|
第 2 章将复合数据作为构造具有多个部分的计算对象的手段,以便对具有多个方面的现实世界对象进行建模。在该章中,我们介绍了数据抽象的规范,根据该规范,数据结构由构造器(创建数据对象)和选择器(访问复合数据对象的部分)来指定。但现在我们知道数据还有另一个方面是第 2 章没有涉及的。对由具有变化状态的对象组成的系统进行建模的愿望,使我们不仅需要构造和选择复合数据对象,还需要修改它们。为了对具有变化状态的复合对象进行建模,我们将设计数据抽象,使其除了包含选择器和构造器之外,还包含称为修改器的操作,这些操作修改数据对象。例如,对银行系统进行建模需要我们更改账户余额。因此,表示银行账户的数据结构可能允许一个操作
(set-balance! <account> <new-value>)
该操作将指定账户的余额更改为指定的新值。定义了修改器的数据对象称为可变数据对象.
第 2 章介绍了将对偶作为合成复合数据的通用"粘合剂"。我们从定义对偶的基本修改器开始本节,以便对偶可以作为构造可变数据对象的构建块。这些修改器极大地增强了对偶的表征能力,使我们能够构建除了第 2.2 节中使用的序列和树之外的数据结构。我们还提供了一些模拟示例,其中复杂系统被建模为具有局部状态的对象集合。
对偶的基本操作——cons, car, 和 cdr——可用于构造列表结构并从列表结构中选择部件,但它们无法修改列表结构。我们迄今为止使用的列表操作也是如此,例如 append 和 list,,因为它们可以用 cons, car, 和 cdr. 来定义。要修改列表结构,我们需要新的操作。
|
|
|
|
|
对偶的基本修改器是 set-car! 和 set-cdr!。Set-car! 接受两个参数,第一个必须是一个对偶。它修改这个对偶,将对偶的 car 指针替换为指向 set-car! 的第二个参数的指针。16
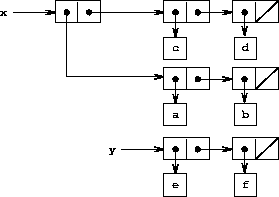
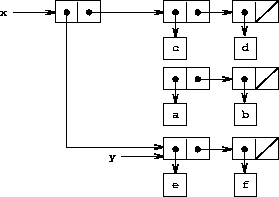
的指针。x 被绑定到列表 ((a b) c d) 和 y 被绑定到列表 (e f) 如图 figure 3.12. 求值表达式 (set-car! x y) 修改 x 所绑定到的对偶,将其 car 替换为 y. 该操作的结果显示在 figure 3.13. 结构 x 已被修改,现在将打印为 ((e f) c d)。 表示列表 (a b) 的对偶(由被替换的指针所标识)现在已从原始结构中分离。17
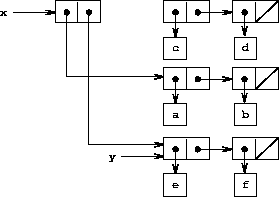
将图 3.13 与图 3.14 进行比较, 后者展示了在 x 和 y 绑定到图 3.12 的原始列表时,执行 (define z (cons y (cdr x))) 的结果。变量 z 现在绑定到由 cons 操作创建的一个新对偶;而 x 所绑定到的列表保持不变。
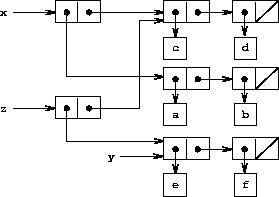
Set-cdr! 操作与 set-car! 类似。 唯一的区别在于被替换的是对偶的 cdr 指针,而不是 car 指针。在图 3.12 的列表上执行 (set-cdr! x y) 的效果如图 3.15 所示。 这里 x 的 cdr 指针已被替换为指向 (e f) 的指针。同时,原本是 x 的 cdr 的列表 (c d) 现在从结构中分离。
Cons 通过创建新对偶来构建新的列表结构,而 set-car! 和 set-cdr! 修改现有的对偶。实际上,我们可以用这两个修改器来实现 cons,再加上一个过程 get-new-pair,它返回一个不属于任何现有列表结构的新对偶。我们获取新对偶,将其 car 和 cdr 指针设置为指定的对象,然后返回新对偶作为 cons 的结果。18
(define (cons x y)
(let ((new (get-new-pair)))
(set-car! new x)
(set-cdr! new y)
new))
练习 3.12. 以下是第 2.2.1 节中介绍的用于追加列表的过程:
(define (append x y)
(if (null? x)
y
(cons (car x) (append (cdr x) y))))
Append 通过将 x 的元素逐个 cons 到 y 上来形成一个新列表。过程 append! 类似于 append,但它是一个修改器而非构造器。它通过拼接列表来追加,修改 x 的最后一个对偶,使其 cdr 成为 y。(对空 x 调用 append! 是错误的。)
(define (append! x y)
(set-cdr! (last-pair x) y)
x)
这里 last-pair 是一个返回其参数中最后一个对偶的过程:
(define (last-pair x)
(if (null? (cdr x))
x
(last-pair (cdr x))))
考虑以下交互
(define x (list 'a 'b))
(define y (list 'c 'd))
(define z (append x y))
z
(a b c d)
(cdr x)
<response>
(define w (append! x y))
w
(a b c d)
(cdr x)
<response>
缺失的 <response> 是什么? 画出盒子和指针图来解释你的答案。
练习 3.13. Consider the following make-cycle procedure, which uses the last-pair procedure defined in exercise 3.12:
(define (make-cycle x)
(set-cdr! (last-pair x) x)
x)
画出一个盒子和指针图,显示由以下代码创建的 z 的结构:
(define z (make-cycle (list 'a 'b 'c)))
如果我们尝试计算 (last-pair z),会发生什么?
(define (mystery x)
(define (loop x y)
(if (null? x)
y
(let ((temp (cdr x)))
(set-cdr! x y)
(loop temp x))))
(loop x '()))
Loop 使用"临时"变量 temp 来保存 x 的 cdr 的旧值,因为下一行的 set-cdr! 会销毁 cdr。请解释 mystery 总体上做了什么。假设 v 由 (define v (list 'a 'b 'c 'd)) 定义。画出表示 v 所绑定到的列表的盒子和指针图。假设我们现在求值 (define w (mystery v))。画出显示求值此表达式后 v 和 w 的结构的盒子和指针图。 v 和 w 的值会打印出什么?
