|
当我们在第 1 章中引入复合过程时,我们使用 代换求值模型 (第 1.1.5 节)来定义将过程应用于参数的含义:
一旦我们将赋值引入编程语言,这样的 定义就不再充分。特别是, 第 3.1.3 节指出,在存在赋值的情况下, 变量不能再被认为只是值的名称。 相反,变量必须以某种方式指定一个可以存储值的"位置"。 在我们的新求值模型中,这些 位置将被保存在称为 环境 的结构中。
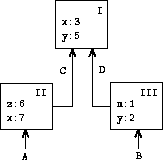
一个环境是一个 框架 的序列。每个框架是一个 (可能为空的)绑定 表,它将变量名与 其对应的值关联起来。(单个框架对任何变量最多只能包含一个 绑定。)每个框架还有一个指向其 外围环境 的指针,除非出于讨论的目的, 该框架被认为是 全局 的。相对于某个环境,变量的值 是该环境中的第一个包含该变量绑定的框架所给出的值。 如果序列中没有框架为该变量指定绑定,则称该变量在 该环境中是 未绑定 的。
图 3.1 显示了一个简单的环境 结构,由三个框架组成,分别标记为 I、II 和 III。在 图中,A、B、C 和 D 是指向环境的指针。C 和 D 指向 同一个环境。变量 z 和 x 绑定在 框架 II 中,而 y 和 x 绑定在框架 I 中。 环境 D 中 x 的值是 3。相对于 环境 B,x 的值也是 3。这是按如下方式确定的:我们 检查序列中的第一个框架(框架 III),没有找到 x 的 绑定,因此我们继续查找外围环境 D,并在 框架 I 中找到绑定。另一方面,环境 A 中 x 的值 是 7,因为序列中的第一个框架(框架 II)包含 x 到 7 的绑定。相对于环境 A, 框架 II 中 x 到 7 的绑定被称为 遮蔽 了 框架 I 中 x 到 3 的绑定。
环境对求值过程至关重要, 因为它决定了表达式应该被求值的上下文。 实际上,可以说编程语言中的表达式 本身没有任何意义。相反, 表达式只有在相对于某个求值它的环境时 才获得意义。即使像 (+ 1 1) 这样简单的表达式的解释, 也依赖于理解我们是在 + 是加法符号的上下文中 进行操作。因此,在我们的求值模型中,我们将始终谈论 相对于某个环境求值表达式。为了描述与 解释器的交互,我们将假设存在一个 全局 环境,由一个(没有外围环境的)单一框架组成, 该框架包含与基本过程关联的符号的值。 例如,+ 是加法符号这一概念是通过说符号 + 在全局环境中被绑定到基本加法过程来捕获的。
解释器如何求值组合式的整体规范 与我们在第 1.1.3 节首次引入它时保持相同:
1. 求值组合式的各个子表达式。12
2. 将运算符子表达式的值应用于运算对象子表达式的值。
在指定将复合过程应用于参数的含义时, 环境求值模型取代了代换模型。
在环境求值模型中,一个过程总是一个由一些代码 和一个指向环境的指针组成的对偶。过程 只有一种创建方式:通过求值一个 lambda 表达式。 这产生一个过程,其代码从 lambda 表达式的文本获得, 其环境是求值该 lambda 表达式以产生该过程的 环境。例如,考虑在全局环境中求值的过程定义
过程定义语法 只是底层隐式 lambda 表达式的语法糖。 使用下面的写法也是等价的:
(define square
(lambda (x) (* x x)))
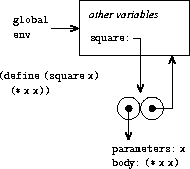
它在全局环境中求值 (lambda (x) (* x x)) 并将 square 绑定到结果值。
图 3.2 显示了求值这个 define 表达式的结果。过程对象是一个对偶,其代码 指定该过程有一个形参,即 x, 以及一个过程体 (* x x)。过程的 环境部分是一个指向全局环境的指针,因为那是 求值 lambda 表达式以产生该过程的 环境。一个将过程对象与符号 square 关联起来的新绑定 已被添加到全局框架中。通常,define 通过向框架添加绑定来创建定义。
