|
为了设计一台寄存器计算机,我们必须设计其数据路径(寄存器和操作)以及对这些操作进行排序的控制器。为了说明简单寄存器计算机的设计,让我们考察欧几里得算法,该算法用于计算两个整数的最大公约数(GCD)。正如我们在第 1.2.5 节中看到的,欧几里得算法可以通过迭代过程来执行,由以下过程指定:
(define (gcd a b)
(if (= b 0)
a
(gcd b (remainder a b))))
执行该算法的机器必须跟踪两个数 a 和 b,因此我们假设这些数存储在两个同名的寄存器中。所需的基本操作是测试寄存器 b 的内容是否为零,以及计算寄存器 a 的内容除以寄存器 b 的内容的余数。求余运算是一个复杂的过程,但暂时假设我们有一个计算余数的基本设备。在 GCD 算法的每个循环中,寄存器 a 的内容必须被替换为寄存器 b 的内容,而 b 的内容必须被替换为 a 的旧内容除以 b 的旧内容的余数。如果这些替换能同时完成会很方便,但在我们的寄存器计算机模型中,我们假设每一步只能给一个寄存器赋予新值。为了实现这些替换,我们的机器将使用第三个"临时"寄存器,我们称之为 t。(首先将余数放入 t,然后将 b 的内容放入 a,最后将存储在 t 中的余数放入 b。)
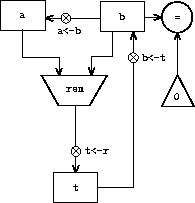
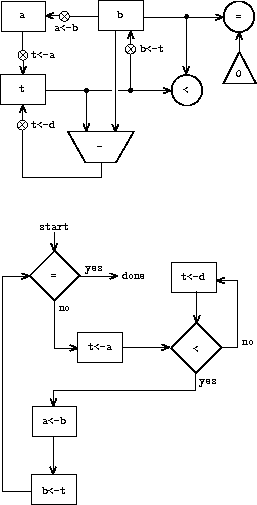
我们可以通过图 5.1 所示的数据路径图来说明该机器所需的寄存器和操作。在该图中,寄存器(a、b 和 t)用矩形表示。每种为寄存器赋值的方式由一条箭头表示,箭头头部后面有一个 X,从数据源指向寄存器。我们可以将 X 视为一个按钮,按下后允许源处的值"流入"指定的寄存器。每个按钮旁边的标签是我们用来指代该按钮的名称。这些名称是任意的,可以选择具有助记意义的名称(例如,a<-b 表示按下将寄存器 b 的内容赋给寄存器 a 的按钮)。寄存器的数据源可以是另一个寄存器(如 a<-b 赋值)、一个运算结果(如 t<-r 赋值)或一个常量(一个不能改变的内置值,在数据路径图中由包含该常量的三角形表示)。
从常量和寄存器内容计算值的运算在数据路径图中由包含运算名称的梯形表示。例如,图 5.1 中标有 rem 的方框表示计算其所连接的寄存器 a 和 b 的内容的余数的运算。箭头(不带按钮)从输入寄存器和常量指向方框,箭头将运算的输出值连接到寄存器。测试由一个包含测试名称的圆圈表示。例如,我们的 GCD 计算机有一个测试寄存器 b 的内容是否为零的运算。测试也有来自其输入寄存器和常量的箭头,但没有输出箭头;其值由控制器使用,而非数据路径。总的来说,数据路径图展示了机器所需的寄存器、运算以及它们之间的连接方式。如果我们将箭头视为导线,将 X 按钮视为开关,那么数据路径图就非常类似于可以用电子元件构建的机器的接线图。
|
|
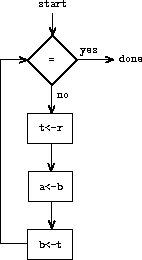
为了使数据路径实际计算 GCD,必须按正确顺序按下按钮。我们将用控制器图来描述这个顺序,如图 5.2 所示。控制器图的元素表明了数据路径组件应如何操作。控制器图中的矩形框标识了要按下的数据路径按钮,箭头描述了从一个步骤到下一个步骤的顺序。图中的菱形表示一个决策。根据菱形中标识的数据路径测试的值,将遵循两条顺序箭头之一。我们可以用物理类比来理解控制器:将图想象为一个弹珠在其中滚动的迷宫。当弹珠滚入一个方框时,它会按下该方框命名的数据路径按钮。当弹珠滚入决策节点(例如 b = 0 的测试)时,它根据指示测试的结果沿确定的路径离开该节点。数据路径和控制器一起完整地描述了一台计算 GCD 的计算机。我们在标记为 start 的位置启动控制器(滚动的弹珠),在此之前将数字放入寄存器 a 和 b 中。当控制器到达 done 时,我们将在寄存器 a 中找到 GCD 的值。
|
练习 5.1. 设计一台寄存器计算机,使用以下过程指定的迭代算法计算阶乘。画出该计算机的数据路径图和控制器图。
(define (factorial n)
(define (iter product counter)
