|
我们将用 Lisp 程序来实现 Lisp 的求值器。用本身用 Lisp 实现的求值器来求值 Lisp 程序,这看起来好像是循环的。然而,求值是一个过程,因此用 Lisp 来描述求值过程是合适的,毕竟 Lisp 是我们用来描述过程的工具。3 用被求值的同一语言编写的求值器被称为是元循环的。
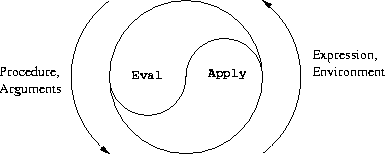
元循环求值器本质上是第 3.2 节描述的环境求值模型的 Scheme 表述。回忆一下,该模型有两个基本部分:
1. 要求值一个组合式(除特殊形式外的复合表达式),先求值子表达式,然后将运算符子表达式的值作用于运算对象子表达式的值。
2. 要将一个复合过程应用于一组参数,在一个新环境中求值该过程体。为了构造这个环境,将过程对象的环境部分扩展为一个框架,其中过程的形参被绑定到该过程所应用的参数上。
这两个规则描述了求值过程的本质,即一个基本循环:在环境中需要求值的表达式被归约为需要应用于参数的过程,而这些过程又被归约为需要在新环境中求值的新表达式,依此类推,直到我们到达符号(在环境中查找它们的值)和基本过程(直接应用)(见图 4.1)。4 这个求值循环将体现在求值器中两个关键过程 eval 和 apply 的相互作用中,这两个过程将在第 4.1.1 节中描述(见图 4.1)。
求值器的实现将依赖于定义待求值表达式语法的过程。我们将使用数据抽象使求值器独立于语言的表示。例如,我们并不承诺赋值用符号 set! 开头的列表表示,而是使用抽象谓词 assignment? 来测试赋值,并使用抽象选择器 assignment-variable 和 assignment-value 来访问赋值的各个部分。表达式的实现将在第 4.1.2 节中详细描述。还有一些操作在第 4.1.3 节中描述,它们规定了过程和环境的表示。例如,make-procedure 构造复合过程,lookup-variable-value 访问变量的值,apply-primitive-procedure 将基本过程应用于给定的参数列表。
求值过程可以描述为两个过程之间的相互作用:eval 和 apply。
Eval 以一个表达式和一个环境为参数。它对表达式进行分类并指导其求值。Eval 的结构是对待求值表达式的语法类型进行案例分析。为了保持过程的一般性,我们抽象地确定表达式的类型,不对各种类型的表达式的任何特定表示做出承诺。每种类型的表达式都有一个测试谓词和一个用于选择其部分的抽象方法。这种抽象语法使我们很容易看到,我们可以通过使用同一求值器但使用不同的语法过程集合来改变语言的语法。
(define (eval exp env)
(cond ((self-evaluating? exp) exp)
((variable? exp) (lookup-variable-value exp env))
((quoted? exp) (text-of-quotation exp))
((assignment? exp) (eval-assignment exp env))
((definition? exp) (eval-definition exp env))
((if? exp) (eval-if exp env))
((lambda? exp)
(make-procedure (lambda-parameters exp)
(lambda-body exp)
env))
((begin? exp)
(eval-sequence (begin-actions exp) env))
((cond? exp) (eval (cond->if exp) env))
((application? exp)
(apply (eval (operator exp) env)
(list-of-values (operands exp) env)))
(else
(error "Unknown expression type -- EVAL" exp))))
为清晰起见,eval 使用 cond 实现为案例分析。这样做的缺点是我们的过程只处理少数几种可区分的表达式类型,且不修改 eval 的定义就无法定义新的类型。在大多数 Lisp 实现中,表达式类型的分派是以数据导向风格完成的。这允许用户添加 eval 能够区分的新的表达式类型,而无需修改 eval 本身的定义。(见练习 4.3。)
Apply 接受两个参数,一个过程以及该过程应被应用于的参数列表。Apply 将过程分为两类:它调用 apply-primitive-procedure 来应用基本过程;它通过顺序求值组成过程体的表达式来应用复合过程。求值复合过程体的环境是通过扩展该过程携带的基础环境来构造的,扩展中增加一个框架,将该过程的参数绑定到要应用该过程的参数上。 以下是 apply 的定义:
(define (apply procedure arguments)
(cond ((primitive-procedure? procedure)
(apply-primitive-procedure procedure arguments))
((compound-procedure? procedure)
(eval-sequence
(procedure-body procedure)
(extend-environment
(procedure-parameters procedure)
arguments
(procedure-environment procedure))))
(else
(error
"Unknown procedure type -- APPLY" procedure))))
当 eval 处理过程应用时,它使用 list-of-values 来生成过程将被应用到的参数列表。List-of-values 以组合式的运算对象为参数。它求值每个运算对象并返回对应值的列表:5
(define (list-of-values exps env)
(if (no-operands? exps)
'()
(cons (eval (first-operand exps) env)
(list-of-values (rest-operands exps) env))))
Eval-if 在给定环境中求值 if 表达式的谓词部分。如果结果为真,eval-if 求值 consequent,否则求值 alternative:
(define (eval-if exp env)
(if (true? (eval (if-predicate exp) env))
(eval (if-consequent exp) env)
(eval (if-alternative exp) env)))
在 eval-if 中使用 true? 凸显了被实现语言与实现语言之间连接的问题。if-predicate 在被实现语言中求值,因此产生该语言中的一个值。解释器谓词 true? 将该值转换为可在实现语言的 if 中测试的值:元循环的真值表示可能与底层的 Scheme 不同。6
Eval-sequence 被 apply 用于求值过程体中的表达式序列,也被 eval 用于求值 begin 表达式中的表达式序列。它以表达式序列和环境为参数,按出现顺序求值这些表达式。返回的值是最后一个表达式的值。
(define (eval-sequence exps env)
(cond ((last-exp? exps) (eval (first-exp exps) env))
(else (eval (first-exp exps) env)
(eval-sequence (rest-exps exps) env))))
以下过程处理对变量的赋值。它调用 eval 来找到要赋的值,然后将变量和结果值传递给 set-variable-value! 以安装在指定的环境中。
(define (eval-assignment exp env)
(set-variable-value! (assignment-variable exp)
(eval (assignment-value exp) env)
env)
'ok)
变量的定义以类似方式处理。7
(define (eval-definition exp env)
(define-variable! (definition-variable exp)
(eval (definition-value exp) env)
env)
'ok)
我们在此选择返回符号 ok 作为赋值或定义的值。8
练习 4.1. 请注意,我们无法判断元循环求值器是从左到右还是从右到左求值运算对象。它的求值顺序继承自底层的 Lisp:如果 list-of-values 中 cons 的参数是从左到右求值的,那么 list-of-values 将从左到右求值运算对象;如果 cons 的参数是从右到左求值的,那么 list-of-values 将从右到左求值运算对象。
请编写一个 list-of-values 的版本,无论底层 Lisp 中的求值顺序如何,都从左到右求值运算对象。还要编写一个从右到左求值运算对象的版本。
这个求值器让人想起第 2.3.2 节讨论的符号求导程序。两个程序都操作符号表达式。在两个程序中,对复合表达式进行操作的结果是通过递归地作用于表达式的组成部分,并以依赖于表达式类型的方式组合结果来确定的。在这两个程序中,我们都使用了数据抽象来将操作的一般规则与表达式表示方式的细节解耦。在求导程序中,这意味着同一个求导过程可以处理前缀形式、中缀形式或其他形式的代数表达式。对于求值器来说,这意味着被求值语言的语法完全由那些对表达式进行分类和提取其组成部分的过程决定。
以下是我们语言语法的规范说明:
¤ 自求值项只有数字和字符串:
(define (self-evaluating? exp)
(cond ((number? exp) true)
((string? exp) true)
(else false)))
¤ 变量用符号表示:
(define (variable? exp) (symbol? exp))
¤ Quoted 表达式的形式为 (quote <引用的文本>):9
(define (quoted? exp)
(tagged-list? exp 'quote))
(define (text-of-quotation exp) (cadr exp))
Quoted? 是用过程 tagged-list? 定义的,该过程识别以指定符号开头的列表:
(define (tagged-list? exp tag)
(if (pair? exp)
(eq? (car exp) tag)
false))
¤ 赋值的形式为 (set! <变量> <值>):
(define (assignment? exp)
(tagged-list? exp 'set!))