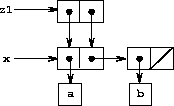
我们在第 3.1.3 节中提到了引入赋值所引发的"同一性"和"变化"的理论问题。当单个对偶在不同数据对象之间共享时,这些问题在实践中就会出现。例如,考虑由以下代码形成的结构:
(define x (list 'a 'b))
(define z1 (cons x x))
如图 3.16 所示,z1 是一个 car 和 cdr 都指向同一个对偶 x 的对偶。z1 的 car 和 cdr 对 x 的这种共享是 cons 的直接实现方式的结果。一般来说,使用 cons 构造列表将产生一个对偶互连的结构,其中许多单个对偶被许多不同的结构共享。
|
|
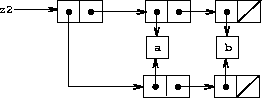
与图 3.16 不同,图 3.17 显示了由以下代码创建的结构:
(define z2 (cons (list 'a 'b) (list 'a 'b)))
在这个结构中,两个 (a b) 列表中的对偶是不同的,尽管实际的符号是共享的。19
当被视为列表时,z1 和 z2 都表示"相同"的列表 ((a b) a b)。一般来说,如果我们只使用 cons、car 和 cdr 对列表进行操作,共享是完全检测不到的。然而,如果我们允许对列表结构进行修改,共享就变得重要了。作为共享可能带来的差异的一个例子,考虑以下过程,它修改其所应用到的结构的 car:
(define (set-to-wow! x)
(set-car! (car x) 'wow)
x)
尽管 z1 和 z2 是"相同"的结构,但对其应用 set-to-wow! 会产生不同的结果。对于 z1,修改 car 也会改变 cdr,因为在 z1 中 car 和 cdr 是同一个对偶。对于 z2,car 和 cdr 是不同的,所以 set-to-wow! 只修改 car:
z1
((a b) a b)
(set-to-wow! z1)
((wow b) wow b)
z2
((a b) a b)
(set-to-wow! z2)
((wow b) a b)
检测列表结构中共享的一种方法是使用谓词 eq?,我们在第 2.3.1 节中将其作为测试两个符号是否相等的方式引入。更一般地,(eq? x y) 测试 x 和 y 是否是同一个对象(即 x 和 y 作为指针是否相等)。因此,对于图 3.16 和 3.17 中定义的 z1 和 z2,(eq? (car z1) (cdr z1)) 为真,而 (eq? (car z2) (cdr z2)) 为假。
正如在以下各节中将会看到的,我们可以利用共享来极大地扩展可以用对偶表示的数据结构的范围。另一方面,共享也可能是危险的,因为对结构所做的修改也会影响其他碰巧共享了被修改部分的结构。修改操作 set-car! 和 set-cdr! 应谨慎使用;除非我们很好地理解数据对象是如何共享的,否则修改可能会产生意想不到的结果。20
练习 3.15. 画出盒子和指针图,解释 set-to-wow! 对上述结构 z1 和 z2 的影响。
练习 3.16. Ben Bitdiddle 决定编写一个过程来计算任何列表结构中的对偶数目。"这很容易,"他推理道。"任何结构中的对偶数等于 car 中的数目加上 cdr 中的数目,再加一个来计数当前对偶。"于是 Ben 编写了以下过程:
(define (count-pairs x)
(if (not (pair? x))
0
(+ (count-pairs (car x))
(count-pairs (cdr x))
1)))
证明这个过程是不正确的。特别地,画出恰好由三个对偶组成的列表结构的盒子和指针图,对于这些结构,Ben 的过程会返回 3;返回 4;返回 7;以及永远不返回。
练习 3.17. 设计一个正确的 count-pairs 过程版本(来自练习 3.16),该过程返回任何结构中不同对偶的数目。(提示:遍历该结构,维护一个辅助数据结构,用于跟踪哪些对偶已经被计数。)
练习 3.18. 编写一个过程,检查一个列表并确定它是否包含环,也就是说,一个试图通过连续取 cdr 来找到列表末尾的程序是否会进入无限循环。练习 3.13 构造了这样的列表。
练习 3.19. 使用只需要常量空间的算法重做练习 3.18。(这需要一个非常巧妙的想法。)
当我们引入复合数据时,我们在第 2.1.3 节中观察到,对偶可以纯粹用过程来表示:
(define (cons x y)
(define (dispatch m)
(cond ((eq? m 'car) x)
((eq? m 'cdr) y)
(else (error "Undefined operation -- CONS" m))))
dispatch)
(define (car z) (z 'car))
(define (cdr z) (z 'cdr))
同样的观察也适用于可变数据。我们可以使用赋值和局部状态将可变数据对象实现为过程。例如,我们可以扩展上述对偶实现来处理 set-car! 和 set-cdr!,方式类似于我们在第 3.1.1 节中使用 make-account 实现银行账户:
(define (cons x y)
(define (set-x! v) (set! x v))
(define (set-y! v) (set! y v))
(define (dispatch m)
(cond ((eq? m 'car) x)
((eq? m 'cdr) y)
((eq? m 'set-car!) set-x!)
((eq? m 'set-cdr!) set-y!)
(else (error "Undefined operation -- CONS" m))))
dispatch)
(define (car z) (z 'car))
(define (cdr z) (z 'cdr))
(define (set-car! z new-value)
((z 'set-car!) new-value)
z)
(define (set-cdr! z new-value)
((z 'set-cdr!) new-value)
z)
从理论上讲,要解释可变数据的行为,赋值就是所需要的全部。一旦我们在语言中允许 set!,我们就引发了所有问题,不仅是赋值的问题,还有一般的可变数据的问题。21
练习 3.20. 画出环境图来说明以下表达式序列的求值过程:
(define x (cons 1 2))
(define z (cons x x))
(set-car! (cdr z) 17)
(car x)
17
使用上面给出的对偶的过程式实现。(比较练习 3.11。)
修改器 set-car! 和 set-cdr! 使我们能够使用对偶来构造无法仅用 cons、car 和 cdr 构建的数据结构。本节展示如何使用对偶来表示一种称为队列的数据结构。第 3.3.3 节将展示如何表示称为表格的数据结构。
队列是一种序列,其中元素在一端(称为队列的尾部)插入,并从另一端(前端)删除。图 3.18 显示了一个最初为空的队列,其中插入了元素 a 和 b。然后 a 被移除,c 和 d 被插入,然后 b 被移除。由于元素总是按照它们被插入的顺序被移除,队列有时被称为 FIFO(先进先出)缓冲区。
| ||||||||||||||||
因为队列是一个元素序列,我们当然可以将其表示为一个普通的列表;队列的前端就是列表的 car,在队列中插入一个元素相当于在列表末尾追加一个新元素,而从队列中删除一个元素就是取列表的 cdr。然而,这种表示是低效的,因为为了插入一个元素,我们必须扫描列表直到到达末尾。由于我们扫描列表的唯一方法是连续进行 cdr 操作,这种扫描对于一个有 n 个元素的列表需要  (n) 步。对这种列表表示的一个简单修改克服了这个缺点,它允许队列操作的实现只需要 (1) 步;也就是说,所需的步数与队列的长度无关。
(n) 步。对这种列表表示的一个简单修改克服了这个缺点,它允许队列操作的实现只需要 (1) 步;也就是说,所需的步数与队列的长度无关。
列表表示法的困难在于需要扫描才能找到列表的末尾。我们需要扫描的原因是,尽管将列表表示为对偶链的标准方式很容易为我们提供指向列表开头的指针,但它没有给我们一个容易访问的指向末尾的指针。避免这个缺点的修改是将队列表示为一个列表,再加上一个指示列表中最后一个对偶的额外指针。这样,当我们要插入一个元素时,我们可以查询尾部指针,从而避免扫描列表。
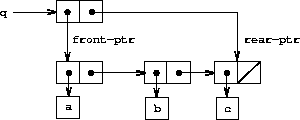
于是,队列被表示为一对指针 front-ptr 和 rear-ptr,分别指示普通列表中的第一个和最后一个对偶。由于我们希望队列是一个可识别的对象,我们可以使用 cons 来组合这两个指针。因此,队列本身将是这两个指针的 cons。图 3.19 说明了这种表示。
|
为了定义队列操作,我们使用以下过程,这些过程使我们能够选择和修改队列的前端和尾部指针:
(define (front-ptr queue) (car queue))
(define (rear-ptr queue) (cdr queue))
(define (set-front-ptr! queue item) (set-car! queue item))
(define (set-rear-ptr! queue item) (set-cdr! queue item))
现在我们可以实现实际的队列操作。如果队列的前端指针是空列表,我们将认为该队列为空:
(define (empty-queue? queue) (null? (front-ptr queue)))
Make-queue 构造器返回一个对偶作为初始的空队列,其 car 和 cdr 都是空列表:
(define (make-queue) (cons '() '()))
要选择队列前端的元素,我们返回前端指针所指示的对偶的 car:
(define (front-queue queue)
(if (empty-queue? queue)
(error "FRONT called with an empty queue" queue)
(car (front-ptr queue))))
要在队列中插入一个元素,我们采用图 3.20 中所示结果的方法。我们首先创建一个新对偶,其 car 是要插入的元素,cdr 是空列表。如果队列最初为空,我们将队列的前端和尾部指针设置为这个新对偶。否则,我们修改队列中的最后一个对偶使其指向新对偶,并将尾部指针也设置为新对偶。
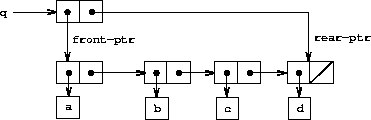
|
(define (insert-queue! queue item)
(let ((new-pair (cons item '())))
(cond ((empty-queue? queue)
(set-front-ptr! queue new-pair)
(set-rear-ptr! queue new-pair)
queue)
(else
(set-cdr! (rear-ptr queue) new-pair)
(set-rear-ptr! queue new-pair)
queue))))
要删除队列前端的元素,我们只需修改前端指针,使其现在指向队列中的第二个元素,这可以通过跟随第一个元素的 cdr 指针找到(见图 3.21):22
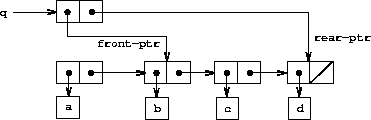
|
(define (delete-queue! queue)
(cond ((empty-queue? queue)
(error "DELETE! called with an empty queue" queue))
(else
(set-front-ptr! queue (cdr (front-ptr queue)))
queue)))
练习 3.21. Ben Bitdiddle 决定测试上述队列实现。他将过程输入 Lisp 解释器并开始尝试:
(define q1 (make-queue))
(insert-queue! q1 'a)
((a) a)
(insert-queue! q1 'b)
((a b) b)
(delete-queue! q1)
((b) b)
(delete-queue! q1)
(() b)
"全错了!"他抱怨道。"解释器的响应显示最后一个元素被插入了队列两次。当我删除两个元素时,第二个 b 仍然在那里,所以队列不是空的,尽管它应该是空的。"Eva Lu Ator 指出 Ben 误解了正在发生的事情。"并不是元素被插入了队列两次,"她解释道。"只是标准的 Lisp 打印机不知道如何理解队列的表示。如果你想让队列正确地打印出来,你需要为队列定义你自己的打印过程。"解释 Eva Lu 在说什么。特别地,说明为什么 Ben 的示例产生了它们所做的打印结果。定义一个过程 print-queue,它接受一个队列作为输入并打印队列中的元素序列。
练习 3.22. 我们可以不将队列表示为一对指针,而是将队列构建为具有局部状态的过程。局部状态将包括指向普通列表开头和结尾的指针。因此,make-queue 过程将具有以下形式:
(define (make-queue)
(let ((front-ptr ...)