(if (> counter n)
product
(iter (* counter product)
(+ counter 1))))
(iter 1 1))
数据路径图和控制器图足以表示 GCD 这样的简单计算机,但它们对于描述 Lisp 解释器这样的大型计算机来说过于笨重。为了能够处理复杂的计算机,我们将创造一种语言,以文本形式呈现数据路径图和控制器图给出的所有信息。我们将从直接反映这些图的一种记法开始。
我们通过描述寄存器和操作来定义机器的数据路径。为了描述一个寄存器,我们为其指定一个名称,并指明控制其赋值的按钮。我们为每个按钮指定一个名称,并说明在该按钮控制下进入寄存器的数据源。(数据源可以是寄存器、常量或一个运算。)为了描述一个运算,我们为其指定一个名称,并说明其输入(寄存器或常量)。
我们将机器的控制器定义为一系列指令以及标识序列中入口点的标签。指令可以是以下几种之一:
机器从控制器指令序列的起始处开始执行,当执行到达序列末尾时停止。除非分支改变了控制流,否则指令按列出的顺序依次执行。
(data-paths
|
图 5.3 以这种方式展示了 GCD 计算机的规格说明。这个例子仅仅暗示了这些描述的一般性,因为 GCD 计算机是一个非常简单的例子:每个寄存器只有一个按钮,每个按钮和测试在控制器中只使用一次。
遗憾的是,这样的描述难以阅读。为了理解控制器指令,我们必须不断地回顾按钮名称和操作名称的定义,而要理解按钮的功能,我们又可能需要查阅操作名称的定义。因此,我们将改造我们的记法,将数据路径描述和控制器描述中的信息合并到一起,使我们能够一目了然。
为了获得这种形式的描述,我们将用其行为定义来替换任意的按钮和操作名称。也就是说,我们不再(在控制器中)说"按下按钮 t<-r",然后另外(在数据路径中)说"按钮 t<-r 将 rem 运算的值赋给寄存器 t"以及"rem 运算的输入是寄存器 a 和 b 的内容",而是(在控制器中)说"按下将寄存器 a 和 b 的内容上的 rem 运算的值赋给寄存器 t 的按钮"。类似地,我们不再(在控制器中)说"执行 = 测试",然后另外(在数据路径中)说"= 测试对寄存器 b 的内容和常量 0 进行操作",而是说"对寄存器 b 的内容和常量 0 执行 = 测试"。我们将省略数据路径描述,只保留控制器序列。因此,GCD 计算机被描述如下:
(controller
test-b
(test (op =) (reg b) (const 0))
(branch (label gcd-done))
(assign t (op rem) (reg a) (reg b))
(assign a (reg b))
(assign b (reg t))
(goto (label test-b))
gcd-done)
这种描述形式比图 5.3 中所示的形式更易读,但它也有缺点:
尽管有这些缺点,我们仍将在本章中使用这种寄存器计算机语言,因为我们更关心理解控制器,而不是理解数据路径中的元素和连接。然而,我们应该牢记,数据路径设计在设计真实机器时是至关重要的。
练习 5.2. 使用寄存器计算机语言描述练习 5.1 中的迭代阶乘计算机。
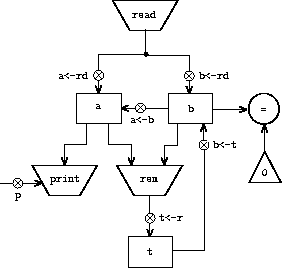
让我们修改 GCD 计算机,使得我们可以输入想要计算 GCD 的数字,并在终端上打印出答案。我们不会讨论如何制造一台能够读取和打印的机器,而是假设(就像我们在 Scheme 中使用 read 和 display 一样)它们可以作为基本操作使用。1
Read 和之前使用的运算一样,能够产生一个可以存储在寄存器中的值。但 read 不从任何寄存器获取输入;它的值依赖于我们正在设计的机器部件之外发生的事情。我们允许机器中的运算具有这样的行为,因此我们将像对待任何其他计算值的运算一样,绘制和使用 read。
另一方面,Print 与我们之前使用的运算有一个根本区别:它不产生要存储在寄存器中的输出值。虽然它有作用,但这种作用不是作用于我们正在设计的机器部件。我们将这种运算称为动作。在数据路径图中,我们表示一个动作的方式与表示一个计算值的运算相同——用一个包含动作名称的梯形。箭头从任何输入(寄存器或常量)指向动作方框。我们还将一个按钮与动作关联起来。按下按钮使动作发生。为了让控制器按下动作按钮,我们使用一种称为 perform 的新指令。因此,在控制器序列中,打印寄存器 a 的内容的动作由以下指令表示