(define (assignment-variable exp) (cadr exp))
(define (assignment-value exp) (caddr exp))
¤ 定义的形式为
(define <var> <value>)
或以下形式:
(define (<var> <parameter1> ... <parametern>)
<body>)
The latter form (standard procedure definition) is syntactic sugar for
(define <var>
(lambda (<parameter1> ... <parametern>)
<body>))
相应的语法过程如下:
(define (definition? exp)
(tagged-list? exp 'define))
(define (definition-variable exp)
(if (symbol? (cadr exp))
(cadr exp)
(caadr exp)))
(define (definition-value exp)
(if (symbol? (cadr exp))
(caddr exp)
(make-lambda (cdadr exp) ; formal parameters
(cddr exp)))) ; body
¤ Lambda 表达式是以符号 lambda 开头的列表:
(define (lambda? exp) (tagged-list? exp 'lambda))
(define (lambda-parameters exp) (cadr exp))
(define (lambda-body exp) (cddr exp))
我们还为 lambda 表达式提供了一个构造器, 由上面的 definition-value 使用:
(define (make-lambda parameters body)
(cons 'lambda (cons parameters body)))
¤ 条件表达式以 if 开头,包含一个谓词、一个 consequent 和一个(可选的)alternative。如果表达式没有 alternative 部分,我们提供 false 作为 alternative。10
(define (if? exp) (tagged-list? exp 'if))
(define (if-predicate exp) (cadr exp))
(define (if-consequent exp) (caddr exp))
(define (if-alternative exp)
(if (not (null? (cdddr exp)))
(cadddr exp)
'false))
我们还为 if 表达式提供了一个构造器, 供 cond->if 用于将 cond 表达式转换 为 if 表达式:
(define (make-if predicate consequent alternative)
(list 'if predicate consequent alternative))
¤ Begin 将一组表达式序列打包成一个单独的表达式。我们包含了针对 begin 表达式的语法操作,用于从 begin 表达式中提取实际的序列,以及返回序列中第一个表达式和其余表达式的选择器。11
(define (begin? exp) (tagged-list? exp 'begin))
(define (begin-actions exp) (cdr exp))
(define (last-exp? seq) (null? (cdr seq)))
(define (first-exp seq) (car seq))
(define (rest-exps seq) (cdr seq))
我们还包含一个构造器 sequence->exp(供 cond->if 使用),它将一个序列转换为单个表达式,必要时使用 begin:
(define (sequence->exp seq)
(cond ((null? seq) seq)
((last-exp? seq) (first-exp seq))
(else (make-begin seq))))
(define (make-begin seq) (cons 'begin seq))
¤ 过程应用是任何不属于上述表达式类型的复合表达式。表达式的 car 是运算符,cdr 是运算对象列表:
(define (application? exp) (pair? exp))
(define (operator exp) (car exp))
(define (operands exp) (cdr exp))
(define (no-operands? ops) (null? ops))
(define (first-operand ops) (car ops))
(define (rest-operands ops) (cdr ops))
我们语言中的某些特殊形式可以用涉及其他特殊形式的表达式来定义,而不是直接实现。一个例子是 cond,它可以作为 if 表达式的嵌套来实现。例如,我们可以将求值以下表达式的问题
(cond ((> x 0) x)
((= x 0) (display 'zero) 0)
(else (- x)))
归约为求值涉及 if 和 begin 表达式的以下表达式的问题:
(if (> x 0)
x
(if (= x 0)
(begin (display 'zero)
0)
(- x)))
以这种方式实现 cond 的求值简化了求值器,因为它减少了必须显式指定求值过程的特殊形式的数量。
我们包含提取 cond 表达式各部分的语法过程,以及将 cond 表达式转换为 if 表达式的过程 cond->if。一个案例分析以 cond 开头,并由一个谓词-动作子句列表组成。如果某个子句的谓词是符号 else,那么它就是 else 子句。12
(define (cond? exp) (tagged-list? exp 'cond))
(define (cond-clauses exp) (cdr exp))
(define (cond-else-clause? clause)
(eq? (cond-predicate clause) 'else))
(define (cond-predicate clause) (car clause))
(define (cond-actions clause) (cdr clause))
(define (cond->if exp)
(expand-clauses (cond-clauses exp)))
(define (expand-clauses clauses)
(if (null? clauses)
'false ; no else clause
(let ((first (car clauses))
(rest (cdr clauses)))
(if (cond-else-clause? first)
(if (null? rest)
(sequence->exp (cond-actions first))
(error "ELSE clause isn't last -- COND->IF"
clauses))
(make-if (cond-predicate first)
(sequence->exp (cond-actions first))
(expand-clauses rest))))))
我们选择作为语法转换来实现的表达式(如 cond)被称为派生表达式。Let 表达式也是派生表达式(见练习 4.6)。13
练习 4.2. Louis Reasoner 打算重新排列 eval 中的 cond 子句,使得过程应用的子句出现在赋值的子句之前。他争辩说这将使解释器更高效:由于程序通常包含的应用多于赋值、定义等,他修改后的 eval 在识别表达式类型之前通常会比原来的 eval 检查更少的子句。
a. Louis 的计划有什么问题?(提示:Louis 的求值器会如何处理表达式 (define x 3)?)
