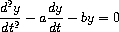
建模 y 的输出流由一个包含回路的网络生成。这是因为 d2y/dt2 的值依赖于 y 和 dy/dt 的值,而这两者又通过对 d2y/dt2 积分确定。我们想要编码的图如图 3.35 所示。编写一个过程 solve-2nd,它以常数 a、b 和 dt 以及 y 和 dy/dt 的初始值 y0 和 dy0 作为参数,并生成 y 的连续值的流。
练习 3.79. 推广练习 3.78 的 solve-2nd 过程,使其能够用于求解一般的二阶微分方程 d2 y/dt2 = f(dy/dt, y)。
练习 3.80. 串联 RLC 电路由一个电阻器、一个电容器和一个电感器串联组成,如图 3.36 所示。如果 R、L 和 C 分别是电阻、电感和电容,那么这三个元件的电压(v)和电流(i)之间的关系由以下方程描述:
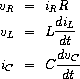
电路的连接决定了以下关系:
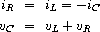
组合这些方程表明,电路的状态(由电容器两端的电压 vC 和电感器中的电流 iL 概括)由以下一对微分方程描述:
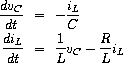
表示这个微分方程系统的信号流图如图 3.37 所示。
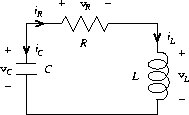
|
|
编写一个过程 RLC,它以电路的参数 R、L 和 C 以及时间增量 dt 作为参数。以类似于练习 3.73 中 RC 过程的方式,RLC 应该产生一个过程,该过程接受状态变量的初始值 vC0 和 iL0,并产生一个(使用 cons)状态 vC 和 iL 的流对。使用 RLC,生成一个串联 RLC 电路的行为模型的对偶流,其中 R = 1 欧姆,C = 0.2 法拉,L = 1 亨利,dt = 0.1 秒,初始值 iL0 = 0 安培,vC0 = 10 伏特。
本节中的示例说明了显式使用 delay 和 force 如何提供了极大的编程灵活性,但同样的示例也展示了这如何使我们的程序变得更加复杂。例如,我们新的 integral 过程给了我们建模带有回路的系统的能力,但我们现在必须记住,integral 应该用延迟的被积函数来调用,每个使用 integral 的过程都必须意识到这一点。实际上,我们创建了两类过程:普通过程和接受延迟参数的过程。一般来说,创建单独的过程类别也迫使我们创建单独的高阶过程类别。72
避免需要两类过程的一种方法是使所有过程都接受延迟参数。我们可以采用一种求值模型,其中过程的所有参数都被自动延迟,并且参数仅在实际需要时才被强制求值(例如,当它们被一个基本操作需要时)。这将把我们的语言转换为使用正则序求值,我们在第 1.1.5 节中介绍求值的替换模型时首次描述了这一概念。转换为正则序求值提供了一种统一而优雅的方式来简化延迟求值的使用,如果我们只关心流处理,这将是一种自然的策略。在第 4.2 节中,在研究了求值器之后,我们将看到如何以这种方式转换我们的语言。 不幸的是,在过程调用中包含延迟会严重破坏我们设计依赖于事件顺序的程序的能力,例如使用赋值、修改数据或执行输入/输出的程序。即使是 cons-stream 中的单个 delay 也可能造成很大的混乱,如练习 3.51 和 3.52 所示。就目前所知,可变性和延迟求值在编程语言中不能很好地混合,同时处理这两者的方法是一个活跃的研究领域。
正如我们在第 3.1.2 节中所看到的,引入赋值的主要好处之一是,我们可以通过将大型系统状态的部分封装或"隐藏"在局部变量中来增加系统的模块化程度。流模型可以在不使用赋值的情况下提供等效的模块化。作为说明,我们可以从流处理的角度重新实现我们在第 3.1.2 节中研究的 的蒙特卡洛估计。
关键的模块化问题是我们希望向使用随机数的程序隐藏随机数生成器的内部状态。我们从一个过程 rand-update 开始,其连续的值提供了我们的随机数供应,并用它来产生一个随机数生成器:
(define rand
(let ((x random-init))
(lambda ()
(set! x (rand-update x))
x)))
在流的表述中,没有随机数生成器本身,只有通过连续调用 rand-update 产生的随机数流:
(define random-numbers
(cons-stream random-init
(stream-map rand-update random-numbers)))
我们用它来构造对 random-numbers 流中连续对偶执行 Cesàro 实验的结果流:
(define cesaro-stream