(rear-ptr ...))
<definitions of internal procedures>
(define (dispatch m) ...)
dispatch))
完成 make-queue 的定义,并使用这种表示提供队列操作的实现。
练习 3.23. 双端队列是一种序列,其中元素可以在前端或尾部插入和删除。双端队列的操作包括构造器 make-deque、谓词 empty-deque?、选择器 front-deque 和 rear-deque,以及修改器 front-insert-deque!、rear-insert-deque!、front-delete-deque! 和 rear-delete-deque!。说明如何使用对偶表示双端队列,并给出操作的实现。23
所有操作应在 (1) 步内完成。
当我们在第 2 章研究表示集合的各种方法时,我们在第 2.3.3 节中提到了维护一个由标识键索引的记录表格的任务。在第 2.4.3 节的数据导向编程实现中,我们广泛使用了二维表格,其中信息使用两个键进行存储和检索。这里我们看看如何将表格构建为可变的列表结构。
我们首先考虑一维表格,其中每个值存储在一个单独的键下。我们将表格实现为一个记录列表,每个记录实现为一个由键和关联值组成的对偶。记录通过对偶粘合在一起形成一个列表,这些对偶的 car 指向连续的记录。这些粘合对偶被称为表格的骨架。为了在向表格添加新记录时有一个可以修改的位置,我们将表格构建为带头列表。带头列表在开头有一个特殊的骨架对偶,它持有一个虚拟的"记录"——在这个例子中,是任意选择的符号 *table*。图 3.22 显示了表格的盒子和指针图:
a: 1
b: 2
c: 3
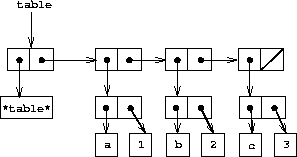
|
要从表格中提取信息,我们使用 lookup 过程,它接受一个键作为参数并返回关联的值(如果没有在该键下存储值,则返回 false)。Lookup 是根据 assoc 操作定义的,assoc 期望一个键和一个记录列表作为参数。注意 assoc 永远不会看到虚拟记录。Assoc 返回具有给定键作为其 car 的记录。24 然后 Lookup 检查 assoc 返回的结果记录不是 false,并返回该记录的 cdr(值)。
(define (lookup key table)
(let ((record (assoc key (cdr table))))
(if record
(cdr record)
false)))
(define (assoc key records)
(cond ((null? records) false)
((equal? key (caar records)) (car records))
(else (assoc key (cdr records)))))
要在表格中指定键下插入一个值,我们首先使用 assoc 检查表中是否已经存在具有该键的记录。如果没有,我们通过将键与值 cons 来形成一条新记录,并将其插入到表格记录列表的开头,在虚拟记录之后。如果已经存在具有该键的记录,我们将该记录的 cdr 设置为指定的新值。表格的头部为我们提供了一个固定的位置来进行修改,以便插入新记录。25
(define (insert! key value table)
(let ((record (assoc key (cdr table))))
(if record
(set-cdr! record value)
(set-cdr! table
(cons (cons key value) (cdr table)))))
'ok)
要构造一个新表格,我们只需创建一个包含符号 *table* 的列表:
(define (make-table)
(list '*table*))
在二维表格中,每个值由两个键索引。我们可以将这样的表格构造为一维表格,其中每个键标识一个子表。 图 3.23 显示了以下表格的盒子和指针图:
math:
+: 43
-: 45
*: 42
letters:
a: 97
b: 98
该表格有两个子表。(子表不需要特殊的头部符号,因为标识子表的键就起到了这个作用。)
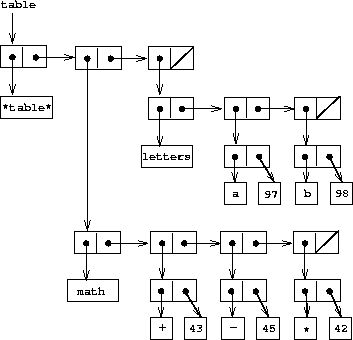
|
当我们查找一个元素时,我们使用第一个键来标识正确的子表。然后我们使用第二个键来标识子表中的记录。
(define (lookup key-1 key-2 table)
(let ((subtable (assoc key-1 (cdr table))))
(if subtable
(let ((record (assoc key-2 (cdr subtable))))
(if record
(cdr record)
false))
false)))
要在一对键下插入一个新元素,我们使用 assoc 检查第一个键下是否存储了子表。如果没有,我们构建一个包含单条记录(key-2、value)的新子表,并将其插入到第一个键下的表格中。如果第一个键已经存在一个子表,我们使用上述一维表格的插入方法将新记录插入到这个子表中:
(define (insert! key-1 key-2 value table)
(let ((subtable (assoc key-1 (cdr table))))
(if subtable
(let ((record (assoc key-2 (cdr subtable))))
(if record
(set-cdr! record value)
(set-cdr! subtable
(cons (cons key-2 value)
(cdr subtable)))))
(set-cdr! table
(cons (list key-1
(cons key-2 value))
(cdr table)))))
'ok)
上面定义的 lookup 和 insert! 操作将表格作为参数。这使得我们可以使用访问多个表格的程序。处理多个表格的另一种方式是为每个表格拥有独立的 lookup 和 insert! 过程。我们可以通过将表格表示为过程式对象来实现这一点,该对象将内部表格作为其局部状态的一部分来维护。当收到适当的消息时,这个"表格对象"提供用于操作内部表格的过程。以下是一个以这种方式表示的二维表格的生成器:
(define (make-table)
(let ((local-table (list '*table*)))
(define (lookup key-1 key-2)
(let ((subtable (assoc key-1 (cdr local-table))))
(if subtable
(let ((record (assoc key-2 (cdr subtable))))
(if record
(cdr record)
false))
false)))
(define (insert! key-1 key-2 value)
(let ((subtable (assoc key-1 (cdr local-table))))
(if subtable
(let ((record (assoc key-2 (cdr subtable))))
(if record
(set-cdr! record value)
(set-cdr! subtable
(cons (cons key-2 value)
(cdr subtable)))))
(set-cdr! local-table
(cons (list key-1
(cons key-2 value))
(cdr local-table)))))
'ok)
(define (dispatch m)
(cond ((eq? m 'lookup-proc) lookup)
((eq? m 'insert-proc!) insert!)