b. Louis 对他的计划无效感到沮丧。他愿意不惜一切代价让他的求值器在检查大多数其他类型的表达式之前识别过程应用。通过改变被求值语言的语法来帮助他,使过程应用以 call 开头。例如,我们将不再写 (factorial 3),而是必须写 (call factorial 3),不再写 (+ 1 2),而是必须写 (call + 1 2)。
练习 4.3. 重写 eval,使其分派以数据导向风格完成。将此与练习 2.73 中的数据导向求导过程进行比较。(你可以将复合表达式的 car 用作表达式的类型,这对于本节中实现的语法是合适的。)
练习 4.4. 回忆第 1 章中特殊形式 and 和 or 的定义:
通过定义适当的语法过程和求值过程 eval-and 和 eval-or,将 and 和 or 安装为求值器的新特殊形式。或者,展示如何将 and 和 or 实现为派生表达式。
练习 4.5. Scheme 允许 cond 子句的一种额外语法:(<测试> => <接收者>)。如果 <测试> 求值为真值,则求值 <接收者>。其值必须是一个单参数过程;然后该过程被调用在 <测试> 的值上,结果作为 cond 表达式的值返回。例如
(cond ((assoc 'b '((a 1) (b 2))) => cadr)
(else false))
返回 2。 修改 cond 的处理以支持这种扩展语法。
(let ((<var1> <exp1>) ... (<varn> <expn>))
<body>)
等价于
((lambda (<var1> ... <varn>)
<body>)
<exp1>

<expn>)
实现一个语法变换 let->combination,将 let 表达式的求值归约为上述类型的组合式的求值,并在 eval 中添加适当的子句来处理 let 表达式。
练习 4.7. Let* 类似于 let,不同之处在于 let 变量的绑定是从左到右顺序执行的,每个绑定在一个所有前面绑定均可见的环境中完成。例如
(let* ((x 3)
(y (+ x 2))
(z (+ x y 5)))
(* x z))
返回 39。解释 let* 表达式如何重写为一组嵌套的 let 表达式,并编写一个执行此变换的过程 let*->nested-lets。如果我们已经实现了 let(练习 4.6)并想扩展求值器以处理 let*,是否只需在 eval 中添加一个动作如下的子句
(eval (let*->nested-lets exp) env)
就足够了,还是必须显式地将 let* 展开为非派生表达式?
练习 4.8. ``命名 let'' 是 let 的一种变体,其形式为
(let <变量> <绑定> <体>)
<绑定> 和 <体> 与普通 let 相同,只是 <变量> 在 <体> 内被绑定到一个过程,该过程的体是 <体>,参数是 <绑定> 中的变量。因此,可以通过调用名为 <变量> 的过程来重复执行 <体>。例如,迭代的 Fibonacci 过程(第 1.2.2 节)可以使用命名 let 重写如下:
(define (fib n)
(let fib-iter ((a 1)
(b 0)
(count n))
(if (= count 0)
b
(fib-iter (+ a b) a (- count 1)))))
修改练习 4.6 中的 let->combination 以支持命名 let。
练习 4.9. 许多语言支持各种迭代结构,例如 do、for、while 和 until。在 Scheme 中,迭代过程可以用普通过程调用表达,因此特殊的迭代结构在计算能力上没有本质增益。另一方面,这些结构通常很方便。设计一些迭代结构,给出它们使用的例子,并展示如何将它们实现为派生表达式。
练习 4.10. 通过使用数据抽象,我们能够编写一个独立于被求值语言特定语法的 eval 过程。为了说明这一点,通过修改本节中的过程(不改变 eval 或 apply),设计和实现一种 Scheme 的新语法。
除了定义表达式的外部语法之外,求值器的实现还必须定义求值器在程序执行过程中内部操作的数据结构,例如过程和环境的表示,以及真和假的表示。
对于条件表达式,我们接受任何不是显式 false 对象的东西为真。
(define (true? x)
(not (eq? x false)))
(define (false? x)
(eq? x false))
处理基本过程的这些机制将在第 4.1.4 节中进一步描述。
复合过程使用构造器 make-procedure 从参数、过程体和环境构造:
(define (make-procedure parameters body env)
(list 'procedure parameters body env))
(define (compound-procedure? p)
(tagged-list? p 'procedure))
(define (procedure-parameters p) (cadr p))
(define (procedure-body p) (caddr p))
(define (procedure-environment p) (cadddr p))
求值器需要操作环境的各种操作。如第 3.2 节所述,环境是一个框架序列,其中每个框架是一个绑定表,将变量与其对应值关联起来。我们使用以下操作来操作环境:
为了实现这些操作,我们将环境表示为一个框架列表。环境的外围环境是该列表的 cdr。空环境就是空列表。
(define (enclosing-environment env) (cdr env))
(define (first-frame env) (car env))
(define the-empty-environment '())
环境的每个框架表示为一对列表:在该框架中绑定的变量列表和关联的值列表。14
(define (make-frame variables values)
(cons variables values))
(define (frame-variables frame) (car frame))
(define (frame-values frame) (cdr frame))
(define (add-binding-to-frame! var val frame)
(set-car! frame (cons var (car frame)))
(set-cdr! frame (cons val (cdr frame))))
为了用一个将变量与值关联起来的新框架扩展环境,我们创建一个由变量列表和值列表组成的框架,并将其附加到环境中。如果变量数量与值数量不匹配,我们发出错误信号。
(define (extend-environment vars vals base-env)
(if (= (length vars) (length vals))
(cons (make-frame vars vals) base-env)
(if (< (length vars) (length vals))
(error "Too many arguments supplied" vars vals)
(error "Too few arguments supplied" vars vals))))
为了在环境中查找变量,我们扫描第一个框架中的变量列表。如果找到所需的变量,我们返回值列表中的对应元素。如果在当前框架中未找到该变量,我们搜索外围环境,依此类推。如果到达空环境,我们发出``未绑定变量''错误。
(define (lookup-variable-value var env)
(define (env-loop env)
(define (scan vars vals)
(cond ((null? vars)
(env-loop (enclosing-environment env)))
((eq? var (car vars))
(car vals))
(else (scan (cdr vars) (cdr vals)))))
(if (eq? env the-empty-environment)
(error "Unbound variable" var)
(let ((frame (first-frame env)))
(scan (frame-variables frame)