(map-successive-pairs (lambda (r1 r2) (= (gcd r1 r2) 1))
random-numbers))
(define (map-successive-pairs f s)
(cons-stream
(f (stream-car s) (stream-car (stream-cdr s)))
(map-successive-pairs f (stream-cdr (stream-cdr s)))))
cesaro-stream 现在被送入一个 monte-carlo 过程,该过程产生一个概率估计值的流。然后结果被转换为 的估计值流。这个版本的程序不需要一个参数来告诉它要执行多少次试验。通过查看 pi 流中更远的部分,可以获得更好的 估计值(通过执行更多的实验):
(define (monte-carlo experiment-stream passed failed)
(define (next passed failed)
(cons-stream
(/ passed (+ passed failed))
(monte-carlo
(stream-cdr experiment-stream) passed failed)))
(if (stream-car experiment-stream)
(next (+ passed 1) failed)
(next passed (+ failed 1))))
(define pi
(stream-map (lambda (p) (sqrt (/ 6 p)))
(monte-carlo cesaro-stream 0 0)))
这种方法具有相当大的模块化性,因为我们仍然可以制定一个通用的 monte-carlo 过程来处理任意实验。而且没有赋值或局部状态。
练习 3.81. 练习 3.6 讨论了推广随机数生成器,以允许重置随机数序列,从而产生可重复的"随机"数序列。给出同一个生成器的流的表述,它在输入流上操作,接收 generate(生成新随机数)或 reset(将序列重置为指定值)的请求,并产生所需的随机数流。在你的解决方案中不要使用赋值。
练习 3.82. 用流重做关于蒙特卡洛积分的练习 3.5。estimate-integral 的流版本将没有一个参数告诉它要执行多少次试验。相反,它将产生一个基于越来越多的试验的估计值流。
现在让我们回到本章开头提出的对象和状态的问题,并以新的眼光来审视它们。我们引入赋值和可变对象是为了提供一种机制来模块化地构建对具有状态的系统进行建模的程序。我们构建了带有局部状态变量的计算对象,并使用赋值来修改这些变量。我们通过相应计算对象的时间行为来建模世界中对象的时间行为。
现在我们已经看到,流提供了另一种建模具有局部状态的对象的方式。我们可以使用表示连续状态时间历史的流来建模一个变化的量,例如某个对象的局部状态。本质上,我们使用流显式地表示时间,从而将模拟世界中的时间与求值过程中发生的事件序列解耦。实际上,由于 delay 的存在,模型中的模拟时间与求值过程中的事件顺序之间可能几乎没有关系。
为了对比这两种建模方法,让我们重新考虑一个监控银行账户余额的"取款处理器"的实现。在第 3.1.3 节中,我们实现了这样一个处理器的简化版本:
(define (make-simplified-withdraw balance)
(lambda (amount)
(set! balance (- balance amount))
balance))
调用 make-simplified-withdraw 产生计算对象,每个对象都有一个局部状态变量 balance,该变量被对该对象的连续调用递减。该对象接受一个 amount 作为参数并返回新的余额。我们可以想象一个银行账户的用户向这样的对象输入一系列金额,并观察显示屏幕上显示的一系列返回值。
或者,我们可以将取款处理器建模为一个过程,它接受一个余额和一个取款金额流作为输入,并产生账户中连续余额的流:
(define (stream-withdraw balance amount-stream)
(cons-stream
balance
(stream-withdraw (- balance (stream-car amount-stream))
(stream-cdr amount-stream))))
Stream-withdraw 实现了一个定义良好的数学函数,其输出完全由其输入决定。然而,假设输入 amount-stream 是用户输入的连续值的流,并且生成的余额流被显示出来。那么,从正在输入值并观察结果的用户的角度来看,流处理具有与 make-simplified-withdraw 创建的对象相同的行为。但是,使用流版本,没有赋值,没有局部状态变量,因此也没有我们在第 3.1.3 节中遇到的理论上的困难。然而,系统确实有状态!