(perform (op print) (reg a))
图 5.4 展示了新的 GCD 计算机的数据路径和控制器。我们没有让机器在打印答案后停止,而是让它重新开始,从而重复地读取一对数字,计算它们的 GCD,并打印结果。这种结构类似于我们在第 4 章的解释器中所使用的驱动循环。
(controller
|
我们经常会在机器中定义实际上非常复杂的"基本"操作。例如,在第 5.4 节和第 5.5 节中,我们将把 Scheme 的环境操作视为基本操作。这种抽象很有价值,因为它允许我们忽略机器某些部分的细节,从而集中精力于设计中的其他方面。然而,我们将大量复杂性掩盖起来的事实并不意味着机器设计是不现实的。我们总是可以用更简单的基本操作来替换这些复杂的"基本操作"。
考虑 GCD 计算机。该机器有一条指令,计算寄存器 a 和 b 的内容的余数并将结果赋给寄存器 t。如果我们想在不使用基本余数运算的情况下构造 GCD 计算机,就必须说明如何用更简单的运算(如减法)来计算余数。实际上,我们可以编写一个 Scheme 过程,通过这种方式求余数:
(define (remainder n d)
(if (< n d)
n
(remainder (- n d) d)))
因此,我们可以用減法运算和比较测试来替换 GCD 计算机数据路径中的余数运算。图 5.5 展示了扩展后机器的数据路径和控制器。指令
|
(assign t (op rem) (reg a) (reg b))
在 GCD 控制器定义中被替换为包含一个循环的指令序列,如图 5.6 所示。
(controller
|
练习 5.3. 设计一台使用牛顿法计算平方根的计算机,如第 1.1.7 节所述:
(define (sqrt x)
(define (good-enough? guess)
(< (abs (- (square guess) x)) 0.001))
(define (improve guess)
(average guess (/ x guess)))
(define (sqrt-iter guess)
(if (good-enough? guess)
guess
(sqrt-iter (improve guess))))
(sqrt-iter 1.0))
首先假设 good-enough? 和 improve 操作作为基本操作可用。然后说明如何用算术运算来展开这些操作。通过绘制数据路径图和用寄存器计算机语言编写控制器定义,描述每个版本的 sqrt 计算机设计。
在设计一台执行计算的计算机时,我们通常更希望让计算的不同部分共享组件,而不是复制组件。考虑一台包含两个 GCD 计算的计算机——一个计算寄存器 a 和 b 的内容的 GCD,另一个计算寄存器 c 和 d 的内容的 GCD。我们可能首先假设有一个基本的 gcd 操作,然后将两个 gcd 实例展开为更基本的操作。图 5.7 展示了结果计算机数据路径中仅 GCD 部分的片段,没有显示它们如何连接到计算机的其余部分。该图还展示了计算机控制器序列的相应部分。
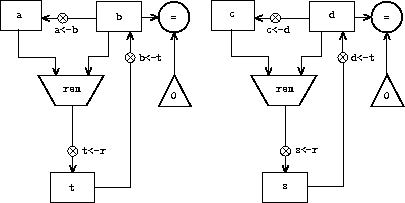
gcd-1
|
这台计算机有两个余数运算方框和两个测试相等的方框。如果被复制的组件很复杂(如余数方框),这将不是一种经济的构建方式。我们可以通过在两处 GCD 计算中使用相同的组件来避免复制数据路径组件,前提是这样做不会影响更大计算机的其余计算。如果在控制器到达 gcd-2 时寄存器 a 和 b 中的值不再需要(或者这些值可以被移到其他寄存器中安全保存),我们可以修改计算机,使其在计算第二个 GCD 时也使用寄存器 a 和 b,而不是寄存器 c 和 d。如果这样做,我们将得到图 5.8 所示的控制器序列。
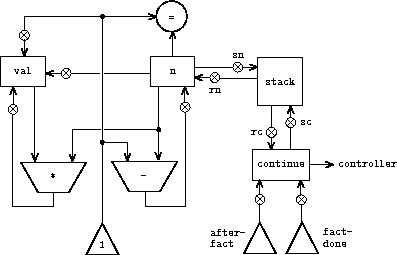