(frame-values frame)))))
(env-loop env))
为了在指定环境中将变量设置为新值,我们扫描该变量,就像在 lookup-variable-value 中一样,并在找到时更改相应的值。
(define (set-variable-value! var val env)
(define (env-loop env)
(define (scan vars vals)
(cond ((null? vars)
(env-loop (enclosing-environment env)))
((eq? var (car vars))
(set-car! vals val))
(else (scan (cdr vars) (cdr vals)))))
(if (eq? env the-empty-environment)
(error "Unbound variable -- SET!" var)
(let ((frame (first-frame env)))
(scan (frame-variables frame)
(frame-values frame)))))
(env-loop env))
为了定义变量,我们在第一个框架中搜索该变量的绑定,如果存在则更改该绑定(就像在 set-variable-value! 中一样)。如果不存在这样的绑定,我们就在第一个框架中添加一个。
(define (define-variable! var val env)
(let ((frame (first-frame env)))
(define (scan vars vals)
(cond ((null? vars)
(add-binding-to-frame! var val frame))
((eq? var (car vars))
(set-car! vals val))
(else (scan (cdr vars) (cdr vals)))))
(scan (frame-variables frame)
(frame-values frame))))
这里描述的方法只是许多可能的环境表示方式之一。由于我们使用数据抽象将求值器的其余部分与表示的具体选择隔离开来,如果我们愿意,可以改变环境表示。(见练习 4.11。)在生产质量的 Lisp 系统中,求值器环境操作的速度——特别是变量查找——对系统的性能有重大影响。这里描述的表示虽然在概念上简单,但效率不高,通常不会在生产系统中使用。15
练习 4.11. 不将框架表示为一对列表,我们可以将框架表示为绑定列表,其中每个绑定是一个名称-值对。重写环境操作以使用这种替代表示。
练习 4.12. 过程 set-variable-value!、define-variable! 和 lookup-variable-value 可以用更抽象的遍历环境结构的过程来表达。定义捕获这些公共模式的抽象,并基于这些抽象重新定义这三个过程。
练习 4.13. Scheme 允许我们通过 define 为变量创建新绑定,但没有提供去除绑定的方法。为求值器实现一个特殊形式 make-unbound!,它从求值 make-unbound! 表达式的环境中移除给定符号的绑定。这个问题没有完全规定。例如,我们是否只移除环境第一个框架中的绑定?完善这个规范并证明你所做的任何选择的合理性。
有了求值器,我们手中就有了一个用 Lisp 描述的 Lisp 表达式求值过程的描述。将求值器表达为程序的一个优点是我们可以运行该程序。这给我们提供了一个在 Lisp 内部运行的模型,展示 Lisp 本身如何求值表达式。这可以作为实验求值规则的框架,正如我们在本章后面将要做的。
我们的求值器程序最终将表达式归约为基本过程的应用。因此,运行求值器所需的全部就是创建一个机制,调用底层的 Lisp 系统来模拟基本过程的应用。
每个基本过程名必须有一个绑定,这样当 eval 求值一个基本过程应用的运算符时,它会找到一个要传递给 apply 的对象。因此我们设置一个全局环境,将唯一的对象与可能出现在我们将要求值的表达式中的基本过程名称关联起来。全局环境还包含符号 true 和 false 的绑定,以便它们可以在要求值的表达式中用作变量。
(define (setup-environment)
(let ((initial-env
(extend-environment (primitive-procedure-names)
(primitive-procedure-objects)
the-empty-environment)))
(define-variable! 'true true initial-env)
(define-variable! 'false false initial-env)
initial-env))
(define the-global-environment (setup-environment))
我们如何表示基本过程对象并不重要,只要 apply 能够通过过程 primitive-procedure? 和 apply-primitive-procedure 识别和应用它们即可。我们选择将基本过程表示为以符号 primitive 开头、包含底层 Lisp 中实现该基本过程的一个过程的列表。
(define (primitive-procedure? proc)
(tagged-list? proc 'primitive))
(define (primitive-implementation proc) (cadr proc))
Setup-environment 将从列表中获取基本名称和实现过程:16
(define primitive-procedures
(list (list 'car car)
(list 'cdr cdr)
(list 'cons cons)
(list 'null? null?)
<more primitives>
))
(define (primitive-procedure-names)
(map car
primitive-procedures))
(define (primitive-procedure-objects)
(map (lambda (proc) (list 'primitive (cadr proc)))
primitive-procedures))
要应用一个基本过程,我们只需使用底层 Lisp 系统将实现过程应用于参数:17
(define (apply-primitive-procedure proc args)
(apply-in-underlying-scheme
(primitive-implementation proc) args))
为了方便运行元循环求值器,我们提供了一个驱动循环,它模拟底层 Lisp 系统的读取-求值-打印循环。它打印一个提示符,读取输入表达式,在全局环境中求值该表达式,并打印结果。我们在每个打印的结果前加上一个输出提示符,以将表达式的值与可能打印的其他输出区分开来。18
(define input-prompt ";;; M-Eval input:")
(define output-prompt ";;; M-Eval value:")
(define (driver-loop)
(prompt-for-input input-prompt)
(let ((input (read)))
(let ((output (eval input the-global-environment)))
(announce-output output-prompt)
(user-print output)))
(driver-loop))
(define (prompt-for-input string)
(newline) (newline) (display string) (newline))
(define (announce-output string)
(newline) (display string) (newline))
我们使用一个特殊的打印过程 user-print,以避免打印复合过程的环境部分,它可能是一个很长的列表(甚至可能包含循环)。
(define (user-print object)
(if (compound-procedure? object)