这确实非常了不起。尽管 stream-withdraw 实现了一个定义良好的数学函数,其行为不会改变,但用户在这里的感知是与一个具有变化状态的系统进行交互。解决这个悖论的一种方法是认识到,正是用户的时间性存在将状态强加于系统。如果用户能够从交互中退后一步,从余额流而非单个交易的角度思考,那么系统将表现为无状态的。73
从一个复杂过程的某一部分的角度来看,其他部分似乎随时间变化。它们具有隐藏的随时间变化的局部状态。如果我们希望用计算机中的结构来编写对我们世界中这种自然分解(正如我们从作为世界一部分的角度所看到的)进行建模的程序,我们就会创建非函数式的计算对象——它们必须随时间变化。我们用局部状态变量来建模状态,用对这些变量的赋值来建模状态的变化。通过这样做,我们使计算的执行时间对我们所处的世界中的时间进行建模,从而在计算机中得到"对象"。
用对象建模是强大且直观的,主要是因为这符合我们与作为其中一部分的世界进行交互的感知。然而,正如我们在这章中反复看到的,这些模型引发了关于约束事件顺序和同步多个进程的棘手问题。避免这些问题的可能性刺激了函数式编程语言的发展,这些语言不包括任何赋值或可变数据的设施。在这样的语言中,所有过程都实现其参数的定义良好的数学函数,其行为不会改变。函数式方法对于处理并发系统非常具有吸引力。74
另一方面,如果我们仔细观察,我们会发现与时间相关的问题也悄然进入了函数式模型中。一个特别麻烦的领域出现在我们希望设计交互式系统时,尤其是那些对独立实体之间交互进行建模的系统。例如,再次考虑实现一个允许联合银行账户的银行系统。在使用赋值和对象的传统系统中,我们会通过让 Peter 和 Paul 都将他们的交易请求发送到同一个银行账户对象来建模他们共享账户的事实,正如我们在第 3.1.3 节中所见。从流的角度来看,没有"对象"本身,我们已经指出银行账户可以被建模为一个过程,该过程对交易请求流进行操作以产生响应流。因此,我们可以通过将 Peter 的交易请求流与 Paul 的请求流合并,并将结果送入银行账户流过程来建模 Peter 和 Paul 拥有联合银行账户的事实,如图 3.38 所示。
这种表述的问题在于合并的概念。仅仅通过交替从 Peter 取一个请求和从 Paul 取一个请求来合并两个流是不够的。假设 Paul 很少访问账户。我们很难强迫 Peter 在发出第二笔交易之前等待 Paul 访问账户。无论合并如何实现,它都必须以某种受 Peter 和 Paul 感知的"实时"约束的方式交错两个交易流,意思是,如果 Peter 和 Paul 见面,他们可以同意某些交易是在会面之前处理的,而其他交易是在会面之后处理的。75 这正是我们在第 3.4.1 节中必须处理的相同约束,我们发现需要引入显式同步来确保具有状态的对象并发处理中的"正确"事件顺序。因此,在试图支持函数式风格时,合并来自不同主体的输入的需要重新引入了函数式风格本意要消除的相同问题。
我们开始这一章时,目标是构建其结构与我们试图建模的现实世界的感知相匹配的计算模型。我们可以将世界建模为具有状态的、有时间限制的、相互交互的对象的集合,或者我们可以将世界建模为一个单一的、无时间的、无状态的统一体。每种观点都有强大的优势,但单独任何一种观点都不完全令人满意。一个伟大的统一尚未出现。76
52 物理学家有时通过引入粒子的"世界线"作为推理运动的手段来采用这种观点。我们也已经提到过(第 2.2.3 节)这是思考信号处理系统的自然方式。我们将在第 3.5.3 节中探讨流在信号处理中的应用。
53 假设我们有一个测试素性的谓词 prime?(例如,如第 1.2.6 节所示)。
54 在 MIT 的实现中,the-empty-stream 与空列表 '() 相同,stream-null? 与 null? 相同。