|
现在我们已经看到了过程是如何创建的,我们可以描述 过程是如何应用的。环境模型规定:要将一个 过程应用于参数,创建一个新环境,其中包含一个将 参数绑定到参数值的框架。该框架的 外围环境是过程所指定的环境。 然后,在这个新环境中,求值过程体。
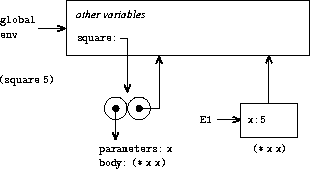
为了展示如何遵循这条规则,图 3.3 展示了在全局环境中求值表达式 (square 5) 所创建的环境结构,其中 square 是在 图 3.2 中生成的过程。应用该过程导致 创建一个新环境,在图中标记为 E1,它 始于一个框架,其中过程的形参 x 被绑定到参数 5。从该框架向上指的 指针显示该框架的外围环境是 全局环境。这里选择全局环境是因为 这是作为 square 过程对象的一部分所指示的环境。 在 E1 内部,我们求值过程体 (* x x)。由于 E1 中 x 的值是 5,结果是 (* 5 5),即 25。
|
过程应用的环境模型可以总结为 两条规则:
我们还规定,使用 define 定义一个符号会在 当前环境框架中创建一个绑定,并将该符号赋值为 指定的值。13 最后,我们规定了 set!(这个操作最初迫使我们引入环境模型)的行为。 在一些环境中求值表达式 (set! <变量> <值>) 会在该环境中定位该变量的绑定, 并修改该绑定以指示 新值。也就是说,找到环境中第一个包含该变量绑定的框架 并修改该框架。如果 该变量在环境中未绑定,则 set! 会 报告一个错误。
这些求值规则虽然比 代换模型复杂得多,但仍然相当直接。此外, 这个求值模型虽然是抽象的,但为解释器如何求值表达式 提供了正确的描述。在第 4 章中,我们 将看到这个模型如何作为实现一个可工作解释器的蓝图。 下面的各节通过分析一些示例程序来详细阐述该模型。
当我们在第 1.1.5 节中引入代换模型时, 我们展示了在给定以下过程定义的情况下,组合式 (f 5) 是如何求值得出 136 的:
(define (square x)
(* x x))
(define (sum-of-squares x y)
(+ (square x) (square y)))
(define (f a)
(sum-of-squares (+ a 1) (* a 2)))
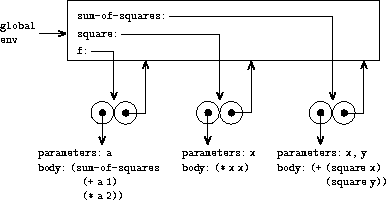
我们可以使用环境模型分析同样的例子。 图 3.4 显示了通过在全局环境中求值 f、square 和 sum-of-squares 的定义而创建的三个过程对象。 每个过程对象由一些代码以及一个指向全局环境的指针组成。
|
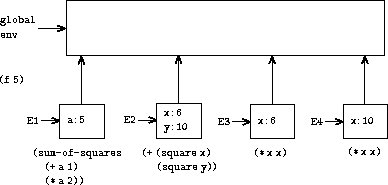
在图 3.5 中,我们看到通过求值表达式 (f 5) 创建的环境结构。 对 f 的调用创建了一个新环境 E1,始于一个框架,其中 f 的形参 a 被绑定到参数 5。在 E1 中, 我们求值 f 的过程体:
(sum-of-squares (+ a 1) (* a 2))
|
要求值这个组合式,我们首先求值子表达式。 第一个子表达式 sum-of-squares 的值是一个 过程对象。(请注意这个值是如何找到的:我们首先在 E1 的第一个框架中查找,其中没有 sum-of-squares 的绑定。然后我们继续到外围环境, 即全局环境,并找到图 3.4 中所示的绑定。) 其他两个子表达式通过应用基本操作 + 和 * 来求值两个组合式 (+ a 1) 和 (* a 2), 分别得到 6 和 10。