我们已经移除了重复的数据路径组件(因此数据路径再次如图 5.1 所示),但控制器现在有两个仅在入口点标签上有所不同的 GCD 序列。更好的做法是,用跳转到单个序列(一个 gcd 子程序)来替换这两个序列,在该序列末尾再跳转回主指令序列中的正确位置。我们可以这样实现:在跳转到 gcd 之前,将一个区分值(如 0 或 1)放入一个特殊的 continue 寄存器。在 gcd 子程序的末尾,根据 continue 寄存器的值,我们将返回到 after-gcd-1 或 after-gcd-2。图 5.9 展示了结果控制器序列的相关部分,其中只包含一份 gcd 指令的副本。
gcd-1
|
gcd
|
gcd
|
这是处理小问题的合理方法,但如果控制器序列中有许多 GCD 计算实例,就会很笨拙。为了决定在 gcd 子程序之后从何处继续执行,我们需要在所有使用 gcd 的地方设置数据路径中的测试和控制器中的分支指令。一种更强大的实现子程序的方法是让 continue 寄存器持有控制器序列中一个入口点的标签,子程序结束后执行应从该入口点继续。实现这一策略需要在寄存器计算机的数据路径和控制器之间建立一种新型连接:必须有一种方法,将一个控制器序列中的标签赋给一个寄存器,使得该值可以从寄存器中取出,并用于在指定的入口点继续执行。
为了反映这种能力,我们将扩展寄存器计算机语言的 assign 指令,允许将一个控制器序列中的标签(作为一种特殊的常量)赋给寄存器。我们还将扩展 goto 指令,允许执行在由寄存器内容描述的入口点处继续,而不仅仅是在由常量标签描述的入口点处继续。使用这些新构造,我们可以让 gcd 子程序以一个跳转到存储在 continue 寄存器中的位置来结束。这导致了图 5.10 所示的控制器序列。
一台有多个子程序的计算机可以使用多个续延寄存器(例如 gcd-continue、factorial-continue),或者我们可以让所有子程序共享一个 continue 寄存器。共享更经济,但当一个子程序(sub1)调用另一个子程序(sub2)时,我们必须小心。除非 sub1 在为调用 sub2 设置 continue 之前将 continue 的内容保存在其他寄存器中,否则 sub1 在完成时将不知道返回何处。下一节中开发的用于处理递归的机制也为这种嵌套子程序调用问题提供了更好的解决方案。
利用到目前为止说明的思想,我们可以通过指定一台寄存器计算机来实现任何迭代过程,该计算机有一个对应于过程的每个状态变量的寄存器。机器重复执行一个控制器循环,改变寄存器的内容,直到满足某个终止条件。在控制器序列的每个时刻,机器的状态(表示迭代过程的状态)完全由寄存器的内容(状态变量的值)决定。
然而,实现递归过程需要一个额外的机制。考虑以下计算阶乘的递归方法,我们在第 1.2.1 节中首次讨论过:
(define (factorial n)
(if (= n 1)
1
(* (factorial (- n 1)) n)))
从该过程可以看出,计算 n! 需要计算 (n - 1)!。我们的 GCD 计算机,按照以下过程建模,
(define (gcd a b)
(if (= b 0)
a
(gcd b (remainder a b))))
同样也需要计算另一个 GCD。但是 gcd 过程和 factorial 过程之间有一个重要区别:前者将原始计算规约为一个新的 GCD 计算,而后者需要将另一个阶乘计算作为一个子问题。在 GCD 中,新的 GCD 计算的结果就是原始问题的答案。为了计算下一个 GCD,我们只需将新的参数放入 GCD 计算机的输入寄存器,并通过执行相同的控制器序列来重用机器的数据路径。当机器完成最后一个 GCD 问题的求解时,它就完成了整个计算。
对于阶乘(或任何递归过程),新的阶乘子问题的答案并不是原始问题的答案。得到的 (n - 1)! 的值必须乘以 n 才能得到最终答案。如果我们试图模仿 GCD 的设计,通过递减 n 寄存器并重新运行阶乘机器来解决阶乘子问题,我们将不再有可用的旧 n 值来乘以结果。因此,我们需要第二台阶乘机器来处理子问题。而这第二台阶乘计算本身又有一个阶乘子问题,需要第三台阶乘机器,依此类推。由于每台阶乘机器内部都包含另一台阶乘机器,整个机器包含一个相似机器的无限嵌套,因此无法由固定的、有限数量的部件构造而成。