55 这应该让你感到困扰。我们为流和列表定义如此相似的过程的事实表明我们缺少某种底层抽象。不幸的是,为了利用这种抽象,我们需要对求值过程进行比目前更精细的控制。我们将在第 3.5.4 节末尾进一步讨论这一点。在第 4.2 节中,我们将开发一个统一列表和流的框架。
56 虽然 stream-car 和 stream-cdr 可以定义为过程,但 cons-stream 必须是一种特殊形式。如果 cons-stream 是一个过程,那么根据我们的求值模型,求值 (cons-stream <a> <b>) 会自动导致 <b> 被求值,而这正是我们不希望发生的事情。出于同样的原因,delay 必须是一种特殊形式,尽管 force 可以是一个普通过程。
57 这里显示的数字实际上并不出现在延迟表达式中。实际出现的是原始表达式,在一个变量被绑定到适当数字的环境中。例如,在显示 10001 的地方,实际出现的是 (+ low 1),其中 low 绑定到 10,000。
58 除了本节描述的实现之外,还有许多可能的流实现。延迟求值是使流实用的关键,它内在于 Algol 60 的按名调用参数传递方法中。使用这种机制来实现流首先由 Landin (1965) 描述。流的延迟求值由 Friedman 和 Wise (1976) 引入 Lisp。在他们的实现中,cons 总是延迟求值其参数,因此列表自动表现为流。记忆化优化也被称为 按需调用。Algol 社区会将我们原始的延迟对象称为按名调用 thunk,并将优化后的版本称为按需调用 thunk。
59 诸如 3.51 和 3.52 这样的练习对于测试我们对 delay 工作原理的理解很有价值。另一方面,将延迟求值与打印——更糟糕的是,与赋值——混合在一起是极其令人困惑的,计算机语言课程的讲师传统上会用本节中的这类考题来折磨学生。不用说,编写依赖于这种微妙之处的程序是一种令人厌恶的编程风格。流处理的部分力量在于它让我们忽略程序中事件实际发生的顺序。不幸的是,这正是我们在有赋值存在的情况下不能承受的,因为赋值迫使我们关注时间和变化。
60 Eratosthenes,公元前三世纪的亚历山大希腊哲学家,以首次准确估算地球周长而闻名,他通过观察夏至日正午投射的阴影进行了计算。埃拉托斯特尼的筛法虽然古老,但构成了专用硬件"筛子"的基础,直到最近,这些筛子还是现存用于寻找大素数的最强大工具。然而,自 70 年代以来,这些方法已被第 1.2.6 节中讨论的概率技术的衍生方法所取代。
61 我们以Peter Henderson 的名字命名这些图,他是第一个向我们展示这种作为思考流处理方式的图的人。每条实线代表正在传输的值流。从 car 到 cons 和 filter 的虚线表示这是一个单一的值而不是一个流。
62 这使用了练习 3.50 中 stream-map 的通用版本。
63 最后这一点非常微妙,依赖于 pn+1 < pn2 这个事实。(这里 pk 表示第 k 个素数。)这样的估计非常难以建立。欧几里得关于素数有无穷多个的古老证明表明 pn+1< p1 p2 ··· pn + 1,直到 1851 年才证明了实质上更好的结果,当时俄罗斯数学家 P. L. Chebyshev 建立了 对所有 n 有 pn+1< 2pn。这个最初于 1845 年猜想的结果被称为伯特兰假设。其证明见 Hardy and Wright 1960 第 22.3 节。
64 这个练习展示了按需调用与练习 3.27 中描述的普通记忆化如何密切相关。在那个练习中,我们使用赋值显式构造了一个局部表。我们的按需调用流优化有效地自动构造了这样一个表,将值存储在流中先前被强制求值的部分。
65 我们不能使用 let 来绑定局部变量 guesses,因为 guesses 的值依赖于 guesses 自身。练习 3.63 讨论了为什么我们在这里需要局部变量。
66 如同在第 2.2.3 节中,我们将整数对表示为列表而不是 Lisp 对偶。