现在我们将过程对象 sum-of-squares 应用于 参数 6 和 10。这导致一个新环境 E2,其中 形参 x 和 y 被绑定到参数。 在 E2 内部,我们求值组合式 (+ (square x) (square y))。 这导致我们求值 (square x),其中 square 在 全局框架中找到,x 是 6。我们再次建立一个 新环境 E3,其中 x 被绑定到 6,并且在这个环境中 我们求值 square 的过程体,即 (* x x)。同时作为 应用 sum-of-squares 的一部分,我们必须求值 子表达式 (square y),其中 y 是 10。这第二次对 square 的调用创建了另一个环境 E4,其中 square 的 形参 x 被绑定到 10。并且在 E4 内部 我们必须求值 (* x x)。
需要观察的重要点是每次对 square 的调用 都创建一个包含 x 绑定的新环境。我们 可以在这里看到不同的框架如何用于保持不同的 局部变量(它们都名为 x)相互分离。注意每个由 square 创建的框架都指向全局环境,因为这是 square 过程对象所指示的环境。
子表达式求值完毕后,结果被 返回。两次对 square 调用产生的值被 sum-of-squares 相加,然后这个结果由 f 返回。 由于我们这里的重点是环境结构,我们不会 详细讨论这些返回值是如何在调用之间传递的; 然而,这也是求值过程的一个重要方面, 我们将在第 5 章中详细讨论。
练习 3.9. 在第 1.2.1 节中,我们使用了代换模型来分析两个 计算阶乘的过程,一个是递归版本:
(define (factorial n)
(if (= n 1)
1
(* n (factorial (- n 1)))))
另一个是迭代版本:
(define (factorial n)
(fact-iter 1 1 n))
(define (fact-iter product counter max-count)
(if (> counter max-count)
product
(fact-iter (* counter product)
(+ counter 1)
max-count)))
展示使用每个版本的 factorial 过程求值 (factorial 6) 时所创建的环境结构。14
我们可以借助环境模型来了解过程和赋值如何用于表示具有局部状态的对象。作为一个 例子,考虑第 3.1.1 节中通过调用 过程创建的"取款处理器":
(define (make-withdraw balance)
(lambda (amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds")))
让我们描述以下求值过程:
(define W1 (make-withdraw 100))
接着是
(W1 50)
50
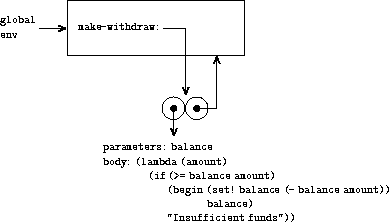
图 3.6 显示了在全局环境中定义 make-withdraw 过程的结果。这产生了一个 包含指向全局环境指针的过程对象。 到目前为止,这与我们已经看到的例子没有什么不同, 只是该过程体本身是一个 lambda 表达式。
|
计算中有趣的部分发生在我们将过程 make-withdraw 应用于一个参数时:
(define W1 (make-withdraw 100))
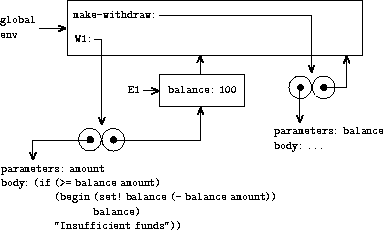
像往常一样,我们首先建立一个环境 E1,其中 形参 balance 被绑定到参数 100。在这个 环境中,我们求值 make-withdraw 的过程体,即 lambda 表达式。这构造了一个新的过程对象, 其代码由 lambda 指定,其环境 是 E1,即求值 lambda 以产生该过程的环境。 结果的过程对象是对 make-withdraw 的调用返回的值。 由于 define 本身是在全局环境中求值的,该值被绑定到全局环境中的 W1。图 3.7 显示了 结果的环境结构。