然而,如果我们能够安排对机器的每个嵌套实例使用相同的组件,那么就可以将阶乘过程实现为一台寄存器计算机。具体来说,计算 n! 的机器应该使用相同的组件来处理计算 (n - 1)! 的子问题、处理 (n - 2)! 的子问题,等等。这是可行的,因为虽然阶乘过程要求需要无限多份相同的机器副本才能执行一次计算,但在任何给定时刻只有其中的一个副本需要处于活动状态。当机器遇到递归子问题时,它可以暂停主问题的工作,重用相同的物理部件来处理子问题,然后继续被暂停的计算。
在子问题中,寄存器的内容将与主问题中的不同。(在这种情况下 n 寄存器被递减了。)为了能够继续被暂停的计算,机器必须保存任何在子问题求解后还会需要的寄存器的内容,以便这些内容可以被恢复,从而继续被暂停的计算。在阶乘的情况下,我们将保存 n 的旧值,以便在完成递减后的 n 寄存器的阶乘计算后恢复它。2
由于对嵌套递归调用的深度没有先验限制,我们可能需要保存任意数量的寄存器值。这些值必须按照与保存时相反的顺序恢复,因为在递归嵌套中,最后进入的子问题最先完成。这决定了需要使用堆栈(即"后进先出"的数据结构)来保存寄存器值。我们可以通过添加两种指令来扩展寄存器计算机语言以包含堆栈:值使用 save 指令放入堆栈,并使用 restore 指令从堆栈中恢复。在一系列值被 save 到堆栈上之后,一系列 restore 将以相反的顺序检索这些值。3
借助堆栈,我们可以为每个阶乘子问题重用阶乘机器数据路径的单一副本。在重用操作数据路径的控制器序列方面也存在类似的设计问题。为了重新执行阶乘计算,控制器不能像迭代过程那样简单地循环回到起点,因为在解决了 (n - 1)! 子问题之后,机器还必须将结果乘以 n。控制器必须暂停其 n! 的计算,解决 (n - 1)! 子问题,然后继续其 n! 的计算。这种对阶乘计算的看法建议使用第 5.1.3 节中描述的子程序机制,让控制器使用 continue 寄存器转移到求解子问题的序列部分,然后在主问题中继续之前中断的位置。因此,我们可以创建一个阶乘子程序,它返回到存储在 continue 寄存器中的入口点。在每个子程序调用前后,我们像对待 n 寄存器一样保存和恢复 continue,因为阶乘计算的每个"层次"都将使用同一个 continue 寄存器。也就是说,阶乘子程序在为子问题调用自身时,必须在 continue 中放入一个新值,但它将需要旧值以便返回到调用它来解决子问题的位置。
图 5.11 展示了实现递归 factorial 过程的机器的数据路径和控制器。该机器有一个堆栈和三个寄存器,称为 n、val 和 continue。为简化数据路径图,我们没有命名寄存器赋值按钮,只命名了堆栈操作按钮(sc 和 sn 用于保存寄存器,rc 和 rn 用于恢复寄存器)。要操作该机器,我们将想要计算阶乘的数放入寄存器 n 并启动机器。当机器到达 fact-done 时,计算完成,答案将在 val 寄存器中找到。在控制器序列中,n 和 continue 在每次递归调用之前被保存,并在调用返回时恢复。从调用返回通过跳转到存储在 continue 中的位置来实现。Continue 在机器启动时被初始化,以便最后的返回将转到 fact-done。持有阶乘计算结果的 val 寄存器在递归调用前不被保存,因为 val 的旧内容在子程序返回后没有用处。只有新值(由于计算产生的值)才是需要的。 虽然原则上阶乘计算需要一台无限的机器,但图 5.11 中的机器实际上是有限的,除了堆栈(它可能是无界的)。然而,任何特定的堆栈物理实现都将具有有限的大小,这将限制机器能够处理的递归调用深度。这种阶乘实现说明了将递归算法实现为普通寄存器计算机(通过堆栈增强)的一般策略。当遇到递归子问题时,我们将那些当前值在子问题求解后还会需要的寄存器保存到堆栈上,求解递归子问题,然后恢复被保存的寄存器并继续执行主问题。continue 寄存器必须始终被保存。是否需要保存其他寄存器取决于具体的机器,因为并非所有的递归计算都需要在子问题求解期间被修改的寄存器的原始值(见练习 5.4)。