67 参见练习 3.68,了解我们为什么选择这种分解的一些见解。
68 对组合顺序所需属性的精确表述如下:应该存在一个两个参数的函数 f,使得对应于第一个流中元素 i 和第二个流中元素 j 的对偶将作为输出流的第 f(i,j) 个元素出现。使用 interleave 来完成这一点的技巧由 David Turner 展示给我们,他在 KRC 语言中使用了它(Turner 1981)。
69 我们将要求加权函数满足:当我们沿着一行向外移动或沿着一列向下移动时,对偶的权重增加。
70 引用 G. H. Hardy 为 Ramanujan 所写的讣告(Hardy 1921):"(我相信是)Littlewood 先生曾评论说,'每个正整数都是他的朋友之一。'我记得有一次去 Putney 看望卧病在床的他。我当时乘坐的是 1729 号出租车,并评论说这个数字在我看来相当枯燥,我希望这不是一个不吉利的预兆。'不,'他回答说,'这是一个非常有趣的数字;它是可以用两种不同方式表示为两个立方数之和的最小数。'" 使用加权对偶生成拉马努金数的技巧是由 Charles Leiserson 展示给我们的。
71 这个过程不能保证在所有 Scheme 实现中都能工作,尽管对于任何实现,都有一个简单的变体可以工作。这个问题与 Scheme 实现处理内部定义的方式之间的微妙差异有关。(参见第 4.1.6 节。)
72 这是 Lisp 中传统强类型语言(如 Pascal)在处理高阶过程时遇到的困难的一个小小反映。在这样的语言中,程序员必须指定每个过程的参数和结果的数据类型:数字、逻辑值、序列等等。因此,我们无法通过像 stream-map 这样的单个高阶过程来表达像"将给定过程 proc 映射到序列中的所有元素上"这样的抽象。相反,对于可能为 proc 指定的每种参数和结果数据类型的组合,我们需要一个不同的映射过程。在高阶过程存在的情况下维护"数据类型"的实用概念引发了许多困难的问题。处理这个问题的一种方法由 ML 语言 (Gordon, Milner, and Wadsworth 1979)说明,其"多态数据类型"包括数据类型之间高阶变换的模板。此外,ML 中大多数过程的数据类型从未由程序员显式声明。相反,ML 包含一个类型推断机制,使用环境中的信息来推断新定义过程的数据类型。
73 类似地,在物理学中,当我们观察一个运动粒子时,我们说粒子的位置(状态)在变化。然而,从粒子在时空中的世界线的角度来看,并不涉及变化。
74 John Backus,Fortran 的发明者,在 1978 年获得 ACM 图灵奖时,极大地提升了函数式编程的能见度。他的获奖演讲(Backus 1978)强烈倡导函数式方法。Henderson 1980 以及 Darlington, Henderson 和 Turner 1982 提供了函数式编程的良好概述。
75 注意,对于任意两个流,通常存在不止一种可接受的交错顺序。因此,从技术上讲,"合并"是一种关系而非函数——答案不是输入的确定性函数。我们已经提到(脚注 39),非确定性在处理并发时是必不可少的。合并关系从函数式角度说明了同样的本质上的非确定性。在第 4.3 节中,我们将从另一个角度来看非确定性。
76 对象模型通过将世界划分为独立的部分来近似世界。函数式模型不沿对象边界进行模块化。对象模型在"对象"的非共享状态远大于它们共享的状态时很有用。对象观点失败的一个例子是量子力学,其中将事物视为单个粒子会导致悖论和困惑。统一对象观点与函数式观点可能与编程关系不大,而更多地与基本的认识论问题相关。
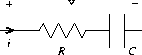 v = v0 + (1/C)
v = v0 + (1/C) 0ti dt + R i
0ti dt + R i