(else (error "Unknown operation -- TABLE" m))))
dispatch))
使用 make-table,我们可以实现第 2.4.3 节中用于数据导向编程的 get 和 put 操作,如下所示:
(define operation-table (make-table))
(define get (operation-table 'lookup-proc))
(define put (operation-table 'insert-proc!))
Get 接受两个键作为参数,put 接受两个键和一个值作为参数。两个操作都访问同一个局部表,该表封装在调用 make-table 创建的对象内部。
练习 3.24. 在上述表格实现中,键使用 equal?(由 assoc 调用)测试相等性。这并非总是适当的测试。例如,我们可能有一个数值键的表格,其中我们需要的不一定是与查找数字的精确匹配,而只是某个容差范围内的数字。设计一个表格构造器 make-table,它接受一个 same-key? 过程作为参数,该过程将用于测试键的"相等性"。Make-table 应返回一个 dispatch 过程,可用于访问局部表的适当 lookup 和 insert! 过程。
练习 3.25. 推广一维和二维表格,说明如何实现一个表格,其中值存储在任意数量的键下,且不同的值可以存储在不同数量的键下。lookup 和 insert! 过程应接受一个用于访问表格的键列表作为输入。
练习 3.26. 要搜索上述实现的表格,需要扫描记录列表。这基本上是第 2.3.3 节的无序列表表示。对于大型表格,以不同的方式组织表格结构可能更高效。描述一种表格实现,其中(键,值)记录使用二叉树组织,假设键可以某种方式排序(例如,数字或字母顺序)。(比较第 2 章的练习 2.66。)
练习 3.27. 记忆化(也称为制表)是一种技术,它使过程能够在局部表中记录先前已计算过的值。这种技术可以对程序的性能产生巨大的影响。记忆化的过程维护一个表格,其中存储了先前调用的值,使用产生这些值的参数作为键。当记忆化的过程被要求计算一个值时,它首先检查表格中是否已存在该值,如果存在,就直接返回该值。否则,它按普通方式计算新值并将其存储到表格中。作为记忆化的一个例子,回顾第 1.2.2 节中计算斐波那契数的指数过程:
(define (fib n)
(cond ((= n 0) 0)
((= n 1) 1)
(else (+ (fib (- n 1))
(fib (- n 2))))))
同一过程的记忆化版本是:
(define memo-fib
(memoize (lambda (n)
(cond ((= n 0) 0)
((= n 1) 1)
(else (+ (memo-fib (- n 1))
(memo-fib (- n 2))))))))
其中记忆化器定义如下:
(define (memoize f)
(let ((table (make-table)))
(lambda (x)
(let ((previously-computed-result (lookup x table)))
(or previously-computed-result
(let ((result (f x)))
(insert! x result table)
result))))))
画出一个环境图来分析 (memo-fib 3) 的计算。解释为什么 memo-fib 计算第 n 个斐波那契数所需的步数与 n 成正比。如果我们只是简单地将 memo-fib 定义为 (memoize fib),该方案还能工作吗?
设计复杂的数字系统(如计算机)是一项重要的工程活动。数字系统是通过互连简单元件来构建的。尽管这些单个元件的行为很简单,但它们的网络可以具有非常复杂的行为。对所提出的电路设计进行计算机仿真是数字系统工程师使用的重要工具。在本节中,我们设计一个用于执行数字逻辑仿真的系统。这种系统代表了一类称为事件驱动仿真的程序,其中动作("事件")触发后续发生的进一步事件,这些事件又触发更多事件,以此类推。
我们对电路的计算模型将由对应于构建电路的基本组件的对象组成。有承载数字信号的导线。数字信号在任何时刻只能取两个可能值之一:0 和 1。还有各种类型的数字功能盒,它们将承载输入信号的导线连接到其他输出导线。这些功能盒产生从其输入信号计算得出的输出信号。输出信号会延迟一段时间,具体取决于功能盒的类型。例如,反相器是一个对其输入进行反相的基本功能盒。如果反相器的输入信号变为 0,那么一个反相器延迟后,反相器会将其输出信号变为 1。如果反相器的输入信号变为 1,那么一个反相器延迟后,反相器会将其输出信号变为 0。我们在图 3.24 中以符号形式画出了一个反相器。与门(也在图 3.24 中显示)是一个有两个输入和一个输出的基本功能盒。它将其输出信号驱动为输入的逻辑与值。也就是说,如果它的两个输入信号都变为 1,那么一个与门延迟时间后,与门会将其输出信号强制为 1;否则输出为 0。或门是一个类似的二输入基本功能盒,它将其输出信号驱动为输入的逻辑或值。也就是说,如果至少一个输入信号为 1,输出将变为 1;否则输出将变为 0。
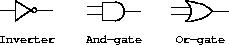
|
我们可以将基本功能连接在一起以构造更复杂的功能。为此,我们将一些功能盒的输出连接到其他功能盒的输入。例如,图 3.25 所示的半加器电路由一个或门、两个与门和一个反相器组成。它有两个输入信号 A 和 B,以及两个输出信号 S 和 C。当 A 和 B 中恰好有一个为 1 时,S 将变为 1;当 A 和 B 均为 1 时,C 将变为 1。从图中可以看出,由于涉及的延迟,输出可能在不同的时间产生。数字电路设计中的许多困难都源于这一事实。
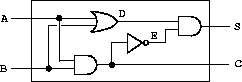
|
我们现在将构建一个程序来模拟我们希望研究的数字逻辑电路。该程序将构造对导线进行建模的计算对象,这些对象将"持有"信号。功能盒将通过强制信号之间正确关系的过程来建模。
我们仿真的一个基本元素是过程 make-wire,它构造导线。例如,我们可以如下构造六条导线:
(define a (make-wire))
(define b (make-wire))
(define c (make-wire))
(define d (make-wire))
(define e (make-wire))
(define s (make-wire))
我们通过调用构造某种功能盒的过程,将一个功能盒附加到一组导线上。构造器过程的参数是要连接到该盒的导线。例如,假设我们可以构造与门、或门和反相器,我们可以连接图 3.25 中所示的半加器:
(or-gate a b d)
ok
(and-gate a b c)
ok
(inverter c e)
ok
(and-gate d e s)
ok
更好的是,我们可以通过定义过程 half-adder 来显式命名此操作,该过程在给定要连接到半加器的四条外部导线时构造该电路:
(define (half-adder a b s c)
(let ((d (make-wire)) (e (make-wire)))
(or-gate a b d)
(and-gate a b c)
(inverter c e)
(and-gate d e s)
'ok))
做出这种定义的好处是,我们可以使用 half-adder 本身作为创建更复杂电路的构建块。例如,图 3.26 显示了一个由两个半加器和一个或门组成的全加器。26 我们可以如下构造全加器:
(define (full-adder a b c-in sum c-out)
(let ((s (make-wire))
(c1 (make-wire))
(c2 (make-wire)))
(half-adder b c-in s c1)
(half-adder a s sum c2)
(or-gate c1 c2 c-out)
'ok))
将 full-adder 定义为过程后,我们现在可以将其用作创建更复杂电路的构建块。(例如,参见练习 3.30。)
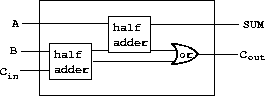
|
本质上,我们的仿真器为我们提供了构造电路语言的工具。如果我们采用在第 1.1 节中研究 Lisp 时所采用的关于语言的一般视角,我们可以说基本功能盒构成了语言的基本元素,将功能盒连接在一起提供了组合的手段,而将连线模式指定为过程则提供了抽象的手段。
基本功能盒实现了"驱动力",通过这种力,一条导线上信号的变化会影响其他导线上的信号。为了构建功能盒,我们对导线使用以下操作:
此外,我们将使用过程 after-delay,它接受一个时间延迟和一个要运行的过程,并在给定延迟后执行该过程。
使用这些过程,我们可以定义基本的数字逻辑功能。要通过反相器连接输入到输出,我们使用 add-action! 将输入导线关联到一个过程,每当输入导线上的信号值改变时运行该过程。该过程计算输入信号的 logical-not,然后在一个 inverter-delay 之后,将输出信号设置为这个新值:
(define (inverter input output)
(define (invert-input)
(let ((new-value (logical-not (get-signal input))))
(after-delay inverter-delay
(lambda ()
(set-signal! output new-value)))))
(add-action! input invert-input)
'ok)
(define (logical-not s)
(cond ((= s 0) 1)
((= s 1) 0)
(else (error "Invalid signal" s))))
与门稍微复杂一些。如果门的任一输入发生变化,就必须运行动作过程。它计算输入导线上信号值的 logical-and(使用类似于 logical-not 的过程),并安排在一个 and-gate-delay 后在输出导线上发生新值的变化。
(define (and-gate a1 a2 output)
(define (and-action-procedure)
(let ((new-value
(logical-and (get-signal a1) (get-signal a2))))
(after-delay and-gate-delay
(lambda ()
(set-signal! output new-value)))))
(add-action! a1 and-action-procedure)
(add-action! a2 and-action-procedure)
'ok)
练习 3.28. 定义一个或门作为基本功能盒。你的 or-gate 构造器应类似于 and-gate。
练习 3.29. 构造或门的另一种方法是将其作为复合数字逻辑器件,由与门和反相器构建而成。定义一个完成此功能的过程 or-gate。用 and-gate-delay 和 inverter-delay 表示的或门延迟时间是多少?