(display (list 'compound-procedure
(procedure-parameters object)
(procedure-body object)
'<procedure-env>))
(display object)))
现在运行求值器所需的全部就是初始化全局环境并启动驱动循环。以下是一个示例交互:
(define the-global-environment (setup-environment))
(driver-loop)
;;; M-Eval input:
(define (append x y)
(if (null? x)
y
(cons (car x)
(append (cdr x) y))))
;;; M-Eval value:
ok
;;; M-Eval input:
(append '(a b c) '(d e f))
;;; M-Eval value:
(a b c d e f)
练习 4.14. Eva Lu Ator 和 Louis Reasoner 各自在实验元循环求值器。Eva 键入了 map 的定义,并运行了一些使用它的测试程序。它们运行良好。相比之下,Louis 将系统版本的 map 作为基本过程安装到了元循环求值器中。当他尝试时,情况变得非常糟糕。解释为什么 Louis 的 map 失败了,而 Eva 的却能正常工作。
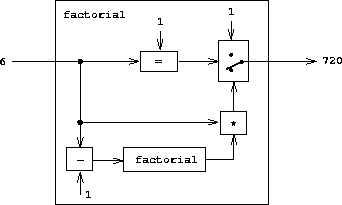
在思考一个求值 Lisp 表达式的 Lisp 程序时,一个类比可能会有所帮助。程序含义的一种操作性观点是:程序是对一个抽象(可能是无穷大的)机器的描述。例如,考虑熟悉的计算阶乘的程序:
(define (factorial n)
(if (= n 1)
1
(* (factorial (- n 1)) n)))
我们可以将这个程序视为一个机器的描述,该机器包含执行递减、乘法和相等测试的部件,以及一个两位开关和另一个阶乘机器。(这个阶乘机器是无穷的,因为它内部包含另一个阶乘机器。)图 4.2 是阶乘机器的流图,展示了各个部件是如何连接在一起的。
|
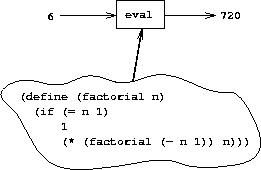
类似地,我们可以将求值器视为一台非常特殊的机器,它以机器描述为输入。给定这个输入,求值器配置自身来模拟所描述的机器。例如,如果我们向求值器提供 factorial 的定义,如图 4.3 所示,求值器将能够计算阶乘。
|
从这个角度来看,我们的求值器被视为一个通用机器。当其他机器被描述为 Lisp 程序时,它可以模拟它们。19 这是引人注目的。试着想象一个用于电路的类似的求值器。这将是一个以编码了某个其他电路(如滤波器)方案的信号为输入的电路。给定这个输入,电路求值器将表现得像具有相同描述的滤波器。这样的通用电路几乎复杂到难以想象。程序求值器是一个相当简单的程序,这真是令人惊叹。20
求值器的另一个引人注目的方面是,它充当了编程语言操作的数据对象与编程语言本身之间的桥梁。想象一下,求值器程序(用 Lisp 实现)正在运行,用户正在向求值器输入表达式并观察结果。从用户的角度来看,像 (* x x) 这样的输入表达式是编程语言中的一个表达式,求值器应该执行它。然而,从求值器的角度来看,该表达式只是一个列表(在这个例子中,是一个包含三个符号 *、x 和 x 的列表),将按照一组明确定义的规则进行操作。
用户的程序就是求值器的数据这一事实不应成为混淆的来源。实际上,有时忽略这种区别是方便的,并赋予用户通过在程序中使用 eval 来显式地求值一个 数据对象作为 Lisp 表达式的能力。许多 Lisp 方言提供了一个基本过程 eval,它以表达式和环境为参数,并在该环境中求值表达式。21 因此,
(eval '(* 5 5) user-initial-environment)
和
(eval (cons '* (list 5 5)) user-initial-environment)
都将返回 25。22
练习 4.15. 给定一个单参数过程 p 和一个对象 a,如果求值表达式 (p a) 返回一个值(而不是以错误信息终止或永远运行),则称 p 在 a 上``停机''。证明不可能编写一个过程 halts?,对于任何过程 p 和对象 a,都能正确判断 p 是否在 a 上停机。使用以下推理:如果你有这样的过程 halts?,你可以实现以下程序:
(define (run-forever) (run-forever))
(define (try p)
(if (halts? p p)
(run-forever)
'halted))
现在考虑求值表达式 (try try),并展示任何可能的结果(停机或永远运行)都违反了 halts? 的预期行为。23
我们的环境求值模型和元循环求值器按顺序执行定义,一次将一个定义的扩展添加到环境框架中。这对于交互式程序开发特别方便,程序员需要自由地混合过程的应用和新过程的定义。然而,如果我们仔细思考用于实现块结构(在第 1.1.8 节中引入)的内部定义,我们会发现逐名称扩展环境可能不是定义局部变量的最佳方式。
考虑一个带有内部定义的过程,例如
(define (f x)
(define (even? n)
(if (= n 0)
true
(odd? (- n 1))))
(define (odd? n)
(if (= n 0)
false
(even? (- n 1))))
<rest of body of f>)
我们这里的意图是,过程 even? 体中的名称 odd? 应该引用在 even? 之后定义的过程 odd?。名称 odd? 的作用域是 f 的整个体,而不仅仅是 f 的体中从 odd? 的 define 出现之处开始的部分。实际上,当我们考虑到 odd? 本身是根据 even? 定义的——因此 even? 和 odd? 是互递归过程——我们看到对这两个 define 的唯一令人满意的解释是将它们视为名称 even? 和 odd? 被同时添加到环境中。更一般地,在块结构中,局部名称的作用域是求值 define 的整个过程体。
碰巧的是,我们的解释器会正确地求值对 f 的调用,但这是出于一个``偶然的''原因:由于内部过程的定义在前面,对这些过程的调用要等到它们都被定义之后才会被求值。因此,在 even? 执行时,odd? 已经被定义。事实上,我们的顺序求值机制与直接实现同时定义的机制会给出相同的结果,只要过程中内部定义出现在体的前面,且被定义变量的值表达式的求值并不实际使用任何被定义的变量。(关于不遵守这些限制的过程的例子,请见练习 4.19。)24
然而,有一种简单的方法来处理定义,使内部定义的名称具有真正的同时作用域——只需在求值任何值表达式之前创建所有将在当前环境中的局部变量。一种方法是通过对 lambda 表达式的语法变换来实现。在求值 lambda 表达式的体之前,我们``扫描出''并消除体中所有的内部定义。内部定义的变量将用 let 创建,然后通过赋值设置其值。例如,过程
(lambda <vars>
(define u <e1>)
(define v <e2>)
<e3>)
would be transformed into
(lambda <vars>
(let ((u '*unassigned*)
(v '*unassigned*))
(set! u <e1>)
(set! v <e2>)
<e3>))
其中 *unassigned* 是一个特殊符号,如果尝试使用尚未赋值的变量的值,则会导致查找该变量时发出错误信号。
练习 4.18 中展示了一种扫描出内部定义的替代策略。与上面展示的变换不同,这种策略强制要求被定义变量的值可以在不使用任何变量值的情况下求值。25
练习 4.16. 在这个练习中,我们实现刚刚描述的用于解释内部定义的方法。我们假设求值器支持 let(见练习 4.6)。
a. 修改 lookup-variable-value(第 4.1.3 节),如果它找到的值是符号 *unassigned*,则发出错误信号。
b. 编写一个过程 scan-out-defines,它接受一个过程体,并通过进行上述变换返回一个没有内部定义的等价体。
c. 将 scan-out-defines 安装到解释器中,可以在 make-procedure 中或在 procedure-body 中(见第 4.1.3 节)。哪个位置更好?为什么?