让我们考察一个更复杂的递归过程——斐波那契数的树递归计算,我们在第 1.2.2 节介绍过:
(define (fib n)
(if (< n 2)
n
(+ (fib (- n 1)) (fib (- n 2)))))
与阶乘一样,我们可以将递归的斐波那契计算实现为一台具有寄存器 n、val 和 continue 的寄存器计算机。该机器比阶乘的那台更复杂,因为在控制器序列中有两个需要执行递归调用的位置——一次计算 Fib(n - 1),一次计算 Fib(n - 2)。为了设置每次调用,我们保存稍后需要的值的寄存器,将 n 寄存器设置为需要递归计算 Fib 的数(n - 1 或 n - 2),并将 continue 赋值为主序列中要返回的入口点(分别为 afterfib-n-1 或 afterfib-n-2)。然后我们转到 fib-loop。当从递归调用返回时,答案在 val 中。图 5.12 显示了该机器的控制器序列。
练习 5.4. 请为以下每个过程指定相应的寄存器计算机。对于每台机器,编写控制器指令序列并画出数据路径图。
a. 递归求幂:
(define (expt b n)
(if (= n 0)
1
(* b (expt b (- n 1)))))
b. 迭代求幂:
(define (expt b n)
(define (expt-iter counter product)
(if (= counter 0)
product
(expt-iter (- counter 1) (* b product))))
(expt-iter n 1))
练习 5.5. 手工模拟阶乘计算机和斐波那契计算机,使用一些非平凡输入(需要至少执行一次递归调用)。在执行过程中的每个重要点,显示堆栈的内容。
练习 5.6. Ben Bitdiddle 观察到,斐波那契计算机的控制器序列有一个多余的 save 和一个多余的 restore,可以移除它们以使机器更快。这些指令在哪里?
我们的寄存器计算机语言中的控制器指令具有以下形式之一,其中每个 <inputi> 是 (reg <register-name>) 或 (const <constant-value>)。
以下指令是在第 5.1.1 节中引入的:
(assign <register-name> (reg <register-name>))
(assign <register-name> (const <constant-value>))
(assign <register-name> (op <operation-name>) <input1> ... <inputn>)
(perform (op <operation-name>) <input1> ... <inputn>)
(test (op <operation-name>) <input1> ... <inputn>)
(branch (label <label-name>))
(goto (label <label-name>))
使用寄存器保存标签是在第 5.1.3 节中引入的:
(assign <register-name> (label <label-name>))
(goto (reg <register-name>))
使用堆栈的指令是在第 5.1.4 节中引入的:
(save <register-name>)
(restore <register-name>)
到目前为止,我们见过的唯一一种 <constant-value> 是数字,但之后我们还将使用字符串、符号和列表。例如, (const "abc") 是字符串 "abc", (const abc) 是符号 abc, (const (a b c)) 是列表 (a b c), 而 (const ()) 是空列表。
1 这个假设掩盖了大量的复杂性。通常,Lisp 系统实现的很大一部分都致力于使读取和打印功能正常工作。
2 有人可能会争论说我们不需要保存旧的 n;在递减它并解决了子问题之后,我们可以简单地递增它来恢复旧值。尽管这种策略对阶乘有效,但它通常不可行,因为寄存器的旧值并不总是可以从新值计算出来。