练习 3.30. 图 3.27 显示了一个由 n 个全加器串联而成的纹波进位加法器。这是用于相加两个 n 位二进制数的最简单的并行加法器形式。输入 A1、A2、A3、...、An 和 B1、B2、B3、...、Bn 是要相加的两个二进制数(每个 Ak 和 Bk 是 0 或 1)。该电路生成 S1、S2、S3、...、Sn(和的 n 个位)以及 C(相加的进位)。编写一个过程 ripple-carry-adder 来生成此电路。该过程应接受三个包含 n 条导线的列表作为参数——Ak、Bk 和 Sk——以及另一条导线 C。纹波进位加法器的主要缺点是需要等待进位信号传播。从 n 位纹波进位加法器获得完整输出所需的延迟是多少?(用与门、或门和反相器的延迟表示。)
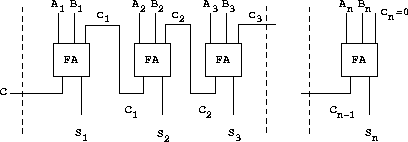
|
我们仿真中的导线将是一个具有两个局部状态变量的计算对象:一个 signal-value(初始取值为 0)和一个要在信号值改变时运行的 action-procedures 集合。我们使用消息传递风格实现导线,作为一组局部过程以及一个选择适当局部操作的 dispatch 过程,就像我们在第 3.1.1 节中对简单的银行账户对象所做的那样:
(define (make-wire)
(let ((signal-value 0) (action-procedures '()))
(define (set-my-signal! new-value)
(if (not (= signal-value new-value))
(begin (set! signal-value new-value)
(call-each action-procedures))
'done))
(define (accept-action-procedure! proc)
(set! action-procedures (cons proc action-procedures))
(proc))
(define (dispatch m)
(cond ((eq? m 'get-signal) signal-value)
((eq? m 'set-signal!) set-my-signal!)
((eq? m 'add-action!) accept-action-procedure!)
(else (error "Unknown operation -- WIRE" m))))
dispatch))
局部过程 set-my-signal! 测试新信号值是否改变了导线上的信号。如果改变了,它使用以下过程 call-each 运行每个动作过程,该过程调用无参数过程列表中的每一项:
(define (call-each procedures)
(if (null? procedures)
'done
(begin
((car procedures))
(call-each (cdr procedures)))))
局部过程 accept-action-procedure! 将给定的过程添加到要运行的过程列表中,然后立即运行新过程一次。(参见练习 3.31。)
按照指定的方式设置局部 dispatch 过程后,我们可以提供以下过程来访问导线上的局部操作:27
(define (get-signal wire)
(wire 'get-signal))
(define (set-signal! wire new-value)
((wire 'set-signal!) new-value))
(define (add-action! wire action-procedure)
((wire 'add-action!) action-procedure))
导线具有随时间变化的信号,并且可以逐步连接到设备,是可变对象的典型例子。我们已将它们建模为具有通过赋值修改的局部状态变量的过程。当创建新导线时,分配一组新的状态变量(通过 make-wire 中的 let 表达式),并构造和返回一个新的 dispatch 过程,捕获带有新状态变量的环境。
导线在连接到它们的不同设备之间共享。因此,与一个设备交互所做的更改将影响连接到该导线的所有其他设备。导线通过调用建立连接时提供给它的动作过程,将更改传达给其邻居。
完成仿真器唯一需要的是 after-delay。这里的想法是我们维护一个称为议程表的数据结构,其中包含待做事项的时间表。为议程表定义了以下操作:
我们使用的特定议程表由 the-agenda 表示。过程 after-delay 向 the-agenda 添加新元素:
(define (after-delay delay action)
(add-to-agenda! (+ delay (current-time the-agenda))
action
the-agenda))
仿真由过程 propagate 驱动,它对 the-agenda 进行操作,按顺序执行议程表上的每个过程。一般来说,随着仿真的运行,新项将被添加到议程表中,只要议程表上还有项,propagate 就会继续仿真:
(define (propagate)
(if (empty-agenda? the-agenda)
'done
(let ((first-item (first-agenda-item the-agenda)))
(first-item)
(remove-first-agenda-item! the-agenda)
(propagate))))
以下过程在导线上放置一个"探针",展示了仿真器的实际运行。探针告诉导线,每当其信号值改变时,它应打印新的信号值,连同当前时间和标识导线的名称:
(define (probe name wire)
(add-action! wire
(lambda ()
(newline)
(display name)
(display " ")
(display (current-time the-agenda))
(display " New-value = ")
(display (get-signal wire)))))
我们首先初始化议程表并指定基本功能盒的延迟:
(define the-agenda (make-agenda))
(define inverter-delay 2)
(define and-gate-delay 3)
(define or-gate-delay 5)
现在我们定义四条导线,在其中两条上放置探针:
(define input-1 (make-wire))
(define input-2 (make-wire))
(define sum (make-wire))
(define carry (make-wire))
(probe 'sum sum)
sum 0 New-value = 0
(probe 'carry carry)
carry 0 New-value = 0
接下来,我们将导线连接成半加器电路(如图 3.25 所示),将 input-1 上的信号设置为 1,并运行仿真:
(half-adder input-1 input-2 sum carry)
ok
(set-signal! input-1 1)
done
(propagate)
sum 8 New-value = 1
done
Sum 信号在时间 8 时变为 1。我们现在距离仿真开始有八个时间单位。此时,我们可以将 input-2 上的信号设置为 1,并让值传播:
(set-signal! input-2 1)
done
(propagate)
carry 11 New-value = 1
sum 16 New-value = 0
done
Carry 在时间 11 时变为 1,sum 在时间 16 时变为 0。
练习 3.31. 在 make-wire 中定义的内部过程 accept-action-procedure! 指定当一个新的动作过程被添加到导线时,该过程立即运行。解释为什么这种初始化是必要的。特别地,跟踪上面段落中的半加器示例,并说明如果我们将 accept-action-procedure! 定义为如下形式,系统的响应会有什么不同:
(define (accept-action-procedure! proc)
(set! action-procedures (cons proc action-procedures)))
最后,我们给出议程表数据结构的细节,它持有计划在未来执行的过程。
议程表 is made up of time segments. Each time segment is a pair consisting of a number (the time) 和 a queue (see exercise 3.32) that holds the procedures that are scheduled to be run during that time segment.