练习 4.17. 画出求值文中过程里的表达式 <e3> 时生效的环境图,比较当定义按顺序解释时与按描述扫描出定义时,环境结构会如何不同。为什么变换后的程序中会多出一个框架?解释为什么这种环境结构的差异永远不会影响正确程序的行为。设计一种方法,使解释器在不构造额外框架的情况下实现内部定义的``同时''作用域规则。
练习 4.18. 考虑一种扫描出定义的替代策略,它将文中的例子翻译为
(lambda <vars>
(let ((u '*unassigned*)
(v '*unassigned*))
(let ((a <e1>)
(b <e2>))
(set! u a)
(set! v b))
<e3>))
这里 a 和 b 意在表示由解释器创建的新变量名,它们不会出现在用户的程序中。考虑来自第 3.5.4 节的 solve 过程:
(define (solve f y0 dt)
(define y (integral (delay dy) y0 dt))
(define dy (stream-map f y))
y)
如果内部定义按本练习所示的方式扫描出,这个过程能工作吗?如果按文中所示的方式扫描出呢?请解释。
练习 4.19. Ben Bitdiddle、Alyssa P. Hacker 和 Eva Lu Ator 正在争论求值以下表达式的期望结果:
(let ((a 1))
(define (f x)
(define b (+ a x))
(define a 5)
(+ a b))
(f 10))
Ben 断言结果应使用 define 的顺序规则得到:b 定义为 11,然后 a 定义为 5,因此结果是 16。Alyssa 反对说,互递归要求内部过程定义的同时作用域规则,并且将过程名与其他名称区别对待是不合理的。因此,她主张采用练习 4.16 中实现的机制。这将导致在计算 b 的值时 a 是未赋值的。因此,在 Alyssa 看来,该过程应产生一个错误。Eva 有第三种意见。她说,如果 a 和 b 的定义真正是同时的,那么在求值 b 时应该使用 a 的值 5。因此,在 Eva 看来,a 应为 5,b 应为 15,结果应为 20。你支持这些观点中的哪一个(如果有的话)?你能设计一种实现内部定义的方法,使其按照 Eva 偏好的方式运行吗?26
练习 4.20. 因为内部定义看起来是顺序的,但实际上是同时的,有些人倾向于完全避免使用它们,而使用特殊形式 letrec。Letrec 看起来像 let,因此它绑定的变量是同时绑定的且具有相同的作用域,这并不令人惊讶。上面示例过程 f 可以不使用内部定义而写成完全相同的意思:
(define (f x)
(letrec ((even?
(lambda (n)
(if (= n 0)
true
(odd? (- n 1)))))
(odd?
(lambda (n)
(if (= n 0)
false
(even? (- n 1))))))
<rest of body of f>))
Letrec 表达式的形式为
(letrec ((<var1> <exp1>) ... (<varn> <expn>))
<body>)
是 let 的一种变体,其中为变量 <vark> 提供初始值的表达式 <expk> 在包含所有 letrec 绑定的环境中求值。这允许绑定中的递归,例如上面例子中 even? 和 odd? 的互递归,或者用以下方式求值 10 的阶乘:
(letrec ((fact
(lambda (n)
(if (= n 1)
1
(* n (fact (- n 1)))))))
(fact 10))
a. 通过将 letrec 表达式转换为 let 表达式(如上面正文或练习 4.18 所示),将 letrec 实现为派生表达式。也就是说,letrec 变量应该用 let 创建,然后通过 set! 赋值它们的值。
b. Louis Reasoner 对内部定义的这些繁琐之处感到困惑。在他看来,如果你不喜欢在过程内部使用 define,你可以直接使用 let。通过画出环境图来说明他的推理有什么问题,图中展示当求值表达式 (f 5) 时,<f 体的其余部分> 在哪种环境中求值,其中 f 如本练习中所定义。画出相同求值过程的环境图,但在 f 的定义中用 let 代替 letrec。
练习 4.21. 令人惊讶的是,Louis 在练习 4.20 中的直觉是正确的。确实可以在不使用 letrec(甚至 define)的情况下指定递归过程,尽管实现这一目标的方法比 Louis 想象的要微妙得多。以下表达式通过应用一个递归的 阶乘过程来计算 10 的阶乘:27
((lambda (n)
((lambda (fact)
(fact fact n))
(lambda (ft k)
(if (= k 1)
1
(* k (ft ft (- k 1)))))))
10)
a. 检查(通过求值该表达式)这确实计算了阶乘。设计一个用于计算 Fibonacci 数的类似表达式。
b. 考虑以下过程,它包含互递归的内部定义:
(define (f x)
(define (even? n)
(if (= n 0)
true
(odd? (- n 1))))
(define (odd? n)
(if (= n 0)
false
(even? (- n 1))))
(even? x))
填入缺失的表达式以完成 f 的替代定义,该定义既不使用内部定义也不使用 letrec:
(define (f x)
((lambda (even? odd?)
(even? even? odd? x))
(lambda (ev? od? n)
(if (= n 0) true (od? <??> <??> <??>)))
(lambda (ev? od? n)
(if (= n 0) false (ev? <??> <??> <??>)))))
上面实现的求值器很简单,但效率非常低,因为表达式的语法分析与它们的执行交织在一起。因此,如果一个程序被执行多次,其语法就被分析多次。例如,考虑使用以下 factorial 定义来求值 (factorial 4):
(define (factorial n)
(if (= n 1)
1
(* (factorial (- n 1)) n)))
每次调用 factorial 时,求值器必须确定体是一个 if 表达式并提取谓词。只有在那之后才能求值谓词并根据其值进行分派。每次求值表达式 (* (factorial (- n 1)) n),或子表达式 (factorial (- n 1)) 和 (- n 1) 时,求值器都必须在 eval 中执行案例分析以确定表达式是一个应用,并提取其运算符和运算对象。这种分析代价高昂。重复执行它是浪费的。
我们可以通过安排使得语法分析只执行一次来显著提高求值器的效率。28我们将接收表达式和环境的 eval 分成两部分。过程 analyze 只接收表达式。它执行语法分析并返回一个新的过程——执行过程——它封装了执行被分析表达式所需的工作。执行过程以环境为参数并完成求值。这节省了工作,因为 analyze 对每个表达式只调用一次,而执行过程可能被调用多次。
With the separation into analysis and execution, eval now becomes
(define (eval exp env)
((analyze exp) env))
The result of calling analyze is the execution procedure to be applied to the environment. The analyze procedure is the same case analysis as performed by the original eval of section 4.1.1, except that the procedures to which we dispatch perform only analysis, not full evaluation:
(define (analyze exp)
(cond ((self-evaluating? exp)
(analyze-self-evaluating exp))
((quoted? exp) (analyze-quoted exp))
((variable? exp) (analyze-variable exp))
((assignment? exp) (analyze-assignment exp))
((definition? exp) (analyze-definition exp))
((if? exp) (analyze-if exp))
((lambda? exp) (analyze-lambda exp))
((begin? exp) (analyze-sequence (begin-actions exp)))
((cond? exp) (analyze (cond->if exp)))