|
现在我们可以分析当 W1 被应用于一个 参数时会发生什么:
(W1 50)
50
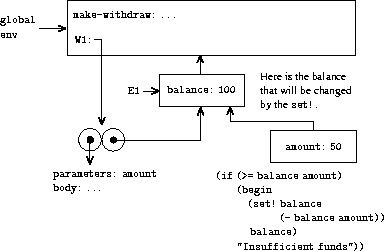
我们首先构造一个框架,其中 W1 的形参 amount 被绑定到参数 50。需要观察的 关键点是这个框架的外围环境不是 全局环境,而是环境 E1,因为这是 W1 过程对象所指定的环境。 在这个新环境中,我们求值过程体:
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds")
结果的环境结构如图 3.8 所示。 被求值的表达式引用了 amount 和 balance。amount 将在 环境的第一个框架中找到,而 balance 将 通过跟随外围环境指针到达 E1 找到。
|
当 set! 被执行时,E1 中 balance 的绑定被改变。在对 W1 的调用完成时, balance 是 50,并且包含 balance 的框架 仍然被过程对象 W1 指向。绑定 amount 的框架 (我们在其中执行了改变 balance 的代码)不再 相关,因为构造它的过程调用已经终止, 并且没有来自环境其他部分的指针指向该框架。 下次调用 W1 时,将构建一个新的 绑定 amount 的框架,其外围环境是 E1。 我们看到 E1 充当了保存过程对象 W1 的局部状态 变量的"位置"。图 3.9 显示了对 W1 调用后的情况。
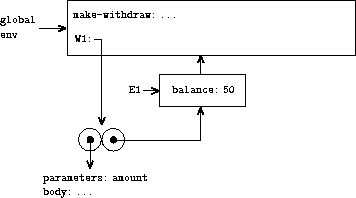
|
观察当我们通过另一次对 make-withdraw 的调用来创建第二个"取款"对象时会发生什么:
(define W2 (make-withdraw 100))
这产生了图 3.10 中的环境结构,它显示 W2 是一个过程对象,即一个带有一些代码 和一个环境的对偶。W2 的环境 E2 是由对 make-withdraw 的调用创建的。它包含一个框架,其中包含 balance 自己的局部绑定。另一方面,W1 和 W2 具有相同的代码:由 make-withdraw 过程体中的 lambda 表达式指定的代码。15 我们在这里看到为什么 W1 和 W2 表现为独立的对象。对 W1 的调用引用存储在 E1 中的状态 变量 balance,而对 W2 的调用 引用存储在 E2 中的 balance。因此,一个对象的局部 状态的改变不会影响另一个对象。
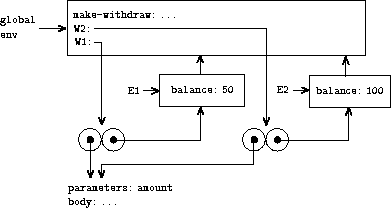
|
练习 3.10. 在 make-withdraw 过程中,局部变量 balance 是作为 make-withdraw 的一个参数创建的。我们也可以 使用 let 显式地创建局部状态变量,如下所示:
(define (make-withdraw initial-amount)
(let ((balance initial-amount))
(lambda (amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))))
回顾第 1.3.2 节中的内容,let 只是 过程调用的语法糖:
(let ((<变量> <表达式>)) <体>)
被解释为以下写法的另一种语法:
((lambda (<变量>) <体>) <表达式>)
使用环境模型分析这个 make-withdraw 的替代 版本,绘制类似上面的图来说明以下交互:
(define W1 (make-withdraw 100))
(W1 50)
(define W2 (make-withdraw 100))
证明这两个版本的 make-withdraw 创建的对象具有 相同的行为。这两种版本的环境结构有何不同?