(define (make-time-segment time queue)
(cons time queue))
(define (segment-time s) (car s))
(define (segment-queue s) (cdr s))
我们将使用第 3.3.2 节中描述的队列操作来操作时间段队列。
议程表本身是一个时间段的一维表格。它与第 3.3.3 节中描述的表格不同之处在于,这些段将按时间递增的顺序排序。此外,我们将当前时间(即最后处理的动作的时间)存储在议程表的头部。新构造的议程表没有时间段,当前时间为 0:28
(define (make-agenda) (list 0))
(define (current-time agenda) (car agenda))
(define (set-current-time! agenda time)
(set-car! agenda time))
(define (segments agenda) (cdr agenda))
(define (set-segments! agenda segments)
(set-cdr! agenda segments))
(define (first-segment agenda) (car (segments agenda)))
(define (rest-segments agenda) (cdr (segments agenda)))
如果没有时间段,则议程表为空:
(define (empty-agenda? agenda)
(null? (segments agenda)))
要向议程表添加一个动作,我们首先检查议程表是否为空。如果是,我们为该动作创建一个时间段并将其安装到议程表中。否则,我们扫描议程表,检查每个段的时间。如果找到了我们约定时间对应的段,我们将该动作添加到关联的队列中。如果到达的时间晚于我们约定的时间,我们在议程表中该时间之前插入一个新的时间段。如果到达了议程表的末尾,我们必须在末尾创建一个新的时间段。
(define (add-to-agenda! time action agenda)
(define (belongs-before? segments)
(or (null? segments)
(< time (segment-time (car segments)))))
(define (make-new-time-segment time action)
(let ((q (make-queue)))
(insert-queue! q action)
(make-time-segment time q)))
(define (add-to-segments! segments)
(if (= (segment-time (car segments)) time)
(insert-queue! (segment-queue (car segments))
action)
(let ((rest (cdr segments)))
(if (belongs-before? rest)
(set-cdr!
segments
(cons (make-new-time-segment time action)
(cdr segments)))
(add-to-segments! rest)))))
(let ((segments (segments agenda)))
(if (belongs-before? segments)
(set-segments!
agenda
(cons (make-new-time-segment time action)
segments))
(add-to-segments! segments))))
从议程表移除第一项的过程删除第一个时间段中队列前端的项。如果这次删除使时间段为空,我们将其从段列表中移除:29
(define (remove-first-agenda-item! agenda)
(let ((q (segment-queue (first-segment agenda))))
(delete-queue! q)
(if (empty-queue? q)
(set-segments! agenda (rest-segments agenda)))))
第一个议程表项在第一个时间段的队列头部找到。每当我们提取一个项,我们也更新当前时间:30
(define (first-agenda-item agenda)
(if (empty-agenda? agenda)
(error "Agenda is empty -- FIRST-AGENDA-ITEM")
(let ((first-seg (first-segment agenda)))
(set-current-time! agenda (segment-time first-seg))
(front-queue (segment-queue first-seg)))))
练习 3.32. 在议程表的每个时间段中要运行的过程被保存在一个队列中。因此,每个段的过程按照它们被添加到议程表的顺序(先进先出)被调用。解释为什么必须使用这种顺序。特别地,跟踪一个其输入在同一时间段内从 0,1 变为 1,0 的与门的行为,并说明如果我们将一个段的过程存储在一个普通列表中,仅在列表前端添加和移除过程(后进先出),行为会有什么不同。
计算机程序传统上被组织为单向计算,对预先指定的参数执行操作以产生期望的输出。另一方面,我们经常用量之间的关系来建模系统。例如,一个机械结构的数学模型可能包含以下信息:金属杆的挠度 d 与杆上的力 F、杆的长度 L、横截面积 A 和弹性模量 E 通过以下方程相关联:
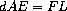
这样的方程不是单向的。给定任意四个量,我们可以用其计算第五个量。然而,将方程翻译成传统计算机语言会迫使我们选择其中一个量,用其他四个量来计算。因此,一个用于计算面积 A 的过程不能用于计算挠度 d,尽管 A 和 d 的计算源于同一个方程。31
在本节中,我们勾勒了一种语言的设计,这种语言使我们能够直接以关系本身进行工作。该语言的基本元素是基本约束,它们声明量之间存在的某些关系。例如,(adder a b c) 指定量 a、b 和 c 必须满足方程 a + b = c;(multiplier x y z) 表示约束 x · y = z;而 (constant 3.14 x) 说 x 的值必须是 3.14。
我们的语言提供了一种组合基本约束以表达更复杂关系的手段。我们通过构造约束网络来组合约束,其中约束由连接器连接。连接器是一个"持有"值的对象,该值可以参与一个或多个约束。例如,我们知道华氏温度和摄氏温度之间的关系是:
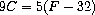
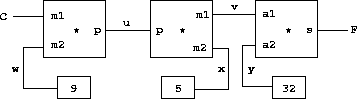
这样的约束可以被认为是一个网络,由基本的加法器、乘法器和常量约束组成(图 3.28)。在图中,我们在左侧看到一个带有三个端点的乘法器盒子,标记为 m1、m2 和 p。这些端点将乘法器连接到网络的其余部分,如下所示:m1 端点连接到一个将持有摄氏温度的连接器 C。m2 端点连接到一个连接器 w,该连接器也连接到一个持有 9 的常量盒。p 端点被乘法器盒约束为 m1 和 m2 的乘积,它连接到另一个乘法器盒的 p 端点,该乘法器盒的 m2 连接到一个常量 5,其 m1 连接到加法器中的一个项。
|
通过这样的网络进行计算的过程如下:当一个连接器被赋予一个值时(由用户或由它所链接的约束盒),它会唤醒所有关联的约束(除了刚刚唤醒它的那个约束),通知它们它有了一个值。然后每个被唤醒的约束盒轮询其连接器,看是否有足够的信息来确定某个连接器的值。如果有,该盒设置该连接器,然后该连接器又唤醒其所有关联的约束,以此类推。例如,在摄氏和华氏之间的转换中,w、x 和 y 立即被常量盒分别设置为 9、5 和 32。这些连接器唤醒乘法器和加法器,它们确定没有足够的信息继续处理。如果用户(或网络的其它部分)将 C 设置为一个值(比如 25),最左边的乘法器将被唤醒,它将 u 设置为 25 · 9 = 225。然后 u 唤醒第二个乘法器,它将 v 设置为 45,v 唤醒加法器,它将 F 设置为 77。
要使用约束系统执行上述温度计算,我们首先通过调用构造器 make-connector 创建两个连接器 C 和 F,并在适当的网络中链接 C 和 F:
(define C (make-connector))
(define F (make-connector))
(celsius-fahrenheit-converter C F)
ok
创建网络的过程定义如下:
(define (celsius-fahrenheit-converter c f)
(let ((u (make-connector))
(v (make-connector))
(w (make-connector))
(x (make-connector))
(y (make-connector)))
(multiplier c w u)
(multiplier v x u)
(adder v y f)
(constant 9 w)
(constant 5 x)
(constant 32 y)
'ok))
这个过程创建了内部连接器 u、v、w、x 和 y,并使用基本约束构造器 adder、multiplier 和 constant 将它们如图 3.28 所示连接起来。正如在第 3.3.4 节的数字电路仿真器中一样,将基本元素的这些组合表示为过程,自动为我们的语言提供了复合对象的抽象手段。
要观察网络的实际运行,我们可以在连接器 C 和 F 上放置探针,使用类似于第 3.3.4 节中用于监视导线的 probe 过程。在连接器上放置探针将导致每当该连接器被赋予一个值时打印一条消息:
(probe "Celsius temp" C)
(probe "Fahrenheit temp" F)
接下来我们将 C 的值设置为 25。(Set-value! 的第三个参数告诉 C 这个指令来自 user。)
(set-value! C 25 'user)
Probe: Celsius temp = 25
Probe: Fahrenheit temp = 77
done
C 上的探针被唤醒并报告该值。C 也如上所述通过网络传播其值。这将 F 设置为 77,并由 F 上的探针报告。
现在我们可以尝试将 F 设置为一个新值,比如 212:
(set-value! F 212 'user)
Error! Contradiction (77 212)
连接器抱怨它感知到了一个矛盾:它的值是 77,但有人试图将其设置为 212。如果我们真的想用新值重用该网络,我们可以告诉 C 忘记它的旧值:
(forget-value! C 'user)
Probe: Celsius temp = ?