((application? exp) (analyze-application exp))
(else
(error "Unknown expression type -- ANALYZE" exp))))
这是最简单的语法分析过程,它处理自求值表达式。它返回一个忽略环境参数并直接返回表达式的执行过程:
(define (analyze-self-evaluating exp)
(lambda (env) exp))
对于 quoted 表达式,我们可以通过仅在分析阶段提取引用的文本一次来获得一点效率提升,而不是在执行阶段提取。
(define (analyze-quoted exp)
(let ((qval (text-of-quotation exp)))
(lambda (env) qval)))
查找变量值仍必须在执行阶段完成,因为这依赖于了解环境。29
(define (analyze-variable exp)
(lambda (env) (lookup-variable-value exp env)))
Analyze-assignment 也必须将实际设置变量推迟到执行时(即提供了环境之后)。然而,assignment-value 表达式可以在分析期间(递归地)被分析,这一事实是效率上的一个主要提升,因为 assignment-value 表达式现在将只被分析一次。对于定义也是如此。
(define (analyze-assignment exp)
(let ((var (assignment-variable exp))
(vproc (analyze (assignment-value exp))))
(lambda (env)
(set-variable-value! var (vproc env) env)
'ok)))
(define (analyze-definition exp)
(let ((var (definition-variable exp))
(vproc (analyze (definition-value exp))))
(lambda (env)
(define-variable! var (vproc env) env)
'ok)))
对于 if 表达式,我们在分析时提取并分析谓词、consequent 和 alternative。
(define (analyze-if exp)
(let ((pproc (analyze (if-predicate exp)))
(cproc (analyze (if-consequent exp)))
(aproc (analyze (if-alternative exp))))
(lambda (env)
(if (true? (pproc env))
(cproc env)
(aproc env)))))
分析 lambda 表达式也带来了效率上的主要提升:我们只分析一次 lambda 体,即使求值 lambda 所得到的过程可能被多次应用。
(define (analyze-lambda exp)
(let ((vars (lambda-parameters exp))
(bproc (analyze-sequence (lambda-body exp))))
(lambda (env) (make-procedure vars bproc env))))
对表达式序列的分析(例如在 begin 或 lambda 表达式的体中)更加复杂。30 分析序列中的每个表达式,产生一个执行过程。这些执行过程被组合起来产生一个执行过程,该过程以环境为参数,并顺序调用每个单独的执行过程,以环境为参数。
(define (analyze-sequence exps)
(define (sequentially proc1 proc2)
(lambda (env) (proc1 env) (proc2 env)))
(define (loop first-proc rest-procs)
(if (null? rest-procs)
first-proc
(loop (sequentially first-proc (car rest-procs))
(cdr rest-procs))))
(let ((procs (map analyze exps)))
(if (null? procs)
(error "Empty sequence -- ANALYZE"))
(loop (car procs) (cdr procs))))
为了分析一个应用,我们分析运算符和运算对象,并构造一个执行过程,该过程调用运算符执行过程(以获取要应用的实际过程)和运算对象执行过程(以获取实际参数)。然后我们将这些传递给 execute-application,它是第 4.1.1 节中 apply 的类比。Execute-application 与 apply 的不同之处在于,复合过程的过程体已经被分析,因此无需进一步分析。相反,我们只需在扩展的环境上调用体的执行过程。
(define (analyze-application exp)
(let ((fproc (analyze (operator exp)))
(aprocs (map analyze (operands exp))))
(lambda (env)
(execute-application (fproc env)
(map (lambda (aproc) (aproc env))
aprocs)))))
(define (execute-application proc args)
(cond ((primitive-procedure? proc)
(apply-primitive-procedure proc args))
((compound-procedure? proc)
((procedure-body proc)
(extend-environment (procedure-parameters proc)
args
(procedure-environment proc))))
(else
(error
"Unknown procedure type -- EXECUTE-APPLICATION"
proc))))
我们的新求值器使用与第 4.1.2、4.1.3 和 4.1.4 节中相同的数据结构、语法过程和运行时支持过程。
练习 4.22. 扩展本节中的求值器以支持特殊形式 let。(见练习 4.6。)
练习 4.23. Alyssa P. Hacker 不明白为什么 analyze-sequence 需要如此复杂。所有其他分析过程都是第 4.1.1 节中相应求值过程(或 eval 子句)的直接变换。她期望 analyze-sequence 看起来像这样:
(define (analyze-sequence exps)
(define (execute-sequence procs env)
(cond ((null? (cdr procs)) ((car procs) env))
(else ((car procs) env)
(execute-sequence (cdr procs) env))))
(let ((procs (map analyze exps)))
(if (null? procs)
(error "Empty sequence -- ANALYZE"))
(lambda (env) (execute-sequence procs env))))
Eva Lu Ator 向 Alyssa 解释说,文中的版本在分析时完成了更多的序列求值工作。Alyssa 的序列执行过程,不是将调用各个执行过程的调用内建进去,而是循环遍历这些过程来调用它们:实际上,虽然序列中的各个表达式已被分析,但序列本身并未被分析。
比较 analyze-sequence 的两个版本。例如,考虑常见情况(典型的过程体),其中序列只有一个表达式。Alyssa 的程序生成的执行过程会做哪些工作?上面文中的程序生成的执行过程呢?对于一个有两个表达式的序列,这两个版本如何比较?
练习 4.24. 设计并执行一些实验,比较原始元循环求值器与本节中版本的速度。使用你的结果来估计对于各种过程,分析所花费的时间与执行所花费的时间的比例。
3 即便如此,求值过程的一些重要方面仍不会被我们的求值器阐明。其中最重要的是过程调用其他过程并返回值给调用者的详细机制。我们将在第 5 章中处理这些问题,在那里通过将求值器实现为简单的寄存器机器来更仔细地审视求值过程。
4 如果我们允许自己能够应用基本过程,那么求值器中还有什么需要我们实现?求值器的工作不是指定语言的基本过程,而是提供连接组织——组合的方法和抽象的方法——将一组基本过程绑定在一起形成一种语言。具体来说:
5 我们本可以通过使用 map(并规定 operands 返回一个列表)来简化 eval 中的 application? 子句,而不是编写显式的 list-of-values 过程。我们选择在这里不使用 map,是为了强调这样一个事实:求值器可以在完全不使用高阶过程的情况下实现(因此可以用一种没有高阶过程的语言编写),即使它支持的语言将包含高阶过程。