第 1.1.8 节引入了过程可以有内部 定义的想法,从而产生了如下的块结构, 用于计算平方根的过程:
(define (sqrt x)
(define (good-enough? guess)
(< (abs (- (square guess) x)) 0.001))
(define (improve guess)
(average guess (/ x guess)))
(define (sqrt-iter guess)
(if (good-enough? guess)
guess
(sqrt-iter (improve guess))))
(sqrt-iter 1.0))
现在我们可以使用环境模型来理解为什么这些内部 定义如预期那样工作。图 3.11 显示了在 求值表达式 (sqrt 2) 的过程中,内部过程 good-enough? 首次被调用时的点,此时 guess 等于 1。
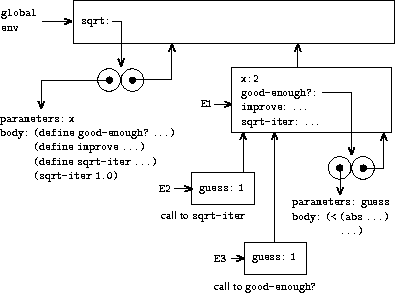
|
观察环境的结构。Sqrt 是 全局环境中的一个符号,被绑定到一个过程对象,其 关联环境是全局环境。当 sqrt 被调用时, 形成了一个从属于全局环境的新环境 E1,其中 参数 x 被绑定到 2。sqrt 的过程体 随后在 E1 中被求值。由于 sqrt 过程体中的第一个表达式是
(define (good-enough? guess)
(< (abs (- (square guess) x)) 0.001))
求值这个表达式在环境 E1 中定义了过程 good-enough?。 更精确地说,符号 good-enough? 被添加到 E1 的第一个框架中,绑定到一个 关联环境为 E1 的过程对象。类似地,improve 和 sqrt-iter 在 E1 中被定义为过程。为 简洁起见,图 3.11 只显示了 good-enough? 的过程对象。
在局部过程定义之后, 表达式 (sqrt-iter 1.0) 被求值, 仍然在环境 E1 中。因此,E1 中绑定到 sqrt-iter 的过程对象被调用,参数为 1。 这创建了一个环境 E2,其中 sqrt-iter 的参数 guess 被绑定到 1。Sqrt-iter 接着使用 guess 的值(来自 E2)作为 good-enough? 的参数调用 good-enough?。 这建立了另一个环境 E3,其中 guess(good-enough? 的参数)被绑定到 1。虽然 sqrt-iter 和 good-enough? 都有一个名为 guess 的参数,但它们是两个 位于不同框架中的不同局部变量。此外,E2 和 E3 都以 E1 作为它们的外围环境,因为 sqrt-iter 和 good-enough? 过程都以 E1 作为它们的 环境部分。其一个后果是,出现在 good-enough? 体中的符号 x 将引用 E1 中出现的 x 的绑定,即最初调用 sqrt 过程时的 x 的值。 环境模型因此解释了使局部过程定义成为模块化程序的有用技术的 两个关键性质:
练习 3.11. 在第 3.2.3 节中, 我们看到了环境模型如何描述 具有局部状态的过程的行为。现在我们看到了 内部定义如何工作。一个典型的消息传递过程 包含了这两个方面。考虑 第 3.1.1 节中的银行账户过程:
(define (make-account balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(define (dispatch m)
(cond ((eq? m 'withdraw) withdraw)
((eq? m 'deposit) deposit)
(else (error "Unknown request -- MAKE-ACCOUNT"
m))))
dispatch)
展示以下交互序列所生成的环境结构:
(define acc (make-account 50))
((acc 'deposit) 40)
90
((acc 'withdraw) 60)
30
acc 的局部状态保存在哪里?假设我们定义另一个账户:
(define acc2 (make-account 100))
两个账户的局部状态如何保持不同?acc 和 acc2 之间 共享了环境结构的哪些部分?
12 赋值在求值规则的第 1 步中引入了一个微妙之处。 如练习 3.8 所示,赋值的存在 使我们能够编写出这样的表达式,其产生的值取决于组合式中子表达式 被求值的顺序。因此,精确地说,我们应该在第 1 步中指定一个求值 顺序(例如,从左到右或从右到左)。然而,这个 顺序应该始终被视为实现细节, 人们绝不应编写依赖于某种特定顺序的程序。 例如,一个复杂的编译器可能通过改变子表达式求值的顺序来优化程序。
13 如果当前框架中已经存在该变量的绑定,则会修改 该绑定。这很方便,因为它允许符号的重新定义;然而,这也 意味着 define 可用于改变值,这引出了 不使用显式 set! 的赋值问题。 因此,有些人更倾向于对现有符号的重新定义发出错误或警告信号。
14 环境模型不会澄清我们在 第 1.2.1 节中的主张,即解释器可以 使用尾递归以常量空间量执行像 fact-iter 这样的过程。 当我们 在第 5.4 节中讨论解释器的控制结构时, 我们将讨论尾递归。
15 W1 和 W2 是共享存储在计算机中的同一物理代码,还是各自保存一份代码副本, 这是一个实现细节。对于我们在第 4 章中实现的解释器, 代码实际上是共享的。