Probe: Fahrenheit temp = ?
done
C 发现最初设置其值的 user 正在撤消该值,因此 C 同意丢弃其值,如探针所示,并将此事实通知网络的其余部分。此信息最终传播到 F,F 现在发现它没有理由继续相信自己的值是 77。因此,F 也放弃其值,如探针所示。
现在 F 没有值了,我们可以自由地将其设置为 212:
(set-value! F 212 'user)
Probe: Fahrenheit temp = 212
Probe: Celsius temp = 100
done
这个新值通过网络传播后,迫使 C 具有值 100,这由 C 上的探针记录。注意,同一个网络被用于根据 F 计算 C 和根据 C 计算 F。这种计算的非方向性是基于约束的系统的显著特征。
约束系统通过具有局部状态的过程式对象来实现,方式与第 3.3.4 节的数字电路仿真器非常相似。尽管约束系统的基本对象有些复杂,但整体系统更简单,因为无需关心议程表和逻辑延迟。
连接器通过过程 inform-about-value(告知给定的约束该连接器有值)和 inform-about-no-value(告知约束该连接器已失去其值)与约束进行通信。
Adder 在被加数连接器 a1 和 a2 与和连接器 sum 之间构造一个加法器约束。加法器被实现为具有局部状态的过程(下面的过程 me):
(define (adder a1 a2 sum)
(define (process-new-value)
(cond ((and (has-value? a1) (has-value? a2))
(set-value! sum
(+ (get-value a1) (get-value a2))
me))
((and (has-value? a1) (has-value? sum))
(set-value! a2
(- (get-value sum) (get-value a1))
me))
((and (has-value? a2) (has-value? sum))
(set-value! a1
(- (get-value sum) (get-value a2))
me))))
(define (process-forget-value)
(forget-value! sum me)
(forget-value! a1 me)
(forget-value! a2 me)
(process-new-value))
(define (me request)
(cond ((eq? request 'I-have-a-value)
(process-new-value))
((eq? request 'I-lost-my-value)
(process-forget-value))
(else
(error "Unknown request -- ADDER" request))))
(connect a1 me)
(connect a2 me)
(connect sum me)
me)
Adder 将新的加法器连接到指定的连接器并将其作为值返回。表示加法器的过程 me 充当到局部过程的分发。以下"语法接口"(参见第 3.3.4 节的脚注 27)与分发一起使用:
(define (inform-about-value constraint)
(constraint 'I-have-a-value))
(define (inform-about-no-value constraint)
(constraint 'I-lost-my-value))
当加法器被告知其某个连接器有值时,会调用加法器的局部过程 process-new-value。加法器首先检查 a1 和 a2 是否都有值。如果是,它告诉 sum 将其值设置为两个加数的和。Set-value! 的 informant 参数是 me,即加法器对象本身。如果 a1 和 a2 不都有值,则加法器检查 a1 和 sum 是否可能有值。如果是,它将 a2 设置为这两者的差。最后,如果 a2 和 sum 有值,这为加法器提供了足够的信息来设置 a1。如果加法器被告知其某个连接器丢失了值,它请求其所有连接器现在都丢失它们的值。(只有那些由该加法器设置的值实际上会丢失。)然后它运行 process-new-value。这最后一步的原因是,一个或多个连接器可能仍然有值(也就是说,连接器可能有一个最初不是由加法器设置的值),这些值可能需要通过加法器传播回去。
乘法器与加法器非常相似。如果其中一个因子为 0,即使另一个因子未知,它也会将其 product 设置为 0。
(define (multiplier m1 m2 product)
(define (process-new-value)
(cond ((or (and (has-value? m1) (= (get-value m1) 0))
(and (has-value? m2) (= (get-value m2) 0)))
(set-value! product 0 me))
((and (has-value? m1) (has-value? m2))
(set-value! product
(* (get-value m1) (get-value m2))
me))
((and (has-value? product) (has-value? m1))
(set-value! m2
(/ (get-value product) (get-value m1))
me))
((and (has-value? product) (has-value? m2))
(set-value! m1
(/ (get-value product) (get-value m2))
me))))
(define (process-forget-value)
(forget-value! product me)
(forget-value! m1 me)
(forget-value! m2 me)
(process-new-value))
(define (me request)
(cond ((eq? request 'I-have-a-value)
(process-new-value))
((eq? request 'I-lost-my-value)
(process-forget-value))
(else
(error "Unknown request -- MULTIPLIER" request))))
(connect m1 me)
(connect m2 me)
(connect product me)
me)
Constant 构造器简单地设置指定连接器的值。发送到常量盒的任何 I-have-a-value 或 I-lost-my-value 消息都会产生错误。
(define (constant value connector)
(define (me request)
(error "Unknown request -- CONSTANT" request))
(connect connector me)
(set-value! connector value me)
me)
最后,探针打印关于设置或取消设置指定连接器的消息:
(define (probe name connector)
(define (print-probe value)
(newline)
(display "Probe: ")
(display name)
(display " = ")
(display value))
(define (process-new-value)
(print-probe (get-value connector)))
(define (process-forget-value)
(print-probe "?"))
(define (me request)
(cond ((eq? request 'I-have-a-value)
(process-new-value))
((eq? request 'I-lost-my-value)
(process-forget-value))
(else
(error "Unknown request -- PROBE" request))))
(connect connector me)
me)
连接器被表示为一个具有局部状态变量的过程式对象:value(连接器的当前值)、informant(设置连接器值的对象)和 constraints(连接器参与的约束列表)。
(define (make-connector)
(let ((value false) (informant false) (constraints '()))
(define (set-my-value newval setter)
(cond ((not (has-value? me))
(set! value newval)
(set! informant setter)
(for-each-except setter
inform-about-value
constraints))
((not (= value newval))
(error "Contradiction" (list value newval)))
(else 'ignored)))
(define (forget-my-value retractor)
(if (eq? retractor informant)
(begin (set! informant false)
(for-each-except retractor
inform-about-no-value
constraints))
'ignored))
(define (connect new-constraint)
(if (not (memq new-constraint constraints))
(set! constraints
(cons new-constraint constraints)))
(if (has-value? me)
(inform-about-value new-constraint))
'done)
(define (me request)
(cond ((eq? request 'has-value?)
(if informant true false))
((eq? request 'value) value)
((eq? request 'set-value!) set-my-value)
((eq? request 'forget) forget-my-value)
((eq? request 'connect) connect)
(else (error "Unknown operation -- CONNECTOR"
request))))
me))
当有请求设置连接器的值时,会调用连接器的局部过程 set-my-value。如果连接器当前没有值,它将设置其值,并将请求设置该值的约束记住为 informant。32 然后连接器将通知其所有参与的约束,除了请求设置值的那个。这是使用以下迭代器完成的,该迭代器将指定的过程应用于列表中除给定项之外的所有项:
(define (for-each-except exception procedure list)
(define (loop items)
(cond ((null? items) 'done)
((eq? (car items) exception) (loop (cdr items)))
(else (procedure (car items))
(loop (cdr items)))))
(loop list))
如果要求连接器忘记其值,它运行局部过程 forget-my-value,该过程首先检查以确保请求来自最初设置该值的同一对象。如果是,连接器通知其关联的约束关于值的丢失。
局部过程 connect 将指定的新约束添加到约束列表中(如果它尚未在该列表中)。然后,如果连接器有值,它将此事实告知新约束。
连接器的过程 me 充当到其他内部过程的分发,同时也将连接器表示为一个对象。以下过程为分发提供语法接口:
(define (has-value? connector)
(connector 'has-value?))