6 在这种情况下,被实现的语言和实现语言是相同的。在此思考 true? 的含义,无需借助药物即可扩展意识。
7 这个 define 的实现忽略了处理内部定义中的一个微妙问题,不过它在大多数情况下都能正确工作。我们将在第 4.1.6 节中看到这个问题是什么以及如何解决它。
8 正如我们在引入 define 和 set! 时所说,这些值在 Scheme 中是依赖于实现的——也就是说,实现者可以选择返回什么值。
9 如第 2.3.1 节所述,求值器将 quoted 表达式视为以 quote 开头的列表,即使表达式是用引号键输入的。例如,表达式 'a 会被求值器视为 (quote a)。见练习 2.55。
10 在 Scheme 中,当 if 表达式的谓词为假且没有 alternative 时,其值未指定;我们在此选择使其为 false。我们将通过在全局环境中绑定 true 和 false,来支持在要表达的求值式中使用变量 true 和 false。见第 4.1.4 节。
11 这些针对表达式列表的选择器——以及相应的针对运算对象列表的选择器——并非意在作为数据抽象。它们被引入作为基本列表操作的助记名称,以便更容易理解第 5.4 节中的显式控制求值器。
12 在 Scheme 中,当所有谓词都为假且没有 else 子句时,cond 表达式的值未指定;我们在此选择使其为 false。
13 实际的 Lisp 系统提供了一种机制,允许用户添加新的派生表达式,并将其实现指定为语法变换,而无需修改求值器。这种用户定义的变换称为宏。虽然添加一个定义宏的基本机制很容易,但得到的语言存在微妙的名称冲突问题。对于不会导致这些困难的宏定义机制,已经有了大量研究。参见,例如 Kohlbecker 1986、Clinger and Rees 1991 以及 Hanson 1991。
14 在以下代码中,框架并非真正的数据抽象:Set-variable-value! 和 define-variable! 使用 set-car! 直接修改框架中的值。框架过程的目的是使环境操作过程易于阅读。
15 这种表示的缺点(以及练习 4.11 中的变体)是,求值器可能需要搜索许多框架才能找到给定变量的绑定。(这种方法被称为深绑定。)避免这种低效的一种方法是使用称为词法寻址的策略,这将在第 5.5.6 节中讨论。
16 任何在底层 Lisp 中定义的过程都可以用作元循环求值器的基本过程。安装在求值器中的基本过程的名称不必与其在底层 Lisp 中的实现名称相同;这里名称相同是因为元循环求值器实现的正是 Scheme 本身。因此,例如,我们可以在 primitive-procedures 列表中放入 (list 'first car) 或 (list 'square (lambda (x) (* x x)))。
17 Apply-in-underlying-scheme 是我们在前面章节中使用过的 apply 过程。元循环求值器的 apply 过程(第 4.1.1 节)模拟了这个基本过程的工作。有两个不同的东西都叫 apply 会导致运行元循环求值器时出现技术问题,因为定义元循环求值器的 apply 会掩盖基本过程的定义。解决这个问题的一种方法是重命名元循环的 apply 以避免与基本过程名冲突。我们改为假设在定义元循环 apply 之前通过执行以下操作保存了底层 apply 的引用:
(define apply-in-underlying-scheme apply)
这使我们能够在不同名称下访问 apply 的原始版本。
18 基本过程 read 等待用户输入,并返回键入的下一个完整表达式。例如,如果用户键入 (+ 23 x),read 返回一个三元素列表,包含符号 +、数字 23 和符号 x。如果用户键入 'x,read 返回一个两元素列表,包含符号 quote 和符号 x。
19 机器是用 Lisp 描述的这一事实并非本质。如果我们给求值器一个表现为某种其他语言(比如 C)的求值器的 Lisp 程序,那么 Lisp 求值器将模拟 C 求值器,而 C 求值器又可以模拟任何描述为 C 程序的机器。类似地,用 C 编写一个 Lisp 求值器会产生一个可以执行任何 Lisp 程序的 C 程序。这里的深层思想是,任何求值器都可以模拟任何其他求值器。因此,``原则上能计算什么''(忽略所需时间和实际的内存问题)的概念独立于语言或计算机,而是反映了 可计算性的底层概念。这一点首先由 Alan M. Turing(1912-1954)清晰地展示,他 1936 年的论文奠定了理论 计算机科学的基础。在那篇论文中,Turing 提出了一个简单的计算模型——现在称为 图灵机——并论证任何``有效过程''都可以表述为这种机器的一个程序。(这个论证被称为 Church-Turing 论题。)Turing 随后实现了一个通用机器,即一个行为类似于图灵机程序求值器的图灵机。他用这个框架证明了存在图灵机无法计算的良定问题(见练习 4.15),因此也就不能被表述为``有效过程''。Turing 还在实用计算机科学方面做出了基础性贡献。例如,他发明了使用通用子程序来组织程序的想法。关于 Turing 的传记,参见 Hodges 1983。
20 有些人觉得一个由相对简单的过程实现的求值器能够模拟比自身更复杂的程序,这与直觉相悖。通用求值器机器的存在是计算的深刻而奇妙的性质。递归论是数理逻辑的一个分支,关注计算的逻辑极限。Douglas Hofstadter 的优美著作《Gödel, Escher, Bach》(1979)探索了其中的一些思想。
21 警告:这个 eval 基本过程与我们第 4.1.1 节中实现的 eval 过程并不相同,因为它使用的是实际的 Scheme 环境,而不是我们在第 4.1.3 节中构建的示例环境结构。这些实际环境不能由用户作为普通列表进行操作;必须通过 eval 或其他特殊操作来访问。类似地,我们之前看到的 apply 基本过程也与元循环的 apply 不同,因为它使用的是实际的 Scheme 过程,而不是我们在第 4.1.3 和 4.1.4 节中构造的过程对象。
22 MIT 的 Scheme 实现包括 eval,以及一个符号 user-initial-environment,它被绑定到用户输入表达式被求值的初始环境。
23 虽然我们规定 halts? 接收一个过程对象,但请注意,即使 halts? 可以访问过程的文本及其环境,这个推理仍然适用。这就是 Turing 著名的停机定理,它首次给出了一个不可计算问题的清晰例子,即一个良定的任务无法作为计算过程执行。
24 希望程序不依赖于这种求值机制,正是第 1 章脚注 28 中``管理层不负责''说法的原因。通过坚持内部定义在前面且在求值这些定义时不互相使用,Scheme 的 IEEE 标准为实现在用于求值这些定义的机制上留下了一些选择空间。在此选择一种求值规则而非另一种可能看起来只是一个小问题,只影响``格式错误''程序的解释。然而,我们将在第 5.5.6 节中看到,转向内部定义的同时作用域模型避免了在实现编译器时会出现的一些棘手困难。
25 Scheme 的 IEEE 标准允许不同的实现策略,它规定由程序员负责遵守此限制,而非由实现来强制执行。包括 MIT Scheme 在内的一些 Scheme 实现使用上面展示的变换。因此,一些不遵守此限制的程序实际上在这种实现中是可以运行的。
26 MIT Scheme 的实现者基于以下理由支持 Alyssa:Eva 在原则上是正确的——定义应被视为同时的。但是实现 Eva 所要求的一个通用的高效机制似乎是困难的。在没有这种机制的情况下,在同时定义的困难情况下产生错误(Alyssa 的观点)比产生不正确的答案(如 Ben 所主张的)更好。
27 这个例子说明了一种不使用 define 来表述递归过程的编程技巧。这类技巧中最通用的是 Y 算子,它可以用于给出递归的``纯 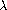 -演算''实现。(关于 lambda 演算的细节参见 Stoy 1977,关于 Scheme 中 Y 算子的阐述参见 Gabriel 1988。)
-演算''实现。(关于 lambda 演算的细节参见 Stoy 1977,关于 Scheme 中 Y 算子的阐述参见 Gabriel 1988。)
28 这种技术是编译过程的一个组成部分,我们将在第 5 章中讨论。Jonathan Rees 在 1982 年左右为 T 项目编写了这样一个 Scheme 解释器(Rees and Adams 1982)。Marc Feeley(1986)(另见 Feeley and Lapalme 1987)在他的硕士论文中独立发明了这种技术。
29 然而,变量搜索的一个重要部分可以作为语法分析的一部分完成。正如我们将在第 5.5.6 节中展示的,可以确定变量值将在环境结构中找到的位置,从而无需扫描环境以寻找与变量匹配的条目。