(define (get-value connector)
(connector 'value))
(define (set-value! connector new-value informant)
((connector 'set-value!) new-value informant))
(define (forget-value! connector retractor)
((connector 'forget) retractor))
(define (connect connector new-constraint)
((connector 'connect) new-constraint))
练习 3.33. 使用基本的乘法器、加法器和常量约束,定义一个过程 averager,它接受三个连接器 a、b 和 c 作为输入,并建立约束 c 的值是 a 和 b 的值的平均值。
练习 3.34. Louis Reasoner 想要构建一个平方器,一个具有两个端点的约束设备,使得第二个端点上连接器 b 的值始终是第一个端点上 a 的值的平方。他提出了以下由乘法器制成的简单设备:
(define (squarer a b)
(multiplier a a b))
这个想法存在一个严重缺陷。请解释。
练习 3.35. Ben Bitdiddle 告诉 Louis,避免练习 3.34 中问题的一种方法是将平方器定义为一个新的基本约束。请填写 Ben 为实现这样一个约束的过程大纲中缺失的部分:
(define (squarer a b)
(define (process-new-value)
(if (has-value? b)
(if (< (get-value b) 0)
(error "square less than 0 -- SQUARER" (get-value b))
<alternative1>)
<alternative2>))
(define (process-forget-value) <body1>)
(define (me request) <body2>)
<rest of definition>
me)
(define a (make-connector))
(define b (make-connector))
(set-value! a 10 'user)
在求值 set-value! 的过程中,会求值连接器局部过程中的以下表达式:
(for-each-except setter inform-about-value constraints)
画出一个环境图,显示上述表达式被求值时的环境。
练习 3.37. Celsius-fahrenheit-converter 过程与更加面向表达式的定义风格相比显得繁琐,例如
(define (celsius-fahrenheit-converter x)
(c+ (c* (c/ (cv 9) (cv 5))
x)
(cv 32)))
(define C (make-connector))
(define F (celsius-fahrenheit-converter C))
这里 c+、c* 等是算术运算的"约束"版本。例如,c+ 接受两个连接器作为参数,并返回一个通过加法器约束与这些连接器相关联的连接器:
(define (c+ x y)
(let ((z (make-connector)))
(adder x y z)
z))
定义类似的过程 c-、c*、c/ 和 cv(常量值),使我们能够像上面的转换器示例一样定义复合约束。33
16 Set-car! 和 set-cdr! 返回依赖于实现的值。与 set! 一样,应仅为了其效果而使用它们。
17 我们从中看到,列表上的修改操作可以创建不属于任何可访问结构的"垃圾"。我们将在第 5.3.2 节中看到,Lisp 内存管理系统包括一个垃圾收集器,它识别并回收不需要的对偶所使用的内存空间。
18 Get-new-pair 是必须作为 Lisp 实现所需的内存管理的一部分来实现的操作之一。我们将在第 5.3.1 节中讨论这个问题。
19 这两个对偶是不同的,因为每次调用 cons 都会返回一个新对偶。符号是共享的;在 Scheme 中,任何给定的名称都有唯一的符号。由于 Scheme 不提供修改符号的方法,这种共享是检测不到的。还要注意,正是这种共享使我们能够使用 eq? 来比较符号,它只是检查指针的相等性。
20 处理可变数据对象共享的微妙之处反映了第 3.1.3 节中提出的"同一性"和"变化"的基本问题。我们在那里提到,允许在我们的语言中引入变化要求一个复合对象必须具有与其组成部分不同的"标识"。在 Lisp 中,我们将这个"标识"视为由 eq? 测试的性质,即由指针相等性测试。由于在大多数 Lisp 实现中,指针本质上是一个内存地址,我们通过规定数据对象"本身"是存储在计算机中某个特定内存位置集合中的信息来"解决"定义对象标识的问题。这对于简单的 Lisp 程序来说足够了,但很难作为解决计算模型中"同一性"问题的通用方法。
21 另一方面,从实现的角度来看,赋值要求我们修改环境,而环境本身就是一个可变的数据结构。因此,赋值和修改是等价的:两者可以相互实现。
22 如果第一个项是队列中的最后一个项,删除后前端指针将是空列表,这将标记队列为空;我们无需担心更新尾部指针,它仍然指向已删除的项,因为 empty-queue? 只查看前端指针。
23 注意不要让解释器尝试打印包含环的结构。(参见练习 3.13。)
24 因为 assoc 使用 equal?,它可以识别符号、数字或列表结构的键。
25 因此,第一个骨架对偶是代表表格"本身"的对象;也就是说,指向表格的指针就是指向这对偶的指针。同一个骨架对偶总是作为表格的起始。如果我们不这样做,insert! 在添加新记录时就必须返回表格起始的新值。
26 全加器是用于相加两个二进制数的基本电路元件。这里 A 和 B 是要相加的两个数中对应位置上的位,Cin 是右边一位相加的进位位。该电路生成 SUM(对应位置的和位)和 Cout(要向左传播的进位位)。
27 这些过程只是语法糖,允许我们使用普通的过程语法来访问对象的局部过程。令人瞩目的是,我们可以以如此简单的方式互换"过程"和"数据"的角色。例如,如果我们写 (wire 'get-signal),我们将 wire 视为一个以消息 get-signal 作为输入来调用的过程。或者,写 (get-signal wire) 鼓励我们将 wire 视为过程 get-signal 的输入数据对象。事实是,在一种我们可以将过程作为对象处理的语言中,"过程"和"数据"之间没有根本的区别,我们可以选择我们的语法糖,以便以我们选择的任何风格进行编程。
28 议程表是一个带头列表,类似于第 3.3.3 节中的表格,但由于列表以时间开头,我们不需要额外的虚拟头部(如表格中使用的 *table* 符号)。
29 注意,此过程中的 if 表达式没有 <alternative> 表达式。这种"单臂 if 语句"用于决定是否做某事,而不是在两个表达式之间进行选择。如果谓词为假且没有 <alternative>,if 表达式返回一个未指定的值。
30 这样,当前时间将始终是最近处理的动作的时间。将此时间存储在议程表的头部可确保即使相关联的时间段已被删除,它仍然可用。
31 约束传播首次出现在 Ivan Sutherland(1963)极具前瞻性的 SKETCHPAD 系统中。一个基于 Smalltalk 语言的优美的约束传播系统由 Alan Borning(1977)在 Xerox Palo Alto 研究中心开发。Sussman、Stallman 和 Steele 将约束传播应用于电路分析(Sussman 和 Stallman 1975;Sussman 和 Steele 1980)。TK!Solver(Konopasek 和 Jayaraman 1984)是一个基于约束的广泛建模环境。
32 Setter 可能不是一个约束。在我们的温度示例中,我们使用 user 作为 setter。
33 面向表达式的格式很方便,因为它避免了在计算中命名中间表达式的需要。我们原始的约束语言表述在许多语言处理复合数据操作的方式上是繁琐的。例如,如果我们想要计算乘积 (a + b) · (c + d),其中变量表示向量,我们可以使用"命令式风格",使用设置指定向量参数的值但不返回向量作为值的过程:
(v-sum a b temp1)
(v-sum c d temp2)
(v-prod temp1 temp2 answer)
或者,我们可以使用返回向量作为值的过程来处理表达式,从而避免显式提及 temp1 和 temp2:
(define answer (v-prod (v-sum a b) (v-sum c d)))
由于 Lisp 允许我们将复合对象作为过程的值返回,我们可以将命令式风格的约束语言转换为面向表达式的风格,如本练习所示。在处理复合对象方面能力有限的语言中,例如 Algol、Basic 和 Pascal(除非显式使用 Pascal 指针变量),在操作复合对象时通常只能使用命令式风格。考虑到面向表达式格式的优势,人们可能会问是否有任何理由像我们在本节中所做的那样以命令式风格实现该系统。一个原因是,非面向表达式的约束语言提供了对约束对象(例如 adder 过程的值)以及连接器对象的句柄。如果我们希望使用与约束直接通信的新操作来扩展系统,而不仅仅是间接通过对连接器的操作,这将非常有用。虽然基于命令式实现来构建面向表达式的风格很容易,但反过来做却非常困难。